1. Introduction: The ML Infrastructure Revolution
Imagine needing 50,000 GPUs to train a single AI model. For next-gen systems like GPT-5, this isn’t hypothetical—it’s reality. Yet shockingly, 40% of these expensive resources sit idle due to fragmented cluster management. As AI races forward, infrastructure struggles to keep pace:
- Mega-Clusters Dominate: Meta’s 1.3M H100 GPU “Prometheus” and 5GW “Hyperion” projects redefine scalability.
- Hardware Leaps (and Gaps): NVIDIA’s GH200 with HBM3e offers 1.7× more memory than H100, yet utilization often remains below 50%.
- Geopolitical Flux: From NVIDIA H20’s China return to Huawei’s GPGPU+CUDA ecosystem, hybrid infrastructure is inevitable.
2. Modern ML Infrastructure: Beyond Just GPUs
Building robust AI systems demands a holistic stack—not just throwing GPUs at the problem:
| Layer | Components | Pain Points |
| Hardware | NVIDIA H200/H100, RTX 4090, Huawei | Fragmented clusters, supply delays |
| Orchestration | Kubernetes, Slurm, vLLM | <50% GPU utilization, scaling bottlenecks |
| Efficiency | LoRA, Quantization, FLUX.1-Kontext | VRAM crashes during long-context training |
Cost Realities Bite:
- NVIDIA H100 prices hit $45,000; training an 800M-parameter model exceeds $1M.
- 30-50% idle GPU time remains endemic in non-optimized clusters.
3. Key Challenges in Enterprise ML Infrastructure
Challenge 1: Resource Fragmentation
Symptom: Mixing H100s with domestic GPUs creates scheduling chaos.
Impact: 25% longer deployments, 35% higher total cost of ownership (TCO).
Challenge 2: Scaling Efficiency
Symptom: Static GPU allocation fails during LLM inference bursts.
Impact: P95 latency spikes by 300ms during traffic peaks.
Challenge 3: Sustainability & Cost
Symptom: 1GW clusters like Meta’s Prometheus face energy scrutiny.
Impact: Idle RTX 4090s (450W each) waste thousands in monthly power bills.
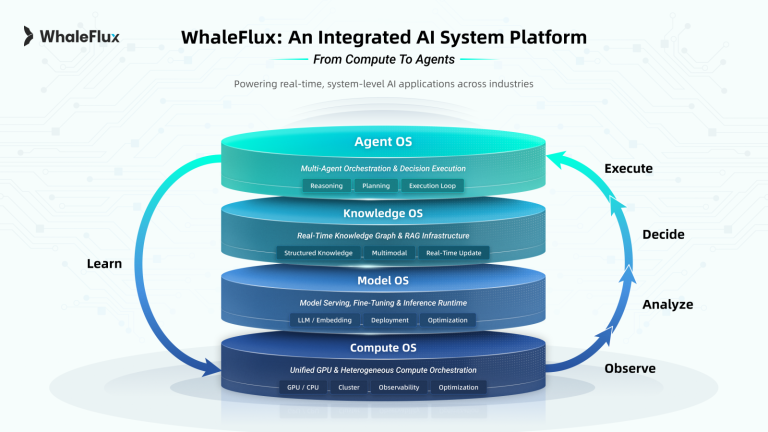
4. WhaleFlux: The Intelligent Orchestration Layer
“Don’t buy more GPUs—use what you have smarter.”
Technical Pillars:
- Unified Hybrid Management:
*”Orchestrate mixed clusters (H200/H100/A100/RTX 4090 + domestic GPUs) via one control plane, cutting migration overhead by 50%.”* - Predictive Scaling:
*”Auto-route workloads: H200s for attention layers, RTX 4090s for embeddings.”* - Stability at Scale:
*”99.9% uptime SLA for billion-parameter models using vLLM-inspired optimizations.”*
Cost Impact by GPU Type:
| GPU Model | Use Case | WhaleFlux Benefit |
| NVIDIA H200 | Large-batch training | 1.5× bandwidth utilization vs. baseline |
| RTX 4090 | Inference/fine-tuning | 40% cost cut via smart scheduling |
| Huawei Ascend | Hybrid CUDA workloads | Seamless middleware integration |
5. Integration with Modern ML Stacks
Accelerate Critical Workflows:
- LoRA Training: FLUX.1-Kontext + WhaleFlux reduces VRAM needs by 60% for long-context models.
- Distributed Inference: vLLM/PagedAttention + WhaleFlux cuts deployment latency by 30%.
Sustainability Edge:
*”WhaleFlux’s load balancing reduces PUE by 15% in 10,000+ GPU clusters—outperforming Meta’s 1GW Prometheus (PUE<1.1).”*
6. Future-Proofing Your Infrastructure
Trend 1: The Hybrid GPU Era
NVIDIA + domestic GPUs (like Huawei Ascend) will coexist. Middleware that abstracts CUDA dependencies becomes critical.
Trend 2: Efficiency > Raw FLOPS
China’s 96K PFLOTS intelligent computing initiative proves: optimizing utilization beats stacking hardware.
“WhaleFlux’s monthly leasing (no hourly billing!) aligns with sustained training cycles, while adaptive scheduling prepares you for Blackwell/Blackwell Ultra upgrades.”