
Enhancing LLM Inference with GPUs: Strategies for Performance and Cost Efficiency
Leo
Jan 17, 2025
blog

Fine-Tuning vs. Pre-Training: How to Choose for Your AI Application
Margarita
Jan 17, 2025
blog

10x Productivity: Unlocking the Real Value of Human-AI Collaborative Workflows
yunxia
Mar 9, 2026
blog

Slashing the ‘AI Tax’: Strategic Moves to Optimize Compute Costs and Performance
Clara
Mar 9, 2026
blog
From Generative AI to Predictive AI: The New Frontier of Decision-Making Intelligence
Margarita
Mar 9, 2026
blog

Beyond the Chatbot: Why 2026 is the Year of Autonomous AI Agents
Leo
Mar 6, 2026
blog

Choosing Your Inference Engine: A Look at TensorRT, Triton and vLLM
Joshua
Feb 2, 2026
blog

Factors to Consider for Selecting the Right AI Model
Leo
Feb 2, 2026
blog

Fine-Tuning 101: How to Customize Pre-Trained Models for Your Business
Leo
Jan 29, 2026
blog
How to Build a Knowledge Base That Your AI Can Actually Use
Joshua
Jan 29, 2026
blog

From Static Docs to AI Answers: How RAG Makes Your Company Knowledge Instantly Searchable
Joshua
Jan 28, 2026
blog

Build Trustworthy AI: The Critical Role of Your Centralized Knowledge Base
Leo
Jan 26, 2026
blog

How RAG Supercharges Your AI with a Live Knowledge Base
Joshua
Jan 26, 2026
blog

Building a “Knowledge Base” It Can Actually Use
Joshua
Jan 22, 2026
blog
WhaleFlux Signals a Shift Toward Architecting Enterprise AI Systems as Enterprise AI Enters a New Phase in 2026
Margarita
Jan 22, 2026
blog

Beyond Generic Answers: Connect ChatGPT to Your Own Knowledge Base
Leo
Jan 21, 2026
blog
RAG Explained Simply: How AI “Looks Up” Answers in Your Documents
Joshua
Jan 21, 2026
blog

From Data to Dialogue: Turning Static Files into an Interactive Knowledge Base with RAG
Leo
Jan 19, 2026
blog

How RAG Supercharges Your AI with a Live Knowledge Base
Leo
Jan 14, 2026
blog

What is RAG? And Why It’s the Key to a Truthful AI Assistant
Joshua
Jan 14, 2026
blog
The Business Case for RAG: Why Every Company Needs a Smart Knowledge Base
Leo
Jan 14, 2026
blog

Step-by-Step: Build Your First AI-Powered Knowledge Base
Joshua
Jan 14, 2026
blog
3 AI Model Implementation Cases for SMEs: Empower Business Efficiently with Limited Budget
Nicole
Jan 8, 2026
blog

A Complete Guide to AI Model Fine-Tuning: LoRA, QLoRA, and Full-Parameter Fine-Tuning
Joshua
Jan 7, 2026
blog
Guide to AI Model End-to-End Lifecycle Cost Optimization
Leo
Jan 7, 2026
blog


Beyond ChatGPT: 6 Niche but Practical Industry Use Cases of AI Models
Leo
Jan 6, 2026
blog

AI Model Training Tools Showdown: TensorFlow vs. PyTorch vs. JAX – How to Choose?
Leo
Dec 23, 2025
blog

AI Model Trends: Lightweight, Multimodal, or Industry-Customized
Margarita
Dec 22, 2025
blog
AI Model Deployment Demystified: A Practical Guide from Cloud to Edge
Joshua
Dec 22, 2025
blog

Double Your AI Model Inference Speed! 5 Low-Cost Optimization Hacks
Joshua
Dec 18, 2025
blog
A Beginner’s Guide to the Complete AI Model Workflow
Joshua
Dec 17, 2025
blog

Efficient Model Serving: Architectures for High-Performance Inference
Joshua
Dec 17, 2025
blog
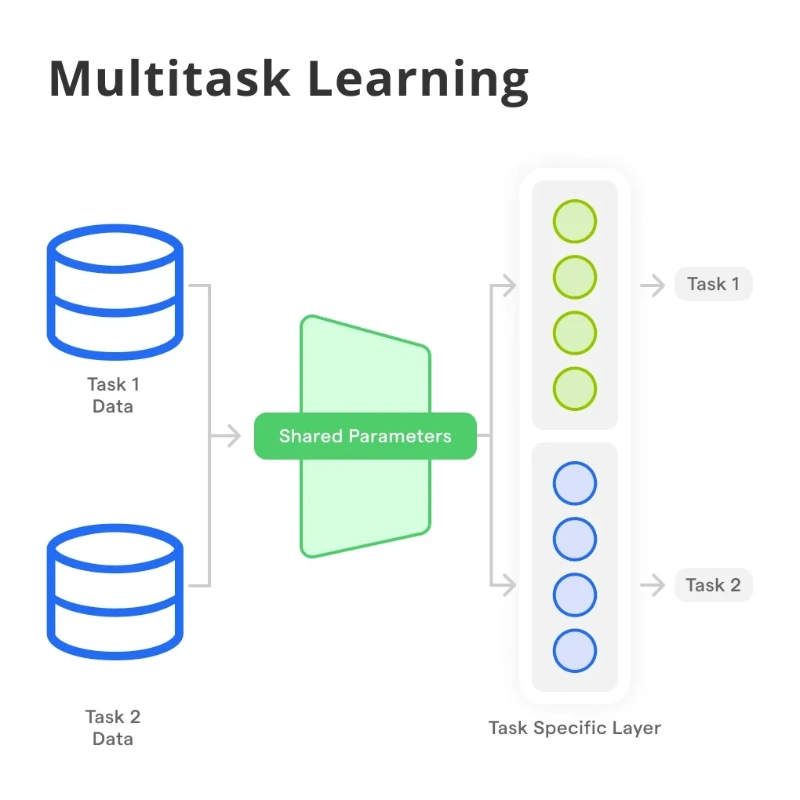
Multi-Task & Meta-Learning: Training Models That Learn to Learn
Leo
Dec 17, 2025
blog

A Practical Guide to Model Compression: Trimming the AI Fat Without Losing Its Smarts
Leo
Dec 16, 2025
blog
Keep Your AI Sharp: A Practical Guide to Monitoring Model Health in Production
Joshua
Dec 16, 2025
blog
Choosing the Right Model Architecture: A Strategic Guide
Joshua
Dec 16, 2025
blog

Small vs. Large Language Models: Choosing the Right Engine for Your AI Journey
Margarita
Dec 15, 2025
blog

The Art and Science of Model Fine-Tuning: Mastering AI with Limited Data
Joshua
Dec 15, 2025
blog

The Cost of Intelligence: A Practical Guide to AI’s Total Cost of Ownership
Clara
Dec 12, 2025
blog

From Lab to Live: The Real-World Hurdles of Model Deployment
Leo
Dec 12, 2025
blog

The Future of AI Development: AutoML, AI Coders, and Smarter Platforms
Margarita
Dec 12, 2025
blog
GPU & RAM: Why This Partnership is Critical for AI Success
Joshua
Dec 2, 2025
blog

GPU VPS Hosting Demystified: Your Gateway to Accessible AI Development
Joshua
Dec 1, 2025
blog

Unlock the True Power of GPU Clusters for AI
Joshua
Dec 1, 2025
blog

Maximize AI Performance with NVIDIA RTX A6000 GPU
Leo
Dec 1, 2025
blog

Beyond Gaming: Leverage NVIDIA GeForce GPUs for AI with Smart Management
Joshua
Nov 24, 2025
blog

Unlock the A5000 GPU’s Full Potential: How WhaleFlux Maximizes ROI for AI Teams
Leo
Nov 24, 2025
blog

Transform Enterprise Knowledge Bases with AI Agents: From Passive Queries to Active Empowerment
Margarita
Nov 19, 2025
blog

AI Agent: The Intelligent Upgrade Key for Your Knowledge Base
Margarita
Nov 19, 2025
blog

Dedicated vs. Shared GPU Memory – A Guide for AI Teams
Leo
Nov 19, 2025
blog

Rethinking “Budget GPU”: Why Access Beats Ownership for AI Companies
Joshua
Nov 18, 2025
blog

Vertical GPU Mounting: An Aesthetic Upgrade or a Strategic One for AI Workstations?
Leo
Nov 18, 2025
blog

Beyond the Spec Sheet: How a GPU Database Powers Smarter AI Infrastructure Decisions
Joshua
Nov 18, 2025
blog

What Is a GPU Cluster? The Ultimate Guide to Harnessing Supercomputing Power for AI
Leo
Nov 18, 2025
blog

How to Update Your GPU: A Guide for AI Teams Seeking Peak Performance
Leo
Nov 18, 2025
blog

Your Practical Guide to GPU Programming in Python: From Learning to Large-Scale Deployment
Joshua
Nov 17, 2025
blog

GPU Computing: The Engine of Modern AI and How to Harness It Efficiently
Joshua
Nov 17, 2025
blog

Finding the Best Affordable GPU for AI? Don’t Just Look at the Sticker Price
Margarita
Nov 17, 2025
blog

Navigate NVIDIA RTX GPU Challenges: How WhaleFlux Optimizes AI Deployment and Cuts Costs
Nicole
Nov 17, 2025
blog

Beyond the Lab: A Practical Guide to ML Model Deployment
Nicole
Nov 10, 2025
Uncategorized

Taming the Cluster Model: A Guide to Efficient Multi-GPU AI Deployment
Margarita
Nov 10, 2025
blog

Drawing Inferences at Scale: Powering AI Decision-Making with Efficient Compute
Joshua
Nov 10, 2025
blog
From Pixels to Predictions: Optimizing Image Inference for Business AI
Leo
Nov 10, 2025
blog

Optimizing Deep Learning Inference for Real-World Deployment
Margarita
Nov 7, 2025
blog

Optimizing AI Model Training and Inference with Efficient GPU Management
Leo
Nov 7, 2025
blog
What Is Hardware-Accelerated GPU Scheduling
Joshua
Nov 6, 2025
blog

How to Increase Data Transfer Speed from CPU to GPU for Faster AI
Leo
Nov 6, 2025
blog

Ampere GPU: The Architectural Powerhouse Behind Modern AI
Nicole
Nov 6, 2025
blog

What Is the Most Powerful NVIDIA GPU
Margarita
Nov 5, 2025
blog

The Best NVIDIA GPUs for Deep Learning
Margarita
Nov 5, 2025
blog

The Ultimate Guide to the Best NVIDIA GPUs for 4K Gaming
Joshua
Nov 4, 2025
blog

Navigating the Data Center GPU Market
Joshua
Nov 4, 2025
blog

How Advanced AI Solutions are Powering the Future of Healthcare
Margarita
Nov 4, 2025
blog

Unlocking AI Potential: The Power of Real-Time Inference Analytics
Leo
Nov 4, 2025
blog

Mastering AI Inference: How to Efficiently Manage Data and GPU Resources
Joshua
Nov 3, 2025
blog
What is Inference Science? And Why It’s the Biggest Hurdle for AI Enterprises
Joshua
Oct 24, 2025
blog

Understanding Inference Chips: The Engine Behind Modern AI Applications
Joshua
Oct 23, 2025
blog

Optimizing Image Inference: From Basics to High-Performance Deployment
Joshua
Oct 23, 2025
blog

Leading AI Inference Security Solutions: Protecting Your Models from Edge to Cloud
Leo
Oct 23, 2025
blog

Building the Best Edge Platform for AI Inference Efficiency
Margarita
Oct 23, 2025
blog

The Best AI Inference Edge Computing for Autonomous Vehicles in 2025
Margarita
Oct 22, 2025
blog
AI Inference Vs Training: A Clear-Cut Guide and How to Optimize Both
Leo
Oct 22, 2025
blog

Best CPU and GPU Combo for Computer Science
Nicole
Oct 22, 2025
blog

Optimizing GPU Compute in VMware Environments with WhaleFlux
Margarita
Oct 22, 2025
blog

How to Make Accelerate Use All of the GPU: From PC Settings to AI Clusters
Margarita
Oct 21, 2025
blog

NVIDIA GPU Cloud Computing: Maximizing Value Beyond Standard Cloud Services
Clara
Oct 21, 2025
blog

How AI is Transforming Healthcare: 2025 Trends and Real-World Applications
Margarita
Oct 17, 2025
blog

Building a Modern High Performance Computing Infrastructure for AI Success
Joshua
Oct 16, 2025
blog

HPC Storage: The Unsung Hero of AI and GPU Computing
Joshua
Oct 16, 2025
blog

GPU Performance Rankings 2025: The Ultimate Guide for AI Workloads
Joshua
Oct 14, 2025
blog

Choosing the Best GPU for AI Training
Margarita
Oct 13, 2025
blog

A Comprehensive Guide for AI Developers
Margarita
Oct 13, 2025
blog

Edge Artificial Intelligence: The Complete Guide to Deploying AI Where It Matters Most
Margarita
Oct 11, 2025
blog

AI GPU Revolution: How NVIDIA Dominates and How to Access This Power
Joshua
Oct 10, 2025
blog

GPU Failure Signs: How to Diagnose Problems and Ensure AI Workload Stability
Joshua
Oct 10, 2025
blog

High Performance Computing Solutions: Powering Innovation from Research to AI
Leo
Oct 10, 2025
blog

High Performance Cloud Computing: Revolutionizing AI and Scientific Research
Clara
Oct 9, 2025
blog

GPU VRAM Explained – Uses, Needs for AI & Gaming
Leo
Sep 30, 2025
blog

GPU Health Check: Key Practices for Safeguarding Computational Performance
Leo
Sep 29, 2025
blog

GPU Stress Tests for AI Teams: What You Need to Know
Joshua
Sep 29, 2025
blog

GPU Benchmarks of H100/H200/A100/RTX 4090 and WhaleFlux Resource Management Solution
Joshua
Sep 28, 2025
blog

Safe GPU Temperatures: A Guide for AI Teams
Leo
Sep 28, 2025
blog

How to Undervolt GPU
Leo
Sep 28, 2025
blog
GPU Stock Tracker: How to Find Available GPUs and a Better Solution for AI Teams
Joshua
Sep 28, 2025
blog

NVIDIA RTX 4090: The Ultimate Enterprise GPU Choice and Smart Resource Management
Leo
Sep 26, 2025
blog

What Does “Ti” Mean in GPUs
Leo
Sep 26, 2025
blog

Marvel Rivals GPU Crashing? Here’s How to Fix It
Margarita
Sep 26, 2025
blog

Hardware-Accelerated GPU Scheduling: What It Is and When to Turn It On
Joshua
Sep 25, 2025
blog

GeForce RTX vs GTX: The Ultimate Guide & How Businesses Should Choose
Margarita
Sep 25, 2025
blog

How to Fix a GPU Memory Leak: A Comprehensive Troubleshooting Guide
Leo
Sep 25, 2025
blog

Navigating the NVIDIA 40 Series: Finding the Best GPU for Your Needs and Budget
Joshua
Sep 25, 2025
blog

Low Profile GPUs: A Comprehensive Guide for Space-Constrained Systems
Joshua
Sep 25, 2025
blog

What Does a Graphics Processing Unit Do
Leo
Sep 25, 2025
blog

Two Types of Gaming GPUs—How Should Enterprises Choose?
Joshua
Sep 23, 2025
blog
Understanding “Sentence of Inference” in ML
Nicole
Sep 17, 2025
blog

How to Deploy LLMs at Scale: Multi-Machine Inference and Model Deployment
Nicole
Sep 16, 2025
blog

A Comprehensive Guide to NVIDIA Graphics Cards for Enterprises & WhaleFlux’s Services
Leo
Sep 16, 2025
blog
GPU Utilization at 100%: Is It Good or Bad for AI Workloads
Joshua
Sep 16, 2025
blog

NVIDIA GeForce RTX and GTX Series: An In-Depth Exploration
Leo
Sep 15, 2025
blog

GPU Benchmark Utilities: How to Measure and Maximize Your AI Hardware Performance
Joshua
Sep 15, 2025
blog

Text Generation Inference: Scaling LLM Deployment with Hugging Face and WhaleFlux
Nicole
Sep 12, 2025
blog

How to Split LLM Computation Across Different Computers: A Distributed Computing Guide
Nicole
Sep 12, 2025
blog

How to List and Manage Models on vLLM Server: A Complete Guide
Nicole
Sep 11, 2025
blog

How to Split and Serve Large Language Models Across GPUs: PowerInfer and Beyond
Nicole
Sep 11, 2025
blog

The Power of GPU Parallel Computing
Leo
Sep 10, 2025
blog

NVIDIA L4 and L40 GPUs Explained: The Ultimate Guide for AI Workloads
Joshua
Sep 10, 2025
blog

Share GPU Memory: A Practical Guide to Resource Optimization for AI Teams
Joshua
Sep 10, 2025
blog

Google Cloud GPUs Explained: Pricing, Performance, and a Smart Alternative
Leo
Sep 10, 2025
blog

AI and Cloud Computing: The Golden Partnership in the Digital Age
Margarita
Sep 9, 2025
blog

GPU Not Showing Up in Task Manager? Diagnostic Guide for AI Workloads
Leo
Sep 9, 2025
blog

Navigating the GPU Shortage: Strategies for AI Teams in 2025
Margarita
Sep 9, 2025
blog

The Diverse Power of NVIDIA GPU Computing: An Exploration of H100, H200, A100, and RTX 4090
Joshua
Sep 8, 2025
blog

Hardware Accelerated GPU Scheduling: How It Transforms AI Operations
Joshua
Sep 8, 2025
blog

How to Check Your GPU – A Guide for AI Teams
Leo
Sep 8, 2025
blog

GPU Cloud Computing: Unlocking Computing Power in the AI Era
Leo
Sep 5, 2025
blog

AI Computing: The Computing Power Engine Behind Artificial Intelligence
Margarita
Sep 4, 2025
blog

GPU Computing: Reshaping the Core of Modern Computing Power
Joshua
Sep 3, 2025
blog

What Is a GPU Accelerator
Leo
Sep 3, 2025
blog

Clearing Confusion: Is a GPU a Video Card
Joshua
Sep 3, 2025
blog

The Ultimate Guide to GPU Rental for AI Enterprises: Why WhaleFlux Stands Out
Clara
Sep 2, 2025
blog

Quantum Computing AI: When Artificial Intelligence Meets the Quantum Revolution
Leo
Sep 2, 2025
blog

The Definitive NVIDIA GPU List for AI
Leo
Sep 2, 2025
blog

Navigating the NVIDIA Blackwell GPU Era
Joshua
Sep 1, 2025
blog

Leveraging New GPU Cards for AI Success
Joshua
Sep 1, 2025
blog

CUDA GPU Setup: A Guide for AI Developers
Margarita
Aug 29, 2025
blog

GPU Not Detected? Troubleshooting Guide for AI Workloads
Leo
Aug 29, 2025
blog

Cloud-Based GPU Taming: Cost & Management for AI Startups
Clara
Aug 29, 2025
blog

Comparative GPU Card Comparison for AI Workloads
Margarita
Aug 28, 2025
blog

Overcoming GPU Artifacts and Optimizing AI Infrastructure
Joshua
Aug 28, 2025
blog

LLM Companies and Their Notable Large Language Models
Nicole
Aug 28, 2025
blog

How to Leverage LLM Tools to Enhance Your Professional Life
Nicole
Aug 28, 2025
blog

GPU Coil Whine: What It Is, Should You Worry, and How to Fix It
Leo
Aug 28, 2025
blog

How LLMs Answer Questions in Different Languages
Nicole
Aug 27, 2025
blog

Finding the Best NVIDIA GPU for Deep Learning
Joshua
Aug 27, 2025
blog

The Truth Behind Model Bias in Artificial Intelligence
Margarita
Aug 26, 2025
blog

Taming the Beast of NVIDIA GPU Costs for AI Enterprises
Clara
Aug 26, 2025
blog

Token: The Hidden Currency Powering Large Language Models
Nicole
Aug 25, 2025
blog

Harnessing the Power of the Foundational Model for AI Innovation
Margarita
Aug 22, 2025
blog

Foundation Models on WhaleFlux: The Cornerstone of Enterprise AI Innovation
Leo
Aug 22, 2025
blog

What Is a Normal GPU Temp? The Ultimate Guide for AI Workloads and Gaming
Leo
Aug 22, 2025
blog

How LLM Applications Are Making Daily Tasks Way Easier?
Nicole
Aug 21, 2025
blog

Is It Time for a GPU Upgrade
Joshua
Aug 21, 2025
blog

How to Manage GPU Computer Power for AI
Joshua
Aug 21, 2025
blog

What is Chain of Thought Prompting Elicits Reasoning in LLM?
Nicole
Aug 20, 2025
blog

Beyond Black Friday: Best GPU Deals with WhaleFlux
Clara
Aug 20, 2025
blog

Beyond “Best 1440p GPU”: Scaling Reddit’s Picks for AI with WhaleFlux
Joshua
Aug 20, 2025
blog

7 Types of LLM You Need to Know About Right Now
Nicole
Aug 19, 2025
blog

Beyond H800 GPUs: Optimizing AI Infrastructure with WhaleFlux
Margarita
Aug 19, 2025
blog

GPU Crash Dump Triggered: Fix Enterprise AI Instability with WhaleFlux
Margarita
Aug 19, 2025
blog

Demystifying GPU Architecture: Why It Matters for AI & How to Manage It Efficiently
Nicole
Aug 18, 2025
blog

Are Transformers LLMs? Stop Confusing These AI Terms Now
Margarita
Aug 18, 2025
blog

Is GPU 99 Usage Good
Leo
Aug 18, 2025
blog

What Generative AI Models Can Do That You Didn’t Expect
Margarita
Aug 15, 2025
blog

Best Budget GPUs in 2025: Gaming, AI, and When to Scale with WhaleFlux
Margarita
Aug 15, 2025
blog

NVIDIA Tesla GPU Cards: Evolution, Impact, and Modern Optimization
Leo
Aug 14, 2025
blog

Open Source AI Models 2025: The Future Is Now
Margarita
Aug 14, 2025
blog

The Power of LLM in Machine Learning: Redefining AI Engagement
Nicole
Aug 13, 2025
blog

Latest NVIDIA GPU: Powering AI’s Future
Margarita
Aug 13, 2025
blog

PS5 Pro vs PS5 GPU Breakdown: How Console Power Stacks Against PC Graphics Cards
Joshua
Aug 13, 2025
blog

Maximizing Value with NVIDIA H100 GPUs & Smart Resource Management
Leo
Aug 12, 2025
blog

Clearing the Confusion: Is A GPU A Graphics Card
Nicole
Aug 12, 2025
blog

How to Train AI LLM for Maximum Performance
Nicole
Aug 11, 2025
blog

When ‘Marvel Rivals’ Triggered GPU Crash Dump: Gaming vs AI Stability
Joshua
Aug 11, 2025
blog

Troubleshooting “Error Occurred on GPUID: 100”
Leo
Aug 11, 2025
blog

GPU for AI: Navigating Maze to Choose & Optimize AI Workloads
Margarita
Aug 11, 2025
blog

CPU and GPU Compatibility: Avoiding Bottlenecks & Maximizing AI Performance with WhaleFlux
Nicole
Aug 8, 2025
blog

CPU-GPU Bottlenecks in AI: Calculate, Fix & Optimize with WhaleFlux
Margarita
Aug 7, 2025
blog
Solved: GPU Failed with Error 0x887a0006
Leo
Aug 7, 2025
blog

Choosing the Best GPU Card for AI: Performance vs Practicality
Leo
Aug 7, 2025
blog

The History of Large Language Models
Nicole
Aug 6, 2025
blog

White GPUs & AI Power: Aesthetics Meet Enterprise Performance
Margarita
Aug 6, 2025
blog

Gaming GPUs vs AI Powerhouses: Choosing the Right GPU for Your PC
Margarita
Aug 6, 2025
blog

PCIe 5.0 GPUs: Maximizing AI Performance & Avoiding Bottlenecks
Joshua
Aug 6, 2025
blog

Difference Between Workshop GPU and Gaming GPU
Leo
Aug 6, 2025
blog

Top 10 Large Language Models in 2025
Nicole
Aug 5, 2025
blog

NVIDIA T4 GPU vs 4060 for AI: Choosing Wisely & Managing Efficiently
Clara
Aug 5, 2025
blog

Doom the Dark Ages: Conquer GPU Driver Errors & Optimize AI Infrastructure
Joshua
Aug 5, 2025
blog

How Reinforcement Fine-Tuning Transforms AI Performance
Leo
Aug 4, 2025
blog

How Large Language Models work?
Nicole
Aug 4, 2025
blog

GPU Tier Lists Demystified: Gaming vs AI Enterprise Needs
Leo
Jul 31, 2025
blog

Finding A Good GPU for Gaming: How It Compares to Enterprise AI Power
Leo
Jul 31, 2025
blog

PSU vs APU vs GPU: Decoding Hardware Roles
Leo
Jul 30, 2025
blog

Fine-Tuning Llama 3 Secrets: Proven Practices Uncovered
Nicole
Jul 29, 2025
blog

8-Core GPU vs 10-Core GPU: Which Powers AI Workloads Best
Margarita
Jul 29, 2025
blog

GPU vs Graphics Card: Decoding the Difference & Optimizing AI Infrastructure
Leo
Jul 29, 2025
blog

NPU vs GPU: Decoding AI Acceleration
Margarita
Jul 28, 2025
blog

Difference Between Fine-Tuning and Transfer Learning
Joshua
Jul 28, 2025
blog

GPU vs TPU: Choosing the Right AI Accelerator
Leo
Jul 28, 2025
blog

Where Do LLMs Get Their Data
Nicole
Jul 25, 2025
blog

GPU Card Compare Guide: From Gaming to AI Powerhouses
Margarita
Jul 25, 2025
blog

Toms GPU Hierarchy Decoded: From Gaming Tiers to AI Power
Margarita
Jul 24, 2025
blog

Finding the Best GPU for Gaming: From Budget Builds to AI Power
Margarita
Jul 24, 2025
blog

Best GPU for 2K Gaming vs. Industrial AI
Margarita
Jul 24, 2025
blog

Choosing the Best GPU for 1080p Gaming
Joshua
Jul 24, 2025
blog

RAG vs Fine Tuning: Which Approach Delivers Better AI Results?
Margarita
Jul 23, 2025
blog

Batch Inference: Revolutionizing AI Model Deployment
Margarita
Jul 23, 2025
blog

From Concepts to Implementations of Client-Server Model
Nicole
Jul 23, 2025
blog

The Best GPU for 4K Gaming: Conquering Ultra HD with Top Choices & Beyond
Margarita
Jul 23, 2025
blog

Finding the Best GPU for 1440p Gaming: Performance, Budget, and Beyond
Margarita
Jul 23, 2025
blog

How to Train LLM on Your Own Data
Nicole
Jul 21, 2025
blog

LoRA Fine Tuning: Revolutionizing AI Model Optimization
Nicole
Jul 21, 2025
blog

Data Inference at Scale: GPU Optimization & Challenges
Nicole
Jul 21, 2025
blog

Optimizing Llama 3 Fine-Tuning: Strategies & Infrastructure for Peak Performance
Nicole
Jul 21, 2025
blog

How the Client-Server Model Drives AI Efficiency
Joshua
Jul 18, 2025
blog

Supervised Fine-Tuning: Elevating LLM Proficiency Through Strategic Refinement
Joshua
Jul 18, 2025
blog

Transfer Learning Vs Fine Tuning
Leo
Jul 18, 2025
blog

GPU Management: Slashing Costs in Gemini Fine-Tuning
Joshua
Jul 17, 2025
blog
Mastering PEFT Fine-Tuning: How PEFT & WhaleFlux Slash LLM Tuning Costs & Boost Performance
Joshua
Jul 17, 2025
blog

Cluster Model: Integrating Computational Management and Data Clustering
Joshua
Jul 17, 2025
blog

Scaling Reinforcement Fine-Tuning Without GPU Chaos
Leo
Jul 17, 2025
blog

Maximizing TRT-LLM Efficiency with Intelligent GPU Management
Leo
Jul 16, 2025
blog

Diffusion Pipeline: Core Processes Unveiled & Practical Application Guide
Leo
Jul 16, 2025
blog

Building Future-Proof ML Infrastructure
Leo
Jul 16, 2025
blog

AI and Machine Learning in Healthcare: Faster Innovation, Lower GPU Costs
Nicole
Jul 15, 2025
blog

Transformers in ML: Scaling AI & Taming GPU Costs
Leo
Jul 15, 2025
blog

AI Inference: From Training to Practical Use
Joshua
Jul 15, 2025
blog

Optimize Your End-to-End ML Workflow: From Experimentation to Deployment
Joshua
Jul 14, 2025
blog

Quantization in Machine Learning:Shrink ML Models, Cut Costs, Boost Speed
Joshua
Jul 14, 2025
blog

The True Cost of Training LLMs: How to Slash GPU Bills Without Sacrificing Performance
Clara
Jul 11, 2025
blog

Model Inference at Scale: How Smart GPU Management Unlocks Cost-Efficient AI
Clara
Jul 11, 2025
blog

Cloud Deployment Models for AI: Choosing the Right GPU Strategy with WhaleFlux
Clara
Jul 11, 2025
blog

Fine-Tuning LLMs Without Supercomputers: How GPU Optimization Unlocks Cost-Effective Customization
Joshua
Jul 10, 2025
blog

Real-Time Alerts for GPU Clusters: Stop Costly AI Downtime Before It Starts
Joshua
Jul 10, 2025
blog

Full-Stack Observability: The Secret Weapon for Efficient AI/GPU Operations
Joshua
Jul 10, 2025
blog

GPU Testing Unleashed: Benchmarking, Burn-Ins & Real-World AI Validation
Nicole
Jul 8, 2025
blog

PyTorch GPU Mastery: Setup, Optimization & Scaling for AI Workloads
Nicole
Jul 4, 2025
blog

AI GPUs Decoded: Choosing, Scaling & Optimizing Hardware for Modern Workloads
Nicole
Jul 3, 2025
blog

Splitting LLMs Across GPUs: Advanced Techniques to Scale AI Economically
Nicole
Jul 3, 2025
blog

Renting GPUs for AI: Maximize Value While Avoiding Costly Pitfalls
Nicole
Jul 3, 2025
blog

How Does a GPU Work How GPUs Power AI
Nicole
Jul 3, 2025
blog

GPU Cloud Computing: The Hidden Cost of “Free” and How WhaleFlux Delivers Real Value
Leo
Jul 1, 2025
blog

Parallel Computing in Python: From Multi-Core to Multi-GPU Clusters with WhaleFlux
Leo
Jul 1, 2025
blog

Dedicated GPU Power Unleashed: Why Enterprises Choose WhaleFlux Over Gaming Tactics
Leo
Jul 1, 2025
blog

CUDA Unchained: How WhaleFlux Turns CUDA GPU Potential into AI Profit
Joshua
Jun 30, 2025
blog

How GPU and CPU Bottlenecks Bleed Millions (and How WhaleFlux Fixes It)
Joshua
Jun 30, 2025
blog

GPU VRAM: How WhaleFlux Maximizes Your GPU Memory ROI
Clara
Jun 25, 2025
blog

TensorFlow GPU Mastery: From Installation Nightmares to Cluster Efficiency with WhaleFlux
Clara
Jun 25, 2025
blog

GPU Usage 100%? Why High Use Isn’t Always High Efficiency in AI and How to Fix It
Clara
Jun 25, 2025
blog

Distributed Computing Decoded: From Theory to AI Scale with WhaleFlux
Joshua
Jun 24, 2025
blog

GPU Utilization Decoded: From Gaming Frustration to AI Efficiency with WhaleFlux
Joshua
Jun 24, 2025
blog

Unlock True Potential of RTX 4090 with WhaleFlux
Margarita
Jun 23, 2025
blog

Maximize Your NVIDIA A100 Investment with WhaleFlux
Margarita
Jun 23, 2025
blog

How HPC Centers and Smart GPU Management Drive Breakthroughs
Margarita
Jun 23, 2025
blog

High Performance Computing Jobs with WhaleFlux
Margarita
Jun 23, 2025
blog

High Performance Computing Cluster Decoded
Leo
Jun 17, 2025
blog

What High-Performance Computing Really Means in the AI Era
Leo
Jun 17, 2025
blog

GPU Coroutines: Revolutionizing Task Scheduling for AI Rendering
Leo Chen
Jun 16, 2025
blog

The Vanishing HAGS Option: Why It Disappears and Why Enterprises Shouldn’t Care
Leo Chen
Jun 16, 2025
blog

Beyond the HAGS Hype: Why Enterprise AI Demands Smarter GPU Scheduling
Leo Chen
Jun 16, 2025
blog

GPU Compare Tool: Smart GPU Price Comparison Tactics
Joshua
Jun 13, 2025
blog

GPU Compare Chart Mastery From Spec Sheets to AI Cluster Efficiency Optimization
Joshua
Jun 13, 2025
blog

GPU Performance Comparison: Enterprise Tactics & Cost Optimization
Joshua
Jun 11, 2025
blog

The Ultimate GPU Benchmark Guide: Free Tools for Gamers, Creators & AI Pros
Leo
Jun 10, 2025
blog

How to Reduce AI Inference Latency: Optimizing Speed for Real-World AI Applications
Nicole
May 30, 2025
blog

How to Test LLMs: Evaluation Methods, Metrics, and Best Practices
Margarita
Mar 13, 2025
blog

Mastering LLM Inference: A Comprehensive Guide to Inference Optimization
Margarita
Mar 13, 2025
blog

Maximizing Efficiency in AI: The Role of LLM Serving Frameworks
Nicole
Jan 17, 2025
blog


New Frontiers in AI: Scaling Up with the Latest AI Infrastructure Advances
Clara
Jan 17, 2025
blog

LLM Serving 101: Everything About LLM Deployment & Monitoring
Nicole
Jan 17, 2025
blog
How AI and Cloud Computing are Converging
Clara
Jan 17, 2025
blog

The Role of Data Centers in Powering AI’s Future
Joshua
Jan 17, 2025
blog

Crafting Intelligence: A Step-by-Step Guide to Building Your AI Application
Clara
Jan 17, 2025
blog

The Evolution of NVIDIA GPUs: A Deep Dive into Graphics Processing Innovation
Clara
Jan 16, 2025
blog

Inference Acceleration: Unlocking the Extreme Performance of AI Models
Clara
Jan 15, 2025
blog