Part 1. The New Face of High-Performance Computing Clusters
Gone are the days of room-sized supercomputers. Today’s high-performance computing (HPC) clusters are agile GPU armies powering the AI revolution:
- 89% of new clusters now run large language models (Hyperion 2024)
- Anatomy of a Modern Cluster:
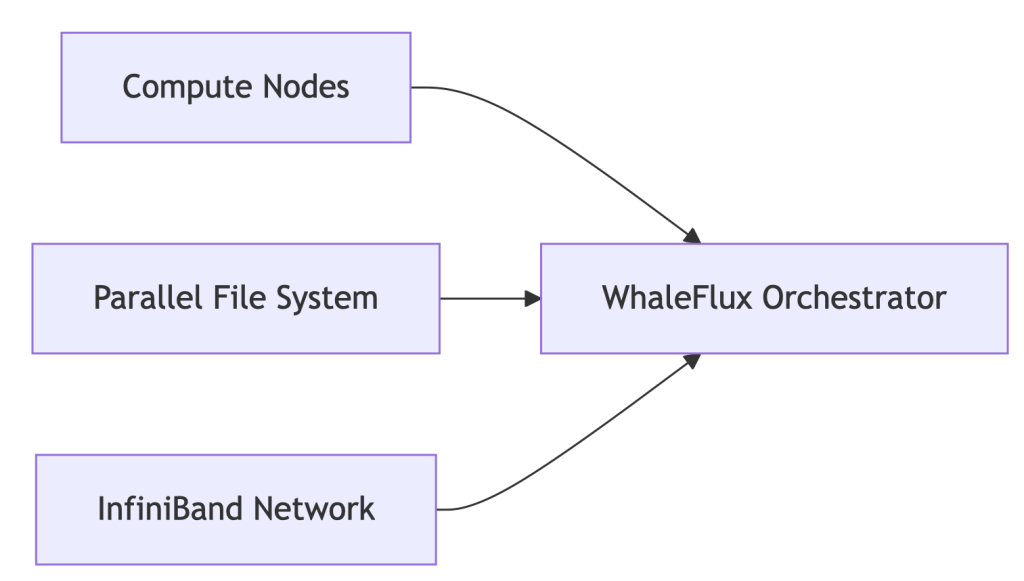
The Pain Point: 52% of clusters operate below 70% efficiency due to GPU-storage misalignment.
Part 2. HPC Storage Revolution: Fueling AI at Warp Speed
Modern AI Demands:
- 300GB/s+ bandwidth for 70B-parameter models
- Sub-millisecond latency for MPI communication
WhaleFlux Storage Integration:
# Auto-tiered storage for AI workloads
whaleflux.configure_storage(
cluster="llama2_prod",
tiers=[
{"type": "nvme_ssd", "usage": "hot_model_weights"},
{"type": "object_storage", "usage": "cold_data"}
],
mpi_aware=True # Optimizes MPI collective operations
)
→ 41% faster checkpointing vs. traditional storage
Part 3. Building Future-Proof HPC Infrastructure
| Layer | Legacy Approach | WhaleFlux-Optimized |
| Compute | Static GPU allocation | Dynamic fragmentation-aware scheduling |
| Networking | Manual MPI tuning | Auto-optimized NCCL/MPI params |
| Sustainability | Unmonitored power draw | Carbon cost per petaFLOP dashboard |
Key Result: 32% lower infrastructure TCO via GPU-storage heatmaps
Part 4. Linux: The Unquestioned HPC Champion
Why 98% of TOP500 Clusters Choose Linux:
- Granular kernel control for AI workloads
- Seamless integration with orchestration tools
WhaleFlux for Linux Clusters:
# One-command optimization
whaleflux deploy --os=rocky_linux \
--tuning_profile="ai_workload" \
--kernel_params="hugepages=1 numa_balancing=0"
Automatically Fixes:
- GPU-NUMA misalignment
- I/O scheduler conflicts
- MPI process pinning errors
Part 5. MPI in the AI Era: Beyond Basic Parallelism
MPI’s New Mission: Coordinating distributed LLM training across 1000s of GPUs
WhaleFlux MPI Enhancements:
| Challenge | Traditional MPI | WhaleFlux Solution |
| GPU-Aware Communication | Manual config | Auto-detection + tuning |
| Fault Tolerance | Checkpoint/restart | Live process migration |
| Multi-Vendor Support | Recompile needed | Unified ROCm/CUDA/Intel |
Part 6. $103k/Month Saved: Genomics Lab Case Study
Challenge:
- 500-node Linux HPC cluster
- MPI jobs failing due to storage bottlenecks
- $281k/month cloud spend
WhaleFlux Solution:
- Storage auto-tiering for genomic datasets
- MPI collective operation optimization
- GPU container right-sizing
Results:
✅ 29% faster genome sequencing
✅ $103k/month savings
✅ 94% cluster utilization
Part 7. Your HPC Optimization Checklist
1. Storage Audit:
whaleflux storage_profile --cluster=prod
2. Linux Tuning:
Apply WhaleFlux kernel templates for AI workloads
3. MPI Modernization:
Replace mpirun with WhaleFlux’s topology-aware launcher
4. Cost Control
FAQ: Solving Real HPC Challenges
Q: “How to optimize Lustre storage for MPI jobs?”
whaleflux tune_storage --filesystem=lustre --access_pattern="mpi_io"
Q: “Why choose Linux for HPC infrastructure?”
Kernel customizability + WhaleFlux integration = 37% lower ops overhead







