Imagine you’ve just hired a brilliant polymath who has read nearly every book ever written. They can discuss history, science, and art with astonishing depth. However, on their first day at your specialized law firm, you ask them to draft a precise legal clause. They might struggle. Their vast general knowledge needs to be focused and adapted to the specific language, patterns, and rules of your domain.
This is the exact challenge with powerful, pre-trained Large Language Models (LLMs) like Llama 2 or GPT-3. They are incredible generalists, but to become reliable, high-performing specialists for your unique tasks—be it legal analysis, medical note generation, or brand-specific customer service—they require fine-tuning.
Fine-tuning is the process of continuing the training of a pre-trained model on a smaller, domain-specific dataset. But how you fine-tune has evolved dramatically, leading to critical choices. This guide will demystify the three primary paradigms: Full-Parameter Fine-Tuning, LoRA, and QLoRA, helping you understand their trade-offs and select the right tool for your project.
The Core Goal of Fine-Tuning: From Generalist to Specialist
At its heart, fine-tuning aims to achieve one or more of the following:
- Domain Mastery: Teaching the model the jargon, style, and knowledge of a specific field (e.g., biomedicine, legal code, internal company documentation).
- ️Task Specialization: Optimizing the model for a particular format or function (e.g., following complex instructions, outputting strict JSON, engaging in a specific chat persona).
- Performance Alignment: Improving the model’s reliability, accuracy, and safety on a narrow set of critical tasks.
The evolution of fine-tuning methods is a story of the relentless pursuit of efficiency—achieving these goals while minimizing computational cost, time, and hardware barriers.
Method 1: Full-Parameter Fine-Tuning – The Traditional Powerhouse
This is the original and most straightforward approach. You take the pre-trained model, load it onto powerful GPUs, and run additional training passes on your custom dataset, updating every single parameter (weight) in the neural network.
How it Works:
It’s a continuation of the initial training process, but on a much smaller, targeted dataset. The optimizer adjusts all billions of parameters to minimize loss on your new data.
Use Cases:
- When you have a very large, high-quality domain-specific dataset (millions of examples).
- When the target task differs significantly from the model’s pre-training, requiring fundamental rewiring.
- For creating a definitive, standalone model variant meant for widespread distribution and heavy use (e.g., a code-specific version of a base model).
Trade-offs:
- Pros: Maximum potential performance and flexibility; the model can deeply internalize new patterns.
- Cons: Extremely expensive in terms of GPU memory and time; high risk of catastrophic forgetting (losing general knowledge); requires multiple high-end GPUs (often 4-8 A100s).
Analogy: Sending the polymath back to a full, multi-year university program focused solely on law. Effective but immensely resource-intensive.
Method 2: LoRA (Low-Rank Adaptation) – The Efficiency Revolution
Introduced by Microsoft in 2021, LoRA is a Parameter-Efficient Fine-Tuning (PEFT) method that has become the de facto standard for most practical applications. Its core insight is brilliant: the weight updates a model needs for a new task have a low “intrinsic rank” and can be represented by much smaller matrices.
How It Works
Instead of updating the massive pre-trained weight matrices (e.g., of size 4096×4096), LoRA injects trainable “adapter” layers alongside them. During training, only these tiny adapter matrices (e.g., of size 4096×8 and 8×4096) are updated. The original weights are frozen. For inference, the adapter weights are merged with the frozen base weights.
Use Cases:
- The vast majority of business applications where you need to adapt a model to a specific style, task, or knowledge base.
- Situations with limited data (hundreds to thousands of examples).
- When you need to create multiple specialized versions of a model (e.g., one for summarization, one for Q&A) efficiently, as adapters are small (~1-10% of original model size) and easily swapped.
Trade-offs:
- Pros: Dramatically lower GPU memory usage (enabling fine-tuning of large models on a single GPU), faster training, reduced overfitting risk, and no catastrophic forgetting. Adapters are portable and shareable.
- Cons: Can, in some edge cases, theoretically underperform full fine-tuning given unlimited data and compute. Requires selecting target modules (often attention layers) and rank parameters.
Analogy:
Giving the polymath a concise, targeted legal handbook and a set of specialized quick-reference guides. They keep all their general knowledge but learn to apply it within a new, structured framework.
Method 3: QLoRA (Quantized LoRA) – Democratizing Access
QLoRA, introduced in 2023, pushes the efficiency frontier further. It asks: “What if we could fine-tune a massive model on a single, consumer-grade GPU?” The answer combines LoRA with another key technique: 4-bit Quantization.
How it Works:
First, the pre-trained model is loaded into GPU memory in a 4-bit quantized state (compared to standard 16-bit). This drastically reduces its memory footprint. Then, LoRA adapters are applied and trained in 16-bit precision. A novel “Double Quantization” technique is used to minimize the memory overhead of the quantization constants themselves. Remarkably, the model’s performance is maintained through backpropagation via the 4-bit weights.
Use Cases:
- Research, prototyping, and personal projects with severe hardware constraints.
- Fine-tuning the largest available models (e.g., 70B parameter models) on a single 24GB or 48GB GPU.
- When cost and accessibility are the primary limiting factors.
Trade-offs:
- Pros: Makes previously impossible fine-tuning tasks possible on affordable hardware. Retains the core benefits of LoRA.
- Cons: The quantization process adds slight complexity. There can be a marginal, though often negligible, performance trade-off compared to 16-bit LoRA. Requires libraries that support 4-bit quantization (like
bitsandbytes).
Analogy:
The polymath’s entire library is now stored on a highly efficient, compressed e-reader. They still get the complete legal handbook and quick guides, allowing them to specialize using minimal physical desk space.
Navigating the Trade-offs: A Decision Framework
How do you choose? Follow this decision tree based on your primary constraints:
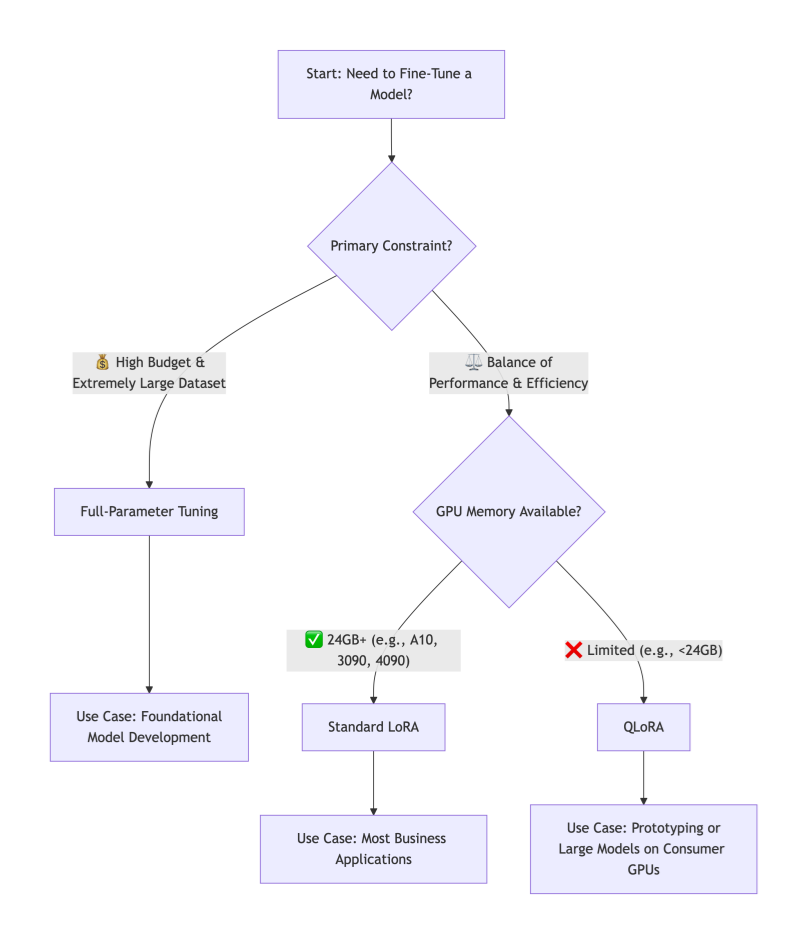
The Verdict:
For over 90% of business, research, and personal applications, LoRA is the recommended starting point. It offers the best balance of performance, efficiency, and practicality. QLoRA is the key when hardware is the absolute bottleneck. Reserve Full-Parameter Fine-Tuning for major initiatives where you are essentially creating a new foundational model and have the corresponding resources.
Taming Complexity: The Need for an Orchestration Platform
While LoRA and QLoRA lower hardware barriers, they introduce new operational complexities: managing different base models, dozens of adapter files, experiment tracking across various ranks and learning rates, and deploying these composite models.
This is where an integrated AI platform like WhaleFlux becomes a strategic force multiplier. WhaleFlux is designed to tame the fine-tuning lifecycle:
Streamlined Experimentation:
It provides a centralized environment to launch, track, and compare hundreds of fine-tuning jobs—whether full-parameter, LoRA, or QLoRA—logging all hyperparameters, metrics, and resulting artifacts.
Adopter & Model Registry:
Instead of a folder full of cryptic .bin files, WhaleFlux acts as a versioned registry for both your base models and your trained adapters. You can easily browse, compare, and promote the best-performing adapters.
Simplified Deployment:
Deploying a LoRA-tuned model is as simple as selecting a base model and an adapter from the registry. WhaleFlux handles the seamless merging and deployment of the optimized model to a scalable inference endpoint, abstracting away the underlying infrastructure complexity.
With WhaleFlux, teams can focus on the art of crafting the perfect dataset and experiment strategy, while the science of orchestration, reproducibility, and scaling is handled reliably.
Conclusion
The fine-tuning landscape has been transformed by LoRA and QLoRA, shifting the question from “Can we afford to fine-tune?” to “How should we fine-tune most effectively?” By understanding the trade-offs between full-parameter tuning, LoRA, and QLoRA, you can align your technical approach with your project’s goals, data, and constraints.
Start with a clear objective, embrace the efficiency of modern PEFT methods, and leverage platforms that operationalize these advanced techniques. This allows you to turn a powerful general-purpose AI into a dedicated, domain-specific expert that delivers tangible value.
FAQs: AI Model Fine-Tuning
1. When should I not use fine-tuning?
Fine-tuning is most valuable when you have a repetitive, well-defined task and a curated dataset. For tasks requiring real-time, external knowledge (e.g., answering questions about recent events), Retrieval-Augmented Generation (RAG) is often better. For simple task guidance, prompt engineering may suffice. The best solutions often combine RAG (for knowledge) with a lightly fine-tuned model (for style and task structure).
2. How much data do I need for LoRA/QLoRA to be effective?
You need significantly less data than for full-parameter tuning. For many style or instruction-following tasks, a few hundred high-quality examples can yield remarkable improvements. For complex domain adaptation, 1,000-10,000 examples are common. The key is data quality and diversity—they must be representative of the task you want the model to master.
3. What are the “rank” and “alpha” parameters in LoRA, and how do I set them?
- Rank (
r): This is the critical dimension of the low-rank adapter matrices. A higher rank means a larger, more expressive adapter (but more parameters to train). Start with a low rank (e.g., 8, 16, 32) and increase only if performance is lacking. - Alpha (
α): This is a scaling parameter for the adapter weights. Think of it as the learning rate for the adapter’s influence. A common and often effective rule of thumb is to setalpha = 2 * rank. Empirical testing on a validation set is the best way to tune these.
4. Can I combine multiple LoRA adapters on one base model?
Yes, this is a powerful advanced technique sometimes called “Adapter Fusion” or “Mixture of Adapters.” You can train separate adapters for different skills (e.g., one for coding syntax, one for medical terminology) and, with the right framework, dynamically combine or select them at inference time. This pushes the model towards being a modular, multi-skilled expert.
5. Does QLoRA sacrifice model quality compared to standard LoRA?
The research (Dettmers et al., 2023) showed that QLoRA, when properly configured, recovers the full 16-bit performance of standard fine-tuning. In practice, any performance difference is often negligible and far outweighed by the accessibility gains. For mission-critical deployments, you can train with QLoRA and then merge the high-quality adapters back into a 16-bit base model for inference if desired.