Cost-Optimizing Your Agent Workforce: TCO in the Era of LLMs
Introduction: The Invisible Tax on Autonomy
The promise of the Autonomous Agent is a business that runs while you sleep. But for many CTOs, the reality is a budget that disappears while they watch. In 2026, the primary barrier to the “Agentic Enterprise” isn’t a lack of reasoning capability—it’s the Inference Tax.
Scaling an agent workforce from ten to ten thousand agents requires an exponential increase in compute power. However, traditional cloud infrastructure is poorly equipped for the “bursty,” multi-step nature of agentic workflows. This results in GPU Waste: expensive H200s and B200s sitting idle while an agent “thinks” or waits for a tool response, yet billing you for every millisecond of uptime. To survive the era of LLMs, businesses must move from “throwing hardware at the problem” to Intelligent Workforce Orchestration.

1. Decoding the Agent TCO: More Than Just Tokens
When calculating the TCO of an AI agent workforce, most organizations make the mistake of only looking at API costs. In reality, the cost structure of a self-hosted or hybrid agent ecosystem is a four-headed beast:
Compute Idle Time:
Agents don’t use GPUs 100% of the time. They spend 60-80% of their lifecycle waiting for API responses, database queries, or “thinking” between multi-step tasks. In a standard setup, that GPU is reserved and wasted during these gaps.
Memory Overhead:
Each agent maintains a context window. As agents become more sophisticated, their “memory” consumes massive amounts of VRAM, leading to memory-bound bottlenecks that force companies to buy more hardware than they actually need for the raw compute.
Network Latency Costs:
In distributed agent systems, data movement between nodes can become the dominant bottleneck, causing GPUs to wait for data (IO wait), further driving up the cost per task.
Maintenance & Retraining:
The “hidden” 20% of TCO involves the human cost of managing the infrastructure and fine-tuning models to stay relevant.
2. The WhaleFlux Solution: Reducing TCO by 40-70%
This is where WhaleFlux enters the equation. We recognized that the only way to make a large-scale agent workforce economically viable is to treat AI compute like a living utility, not a static server.
WhaleFlux is an orchestration layer designed specifically for the Agentic Era. By implementing Intelligent Schedulingand Dynamic Quantization, WhaleFlux allows enterprises to slash their TCO by 40% to 70% without sacrificing agent performance.
WhaleFlux Intelligent Scheduling
Traditional schedulers treat an LLM request like a black box. WhaleFlux’s scheduler is “Agent-Aware.” It predicts the gaps in an agent’s reasoning chain and fills those GPU micro-seconds with tasks from other agents.
This “Hyper-Batching” technique means you can run 3x to 5x the number of agents on the same cluster of GPUs. Instead of 100 agents per node, WhaleFlux pushes the boundaries of hardware density, effectively turning your GPU “waste” back into “work.”
3. Avoiding GPU Waste via Model Quantization
Not every task requires the full FP16 precision of a 70B parameter model. One of the most effective ways WhaleFlux optimizes costs is through Adaptive Quantization.
For routine administrative tasks or initial data parsing, WhaleFlux dynamically switches the agent to a quantized version of the model (e.g., 4-bit or 8-bit). This reduces the memory footprint by up to 75%, allowing more agents to stay resident in the VRAM simultaneously. This prevents the costly “context-swapping” that occurs when an agent has to be moved in and out of the GPU memory, which is one of the biggest silent killers of TCO.
4. Scaling Without the Budget Bloat
The ultimate goal of WhaleFlux is to decouple your workforce growth from your budget growth. With our 40-70% cost-reduction advantage, a company that previously could only afford 50 autonomous agents can now deploy 150-200 agents under the same budget cap.
By utilizing WhaleFlux, you aren’t just saving money; you are gaining Compute Elasticity. You can scale your agentic operations during peak market hours and throttle back during lulls, ensuring that every dollar spent on a GPU core is directly tied to a business outcome.
Conclusion: The Efficiency Frontier
In the era of LLMs, the competitive advantage belongs to the companies that can generate the most “intelligence per dollar.” GPU waste is the friction that stops innovation.
By addressing the core drivers of TCO—idle time, memory mismanagement, and static scheduling—WhaleFlux provides the “efficiency engine” required to run a truly autonomous enterprise. Don’t let your GPU budget dictate the size of your ambitions. Optimize your perimeter, eliminate the waste, and scale your workforce into the future.
Stop paying for idle time. Start scaling with WhaleFlux.
FAQ: Optimizing Agent Workforce Costs
1. Why is the TCO of AI Agents higher than traditional software?
Traditional software has a predictable “compute-per-user” cost. AI Agents have an “inference-per-thought” cost. Because agents perform multi-step reasoning, a single user request might trigger 20 different LLM calls, tool uses, and self-corrections, leading to a much higher and more volatile cost profile.
2. How does WhaleFlux achieve a 70% reduction in TCO?
We achieve this through a “Stack of Gains”: 30% from Intelligent Scheduling (reducing idle time), 20% from Dynamic Quantization (packing more agents into VRAM), and 20% from optimized IO paths that reduce data bottlenecking. Combined, these factors dramatically lower the cost per agent task.
3. Does reducing costs with Quantization affect the quality of the agent’s work?
WhaleFlux uses Adaptive Quantization. For complex reasoning (like legal or medical analysis), the system uses full precision. For simpler “routing” or “summarization” tasks, it uses quantized models. This ensures quality is maintained exactly where it’s needed while saving costs on simpler sub-tasks.
4. Can WhaleFlux work with my existing cloud provider (AWS/Azure)?
Yes. WhaleFlux is designed as an orchestration layer that sits on top of your existing infrastructure. Whether you are using bare-metal H100s in a private data center or spot instances on AWS, WhaleFlux optimizes the scheduling layer to ensure you get the most out of every rented or owned GPU.
5. What is “GPU Waste” exactly?
GPU Waste occurs when a GPU is “allocated” to a process but its cores are at 0% utilization. In agent workflows, this happens during “IO-wait” (waiting for data) or “Logic-wait” (waiting for the next step of an agent’s plan). WhaleFlux eliminates this by interleaving other tasks into those empty slots.
From RAG to Agents: The Evolution of Contextual Intelligence and Action
For the past two years, the corporate world has been obsessed with Retrieval-Augmented Generation (RAG). It was the first “bridge” that allowed static Large Language Models (LLMs) to talk to dynamic, private data. RAG solved the hallucination problem for many, turning AI into an incredibly efficient librarian. But as we move into 2026, the librarian is no longer enough. Enterprises are demanding Action.
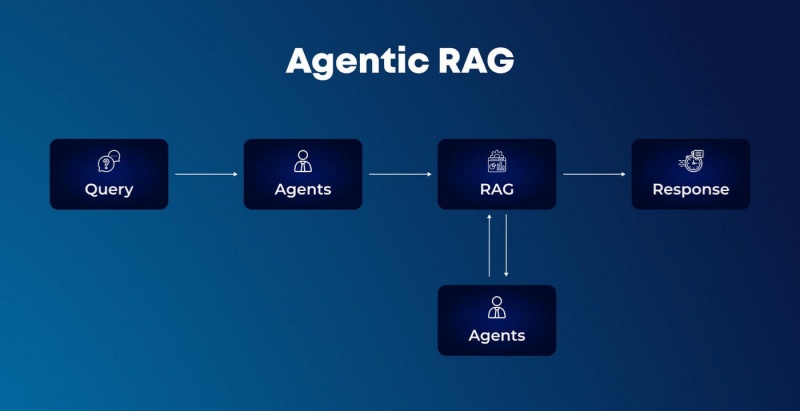
The industry is currently undergoing a fundamental shift: the evolution from Contextual Retrieval (RAG) to Contextual Agency (AI Agents). We are moving from systems that simply “find and tell” to systems that “reason and do.” This evolution marks the birth of true Contextual Intelligence—where an AI doesn’t just understand the query but has the agency to call tools, execute workflows, and complete closed-loop tasks.
However, the leap from a RAG pipeline to a reliable AI Agent is fraught with technical hurdles, particularly the “reliability gap” in tool-calling. This is where the underlying infrastructure and Model Refinement processes, such as those pioneered by WhaleFlux, become the deciding factor in a project’s success.
The Limitation of RAG: Knowledge Without Power
RAG was a massive leap forward. By fetching relevant document chunks and stuffing them into the prompt’s context window, we gave LLMs a “temporary memory” of enterprise facts.
The RAG workflow is essentially linear:
User Query: “What was our Q3 churn rate?”
Retrieval: Search the vector database.
Augmentation: Attach the churn report to the prompt.
Generation: The model summarizes the report.
While powerful, RAG is inherently passive. It is a one-way street ending in a text response. If the user asks the follow-up, “Fix the underlying billing issue causing the churn,” a RAG system hits a wall. It has the knowledge, but it lacks the agency to interact with the billing system.
The Rise of the Agent: Intelligence with Agency
An AI Agent differs from a RAG system because it possesses a Loop of Reasoning. It doesn’t just generate text; it generates a Plan. Agents are equipped with “Tools”—APIs, Python interpreters, or database connectors—and the autonomy to decide when and how to use them.
The Agentic workflow is iterative:
- Perception: Understand the goal.
- Planning: “First, I need to check the billing logs. Then, I need to identify the affected users. Finally, I will apply a credit to their accounts.”
- Action (Tool Calling): The agent generates a specific JSON command to call the
Billing_API. - Observation: The agent reads the API’s response. Did it work? If not, refine the plan and try again.
This “Closed-Loop” capability is what transforms AI from a consultant into a Digital Worker. But for this loop to hold, the agent must be nearly perfect at Tool-calling. If the agent misses a comma in an API call or confuses a “User_ID” with an “Account_ID,” the loop breaks, and the automation fails.
The Reliability Gap: Why “Off-the-Shelf” Models Fail
Most developers start by using “frontier” models (like GPT-4 or Claude 3.5) for their agents. While these models are brilliant at general reasoning, they often stumble when faced with proprietary enterprise tools.
Generic models are trained on the open internet. They don’t know your company’s specific Legacy_ERP_v2 API schema. They might struggle with the nuances of your internal data structures, leading to “Near-Miss Tool Calls”—where the model tries to use a tool but provides the wrong parameters. In a production environment, a 90% success rate in tool-calling is a failure; you need 99.9%.
WhaleFlux: Refining the Brain for Precision Action
This is where WhaleFlux enters the architectural stack. WhaleFlux isn’t just a place to host models; it is a Model Refinery.
We believe that true agency requires Specialized Intelligence. To bridge the gap between “Contextual Retrieval” and “Autonomous Action,” models must be refined for the specific environment they inhabit.
WhaleFlux Model Refinement provides the precision tools necessary to transform a general-purpose base model into a highly specialized Agentic Engine. Through our integrated Fine-tuning pipelines, enterprises can train their models on their specific API schemas, internal documentation, and historical “correct” tool-calling logs.
By performing Supervised Fine-Tuning (SFT) on WhaleFlux’s high-performance Compute Infra, you aren’t just teaching the model facts; you are teaching it the Grammar of your Business.
The WhaleFlux Advantage in Tool-Calling Accuracy:
Schema Mastery:
Fine-tuning on WhaleFlux ensures your agent understands the exact JSON requirements of your private APIs, reducing syntax errors to near zero.
Domain Alignment:
WhaleFlux helps align the model’s reasoning path with your industry’s specific logic (e.g., medical triage or financial risk assessment).
Low-Latency Execution:
Because WhaleFlux synchronizes the Compute Infra with the refined models, the “Reasoning-to-Action” latency is minimized, which is critical for agents performing multi-step tasks.
From Retrieval to Closed-Loop Workforces
When you combine Contextual Intelligence (the “What”) with Refined Agency (the “How”), you create an Autonomous Agent Workforce.
Imagine a Customer Success Agent on the WhaleFlux platform:
- Retrieval: It uses RAG to understand the customer’s history.
- Refinement: Using its Fine-tuned brain, it identifies that the customer is eligible for a loyalty discount based on a complex internal policy.
- Action: It calls the
Discount_Servicetool to apply the credit. - Verification: It calls the
Email_Serviceto notify the customer and logs the action in the CRM.
This is a Closed-Loop Task. The human is no longer the “middleman” who has to take the information from the AI and manually type it into another system. The AI has become the executor.
Conclusion
RAG was the necessary first step, proving that AI could be grounded in reality. But the future of enterprise AI belongs to Agents. The transition from “finding information” to “executing workflows” is the most significant leap in productivity we will see this decade.
However, agency requires a level of precision that general-purpose models cannot provide out of the box. By utilizing WhaleFlux and its Model Refinement capabilities, organizations can harden their agents, ensuring that every tool call is accurate, every plan is logical, and every loop is closed. Don’t just build an AI that knows your business—build one that works for it.
Frequently Asked Questions (FAQ)
1. Is RAG still useful if I am building an AI Agent?
Yes, absolutely. Think of RAG as the agent’s “Reference Library.” Agents use RAG to gather the context they need before they decide which tool to call. RAG provides the knowledge, while the Agent provides the action.
2. How does fine-tuning on WhaleFlux improve tool-calling?
Standard models are “jacks of all trades.” When you fine-tune on WhaleFlux, you are giving the model thousands of examples of your specific API calls. This teaches the model to recognize the patterns and constraints of your specific tools, drastically reducing the hallucination of parameters.
3. Do I need massive amounts of data for Model Refinement on WhaleFlux?
Not necessarily. For tool-calling specialization, “quality over quantity” is key. A few hundred high-quality examples of correct tool interactions can significantly boost an agent’s performance on the WhaleFlux platform.
4. What is “Closed-Loop” automation?
Closed-loop automation refers to a process where the AI identifies a problem, plans a solution, executes the necessary actions via tools, and then verifies that the problem is solved—all without requiring a human to manually bridge the gap between steps.
5. How does WhaleFlux ensure the security of my proprietary tool-calling data?
WhaleFlux utilizes Hardware-Level Sovereignty. Your fine-tuning datasets and the resulting model weights are sequestered in secure enclaves. This ensures that your “Business Grammar”—the secret sauce of how your company operates—remains strictly under your control.
The Architecture of Autonomy: Building an AI Agent Platform for Scale
In 2026, the corporate world has moved beyond the excitement of “chatting with data.” We are now in the era of the Autonomous Agent Workforce. Organizations are no longer looking for simple chatbots; they are building sophisticated, multi-agent platforms capable of reasoning, calling tools, and executing complex business logic with minimal human intervention.
However, moving from a prototype agent to an enterprise-grade AI agent platform is a monumental engineering challenge. Scaling autonomy requires more than just a powerful LLM; it requires a robust, layered architecture that can handle non-deterministic behavior, manage high-density compute, and ensure absolute reliability. This article deconstructs the blueprint of modern autonomy—the perception, decision, and execution layers—and introduces how WhaleFlux provides the critical Agent Orchestration foundation needed to turn these blueprints into reality.
The Blueprint: Three Pillars of Agentic Architecture
To build an agent that truly scales, we must separate its “intelligence” from its “operational logic.” A production-ready architecture is typically divided into three functional layers.
1. The Perception Layer: The Interface with Reality
The Perception Layer is the agent’s sensory system. In an enterprise environment, this isn’t just about reading text; it’s about Data Ingestion and Semantic Normalization.
Multimodal Input:
Processing structured SQL data, unstructured PDFs, real-time sensor streams, and API webhooks.
Contextual Filtering:
Not every piece of data is relevant. This layer must sanitize and filter noise to prevent “context overflow” in the reasoning engine.
Observation Loop:
Unlike a traditional program, an agent constantly “observes” the results of its previous actions. The perception layer feeds this feedback back into the system.
2. The Decision Layer: The Reasoning Engine
This is where the LLM resides, but the Decision Layer is more than just a model. It is the Reasoning and Planning hub.
Goal Decomposition:
Taking a high-level command (e.g., “Analyze the Q3 supply chain risks”) and breaking it into sub-tasks.
Memory Management:
Short-term memory (conversation buffer) and long-term memory (vector databases) allow the agent to learn from past interactions.
Constraint Enforcement:
Ensuring the agent operates within defined guardrails, such as budget limits or safety protocols.
3. The Execution Layer: Turning Logic into Action
If the decision layer is the “brain,” the Execution Layer is the “hands.” It is responsible for Tool Calling and System Interaction.
API Integration:
Interacting with ERP, CRM, or custom internal systems.
Sandbox Execution:
Running code or scripts in a secure environment to validate results before they go live.
Error Recovery:
Handling “retry” logic when a tool fails or an API returns a 404 error.
The Scaling Bottleneck: Why Orchestration is the Missing Link
While building a single agent is straightforward, managing a Multi-Agent Ecosystem is where most enterprises fail. When you have hundreds of agents performing concurrent tasks, you encounter the “Orchestration Gap”:
Resource Contention:
Which agent gets priority on the H100 cluster?
State Drift:
How do you keep state consistent across asynchronous workflows?
Data Friction:
The latency and overhead caused by moving data between fragmented service providers.
This is precisely where WhaleFlux transforms the architecture from a collection of scripts into a high-performance industrial platform.
WhaleFlux: The Hardened Control Plane for Autonomy
WhaleFlux is engineered for the “Execution” and “Orchestration” of autonomous intelligence. We provide the unified control plane that synchronizes your entire agentic stack.
WhaleFlux provides a production-hardened Agent Orchestration layer that abstracts the complexity of the underlying Compute Infra. By integrating model refinement and agent execution into a single, Hardened Control Plane, WhaleFlux eliminates the data friction that plagues multi-vendor setups. Our platform ensures that whether you are running a single reasoning agent or a massive autonomous workforce, every task is executed with 99.9% resilience and deterministic stability.
How WhaleFlux Powers the Autonomous Architecture:
Simplified Workflows:
WhaleFlux’s control plane allows architects to define complex “Agent Graphs” without worrying about the underlying GPU scheduling.
Silicon-Level Integration:
Because WhaleFlux manages the Compute Infra, your agents have direct, low-latency access to Fine-tuned Models, reducing the “time-to-action” for real-time agents.
Predictable ROI:
Through intelligent orchestration, WhaleFlux typically delivers a 40-70% reduction in TCO, allowing you to scale your agent platform without a linear increase in costs.
Conclusion
Building an AI Agent Platform for scale is a journey from “logic” to “infrastructure.” The perception, decision, and execution layers provide the framework, but Agent Orchestration provides the heartbeat. Without a hardened control plane like WhaleFlux, autonomy remains a fragile experiment.
As we move toward a future where agents handle mission-critical business operations, the winners will be those who architect for stability, security, and scale. By anchoring your autonomous workforce on WhaleFlux, you aren’t just building an agent—you are architecting the future of your enterprise.
Frequently Asked Questions (FAQ)
1. What is the difference between AI Orchestration and Agent Orchestration?
AI Orchestration generally refers to managing data and model pipelines. Agent Orchestration specifically focuses on the coordination of autonomous entities that reason, revise their plans, and use tools iteratively to reach a goal.
2. Why is a unified control plane important for scaling agents?
A unified control plane like the one provided by WhaleFlux ensures that policies, security protocols, and resource allocations are applied consistently across all agents. It prevents “orphaned agents” and ensures that multi-agent workflows don’t collapse due to resource contention.
3. Can I use WhaleFlux with my existing LangChain or LangGraph frameworks?
Yes. WhaleFlux is designed to be the Industrial Foundation for your agentic logic. You can build your agents using your favorite frameworks and use WhaleFlux to provide the Compute Infra, Model Refinement, and Production-Grade Execution needed to scale them.
4. How does the perception layer handle data privacy in a scaled platform?
In a hardened architecture like WhaleFlux, the perception layer can be integrated with Hardware-Level Sovereignty. This ensures that sensitive data is processed within secure enclaves, maintaining a zero-trust environment even as the agent interacts with external data sources.
5. How does orchestration help with agent “infinite loops”?
A robust orchestration layer monitors agent behavior in real-time. WhaleFlux’s control plane includes guardrails that detect “reasoning loops” or runaway API calls, automatically intervening or alerting administrators to prevent cost spikes and system instability.
The Autonomous Enterprise: Evaluation of Oracle on Agentic AI and the Rise of AI Agent That Controls Your Computer
Introduction: From “Ask” to “Act”
For the past few years, the world was obsessed with chatbots. We asked questions, and AI gave us answers. But in 2026, the paradigm has shifted. We no longer want an AI that talks; we want an ai agent that controls your computer to get things done.
The industry has moved from Generative AI to Agentic AI—systems that don’t just suggest a response but actually take control of the keyboard, the database, and the cloud infrastructure to execute complex multi-step tasks. As these ai agents take control of my computer environments, the enterprise world is looking to tech titans to see who can provide the most secure and reliable “digital workforce.”
In this landscape, Oracle has emerged as a surprisingly aggressive leader. This post evaluates the cloud computing company oracle on agentic ai and examines the critical infrastructure needed to keep these autonomous agents from crashing the very systems they manage.

1. The Mechanics: How an AI Agent Controls Your Computer
When we say an ai agent control computer functions, we aren’t talking about sci-fi possession. We are talking about Large Action Models (LAMs) and specialized interface controllers.
Modern agents use a “perceive-plan-act” loop:
- Perceive: The agent “sees” the screen or reads the API documentation of your software.
- Plan: It breaks a high-level goal (e.g., “Reconcile the Q3 logistics invoices”) into 50 sub-tasks.
- Act: The ai agent takes control of computer inputs, clicking buttons, moving data between Excel and ERP systems, and sending emails—all without human intervention.
This shift allows for a 1:100 ratio of human oversight to task execution, fundamentally decoupling revenue growth from headcount.
2. Evaluation: Oracle’s Play in the Agentic AI Era
Oracle (ORCL) has historically been viewed as a legacy database company, but its 2026 trajectory tells a different story. To evaluate the cloud computing company oracle on agentic ai, we must look at their “Embedded-First” strategy.
The “Agentic Database” 26ai
Oracle’s crown jewel is the Oracle Database 26ai. Unlike competitors who treat AI as a bolt-on service, Oracle has moved the vector search and the agentic reasoning inside the data layer. This means an agent doesn’t have to “call” the data; it lives within it, drastically reducing latency and increasing security.
Fusion Applications: Pre-Built Agents
Oracle has deployed over 50 native AI agents across its Fusion Cloud (ERP, HCM, SCM). These aren’t just assistants; they are “Assurance Advisors” that monitor supply chain disruptions and autonomously initiate re-routing of shipments. Oracle’s strength lies in its vertical integration—they own the data, the application, and the cloud infrastructure (OCI).
The Verdict
Oracle is currently a Market Leader in enterprise agentic AI. Their unique RDMA (Remote Direct Memory Access) networking allows their agents to coordinate across massive clusters faster than traditional cloud providers. However, their “closed-loop” ecosystem can be a double-edged sword for companies wanting to use third-party models.
3. The Stability Paradox: Why Agents Need WhaleFlux
As ai agents take control of my computer and enterprise systems, a new danger emerges: The Feedback Loop of Failure. If an autonomous agent encounters a hardware “hiccup” or a network delay while it is in the middle of a multi-step financial transaction, the results can be catastrophic. Agents are non-deterministic; if the infrastructure is unstable, the agent’s behavior becomes unpredictable.
This is where the philosophy of “stability before scale” is put to the test. To truly let ai agents that control your computer run free, you need a self-healing infrastructure layer.
WhaleFlux is the invisible guardian of this autonomous era. While Oracle provides the “brain” (the agent), WhaleFlux provides the “immune system” for the underlying GPU and CPU clusters. By using failure prediction innovation, WhaleFlux detects when a node is about to degrade before the agent starts its task. If an agent is about to take control of a system that is showing signs of instability, WhaleFlux can pause the execution or move the agent’s environment to a healthy node.
In the world of agentic AI, reliability is the only path to trust. You wouldn’t let an AI agent control your computer if you didn’t trust the computer to stay online. WhaleFlux ensures that the “digital worker” always has a stable stage to perform on.
4. Risks and Governance: When AI Agents Control Your Computer
The prospect of ai agents controlling your computer brings valid fears regarding security and “hallucination in action.”
- Permission Scoping: Enterprises are implementing “Least Privilege” models where agents only have access to specific buttons and data fields.
- Human-in-the-Loop (HITL): For high-value actions (e.g., a $1M wire transfer), the agent takes control up to the final “Send” button, then waits for a human thumbprint.
- Audit Trails: Oracle’s agentic platform provides an immutable log of every “thought” and “click” the agent made, ensuring accountability.
Conclusion: The New Workforce
The evaluation is clear: Oracle is no longer a legacy giant; it is the infrastructure titan of the agentic age. But as we move toward a future where ai agents control computer systems entirely, the focus must shift from “What can the agent do?” to “How stable is the system running the agent?”
By combining Oracle’s powerful agentic frameworks with the self-healing resilience of WhaleFlux, enterprises can finally move past the pilot phase. We are entering an era where your computer doesn’t just wait for your command—it anticipates your needs and executes them on a foundation of ironclad stability.
Frequently Asked Questions
1. Is it safe to let an ai agent control my computer?
In an enterprise context, yes, provided there are strict “sandboxes” and governance layers. Modern agents operate within a defined scope and cannot access files or functions they aren’t explicitly permitted to use.
2. How is Oracle different from Microsoft or Google in Agentic AI?
Oracle’s primary advantage is its data-centricity. Because most of the world’s mission-critical data already sits in Oracle databases, their agents can act on that data with higher security and lower latency than agents that have to fetch data from external sources.
3. What happens if a GPU fails while an agent is taking control of a task?
Without a system like WhaleFlux, the agent’s task would likely fail, potentially leaving the database in an inconsistent state. WhaleFlux prevents this by predicting hardware failure and moving the agent’s “context” to a healthy server before the crash occurs.
4. Will ai agents that control your computer replace human workers?
They are designed to replace tasks, not necessarily people. By handling repetitive “clicking and moving” data, agents allow humans to focus on strategy, exception handling, and creative problem-solving.
5. Can I use WhaleFlux with Oracle Cloud Infrastructure (OCI)?
Yes. WhaleFlux is designed to provide an additional layer of hardware health monitoring and self-healing for any high-performance compute environment, including OCI-based GPU clusters running agentic workloads.
3 Strategic Moves to Slash OpenClaw Running Costs by 70%
TL;DR: OpenClaw Cost Optimization
The Core Inefficiency: Most OpenClaw deployments waste 40-60% of their budget on Idle VRAM and unoptimized KV Cache storage during agent “thinking” cycles.
Strategic Pivot: Achieve a 70% TCO reduction by shifting from fixed-instance clusters to Intelligent Scaling and leveraging FP8/INT4 Quantization for inference-heavy workflows.
The Interconnect Factor: High-concurrency agents fail on standard cloud networks; WhaleFlux’s 400Gb/s RDMA fabric ensures that data ingestion doesn’t inflate your billable GPU hours.
WhaleFlux Advantage: Our Full-stack AI Observability identifies “Zombie Processes” in your OpenClaw stack, automatically reclaiming resources to ensure you only pay for active token generation.

1. Eliminate “Compute Ghosting” via Intelligent Scaling
The primary driver of high costs in OpenClaw isn’t the GPU price; it’s Compute Ghosting—the practice of keeping a high-performance node (like an H100) active while an agent is idling or waiting for API callbacks.
At WhaleFlux, we solve this via Intelligent Scaling. Our platform monitors the OpenClaw request queue in real-time. When agentic activity drops, the workload is automatically migrated to a high-efficiency L4 or RTX 4090 node. This “Hot-Swapping” of compute tiers can slash monthly burn by 40% without compromising TTFT (Time-to-First-Token).
2. Quantization: Balancing Fidelity and Finance
Running OpenClaw on full FP16 precision is often a “budget killer” for 70B+ parameter models.
The Move:
Implement FP8 or AWQ Quantization. This reduces the VRAM footprint per model by nearly 50%, allowing you to fit larger context windows into a single GPU.
The ROI:
By doubling the density of agents per card, you effectively halve your hardware cost per user. WhaleFlux nodes are pre-optimized for Transformer Engine FP8, ensuring that this precision drop has near-zero impact on agentic reasoning accuracy.
3. Observability-Driven Resource Reclammation
OpenClaw environments are notorious for “leaking” VRAM due to hung Python processes or unoptimized KV Caches in multi-turn conversations.
The WhaleFlux Solution:
Our Deep Observability dashboard tracks Model Bandwidth Utilization (MBU) at the kernel level.
Actionable Fix:
If an OpenClaw instance shows 100% VRAM usage but 0% Compute utilization, WhaleFlux triggers an automated Cache Purge or container restart, preventing “Frozen ROI” scenarios.
4. The OpenClaw Cost Matrix
| Strategy | Traditional Cloud (GCP/AWS) | WhaleFlux Engineered Infrastructure |
| Scaling Model | Slow Auto-scaling Groups | Instant Intelligent Scaling |
| VRAM Management | Manual / Static | Automated KV Cache Orchestration |
| Interconnect | Shared 10-25GbE (Latency Bottleneck) | Dedicated 400Gb/s RDMA Fabric |
| Cost Control | Post-facto Billing Surprises | Real-time Token-per-Dollar Analytics |
| Total Savings | 0% (Baseline) | Up to 70% Reduction |
Expert FAQ
Q: Will reducing costs by 70% impact the latency of my agents?
A: No. The savings come from eliminating Resource Waste, not cutting performance. By using WhaleFlux Intelligent Scaling, we ensure peak H200/H100 power is available instantly for “Prefill” phases while idling on cheaper silicon during “Decode” phases.
Q: How does WhaleFlux handle “Cold Starts” when scaling OpenClaw?
A: We use Distributed NVMe Caching. Model weights are pre-staged in local high-speed buffers, reducing model load times from 60 seconds to under 5 seconds, ensuring your agents remain responsive.
Q: Can I monitor OpenClaw-specific metrics on WhaleFlux?
A: Yes. Our Full-stack AI Observability integrates with common agent frameworks to track Token-to-Token (TBT)latency and Input-Output Ratios, giving you a granular view of your operational efficiency.
Beyond the Chatbot: Why 2026 is the Year of Autonomous AI Agents
For the past few years, the narrative of Artificial Intelligence has been dominated by a single interface: the chat box. From the viral breakout of LLMs in late 2022 to the enterprise rush of 2024, the world became obsessed with “Generative AI”—the ability of a machine to answer questions, write emails, and summarize documents.
However, as we move through 2026, the novelty of “chatting” has worn off. Enterprise leaders have realized that while a chatbot can tell you how to solve a problem, it cannot actually solve it for you.
The industry has reached a massive inflection point. We are shifting from Passive AI (tools that wait for a prompt) to Autonomous AI Agents (systems that act on goals). This transition represents the most significant leap in productivity since the invention of the internet.
1. The Great Evolution: From Copilots to Autopilots
To understand why 2026 is the definitive year of the Agent, we must look at the limitations of the previous era. In 2024 and 2025, we used “Copilots.” These were helpful assistants that sat beside us, offering suggestions. But the cognitive load remained on the human. The human had to prompt, verify, copy-paste, and trigger the next step.
Autonomous Agents change the equation. An Agent doesn’t just generate text; it executes workflows. If you tell an Agent, “Research this competitor, summarize their pricing, and update our sales deck,” it doesn’t just give you a paragraph of text. It logs into web browsers, parses PDFs, opens your presentation software, and modifies the slides.
Key Characteristics of 2026 Agents:
- Reasoning over Retrieval: They don’t just find information; they weigh options and make logical choices.
- Tool Use: They have “hands.” They can use APIs, legacy software, and internal databases.
- Long-term Memory: They remember past interactions and institutional context, evolving as your business grows.
- Self-Correction: If a step fails, an agent doesn’t just stop; it tries a different path to reach the goal.
2. The Infrastructure Gap: Why Most Enterprises Struggle
While the vision of autonomous agents is compelling, many organizations hit a “performance wall” when trying to deploy them at scale. Agents are computationally expensive and architecturally complex. Unlike a simple chatbot, an agent might require dozens of recursive model calls to complete a single task.
This is where the underlying infrastructure becomes the “make or break” factor. You cannot run a fleet of autonomous digital workers on fragmented, unmonitored systems.
This is precisely where WhaleFlux enters the picture. As an integrated AI platform, WhaleFlux provides the “central nervous system” required for these agents to thrive. By unifying High-Performance Compute with Agent Orchestration and Full-Stack Observability, WhaleFlux ensures that agents aren’t just “smart,” but are also stable, fast, and cost-effective.
3. The Three Pillars of the Autonomous Era
To successfully transition to an agentic workflow in 2026, businesses are focusing on three core technological pillars:
I. Agentic Orchestration (The Brain)
The complexity of 2026 agents lies in “Multi-Agent Systems” (MAS). Instead of one giant model trying to do everything, specialized agents work together. One agent acts as the Manager, another as the Researcher, and a third as the Coder.
- WhaleFlux Impact: The WhaleFlux Agent Platform allows teams to visually orchestrate these complex interactions, ensuring that the “hand-off” between different AI agents is seamless and secure.
II. Dynamic Compute Scaling (The Muscle)
Autonomous agents are unpredictable. A simple task might take 2 seconds of GPU time; a complex strategic analysis might take 2 hours of intense recursive processing. Traditional fixed-resource servers cannot handle this volatility.
- WhaleFlux Impact: With WhaleFlux’s Intelligent Scheduling, GPU resources are dynamically allocated in real-time. This “Smart Dispatch” ensures that your agents always have the “muscle” they need to finish a task without wasting expensive idle compute during downtime.
III. Deep Observability (The Vision)
In the era of chatbots, if a prompt went wrong, you just saw a weird answer. In the era of agents, if an agent goes wrong, it might delete the wrong file or send an incorrect invoice. Observability is no longer optional; it is a safety requirement.
- WhaleFlux Impact: WhaleFlux provides a “glass-box” view into AI operations. Every decision an agent makes, every API it calls, and every cent of compute it consumes is tracked. This allows developers to debug the “thought process” of an agent, ensuring reliability in production environments.
4. Industry Use Cases: Agents in Action
How is the “Year of the Agent” actually manifesting across different sectors?
Manufacturing: The Autonomous Supply Chain
In 2026, manufacturers are using agents to handle supply chain disruptions. When a shipment is delayed, an agent automatically scans alternative suppliers, compares prices, checks for technical compatibility in engineering manuals, and drafts a procurement order for human approval.
Finance: From Analysis to Action
In the financial sector, WhaleFlux-powered agents are moving beyond simple risk reports. They now perform “Active Hedging”—monitoring global news feeds and execution-ready models to suggest and initiate trade adjustments within pre-set safety parameters.
Healthcare: The Clinical Agent
Clinical agents are now managing the administrative burden of doctors. They don’t just transcribe notes; they cross-reference patient data with the latest medical journals, flag potential drug interactions, and pre-fill insurance authorizations, allowing doctors to spend 80% more time with patients.
5. Overcoming the “Agentic Bottleneck”
Despite the excitement, two major hurdles remain for the average enterprise: Data Sovereignty and Cost Management.
Many leaders fear that by deploying agents, they are losing control of their data or opening an “infinite tab” of API costs.
WhaleFlux solves this through Private Intelligence. By supporting private, on-premise, or hybrid cloud deployments, WhaleFlux ensures that your “Digital Workers” stay within your firewall. Your proprietary data never leaves your environment to train someone else’s model. Furthermore, by optimizing the underlying GPU utilization, WhaleFlux helps companies reduce their total cost of ownership by up to 70% compared to unmanaged cloud instances.
6. The Future: A World of “Digital Colleagues”
As we look toward the second half of 2026 and beyond, the boundary between “software” and “employee” will continue to blur. We aren’t just building tools; we are building a digital workforce.
The winners of this era won’t necessarily be the companies with the biggest models, but the companies with the best-orchestrated environments. Success requires a platform that can handle the “heavy lifting” of the AI stack—from the silicon layer to the application layer.
Conclusion: Are You Ready to Scale?
The shift from chatbots to autonomous agents is inevitable. The question is whether your infrastructure is ready to support the load.
If you are still managing AI in silos—buying compute here, hosting models there, and trying to build agents in a vacuum—you will likely face the “complexity trap.”
WhaleFlux was built for this exact moment. By providing a unified, high-performance, and observable environment, WhaleFlux enables you to stop “chatting” with AI and start working with it.
2026 is the year the agents take off. Don’t let your infrastructure be the thing that holds them back.
How to Build a Knowledge Base That Your AI Can Actually Use
Imagine an AI assistant that can instantly answer a new engineer’s complex question about a legacy codebase, a sales rep’s query about a specific customer contract clause, or a support agent’s need for the resolution steps to a rare technical fault. This isn’t about a smarter chatbot; it’s about equipping your AI with a functional, purpose-built knowledge base.
Most company “knowledge bases” are built for humans—wikis, document folders, and intranets filled with PDFs and slides. For an AI, these are dark forests of unstructured data. To make your AI truly powerful, you must build a knowledge base it can search, understand, and reason with. This guide walks you through the actionable steps to create one.
The Core Principle: From Human-Readable to Machine-Understandable
The fundamental shift lies in moving from documents stored for retrieval by humans to data structured for retrieval by machines. A human can skim a 50-page manual to find a detail; an AI cannot. Your goal is to pre-process knowledge into bite-sized, semantically rich pieces and store them in a way that enables millisecond-scale, context-aware search.
This process is best enabled by a Retrieval-Augmented Generation (RAG) architecture. In a RAG system, a user’s query triggers an intelligent search through your processed knowledge base to find the most relevant information. This “grounding” context is then fed to a Large Language Model (LLM), which generates an accurate, sourced answer. Your knowledge base is the fuel for this engine.
Phase 1: Planning & Knowledge Acquisition
1. Define the Scope and “Job-to-be-Done”:
Start narrow. Ask: What specific problem should this AI solve? Is it for technical support, accelerating new hire onboarding, or providing R&D with past research insights? A clearly defined scope, like “answer questions from our product API documentation and past support tickets,” determines what knowledge you need to gather.
2. Identify and Gather Knowledge Sources:
With your scope defined, audit and consolidate knowledge from:
- Structured Sources: Database schemas, organized API documentation, product catalogs.
- Semi-Structured Sources: Emails, presentation slides, CSV reports, marked-up documents.
- Unstructured Sources (the largest category): Word documents, PDF manuals, meeting transcripts, wiki pages, and chat logs.
3. Establish a Governance and Update Cadence:
A knowledge base rots. Decide at the outset: who owns the content? How are updates (new product specs, updated policies) ingested? An automated weekly sync from a designated source-of-truth repository is far more sustainable than manual uploads.
Phase 2: Processing & Structuring for AI (The Technical Core)
This is where raw data becomes AI-ready fuel. Think of it as preparing a library: you don’t just throw in books; you catalog, index, and shelve them.
Step 1: Chunking
You cannot feed a 100-page PDF to an AI. Chunking breaks text into logically segmented pieces. The art is balancing context with size.
- Method: Use semantic chunking (splitting at natural topic boundaries) or recursive chunking (splitting by characters/words, then overlapping chunks to preserve context).
- Tool: Libraries like LangChain’s text splitters or LlamaIndex’s node parsers automate this.
Step 2: Embedding and Vectorization
This is the magic that makes search intelligent. An embedding model converts each text chunk into a vector—a long list of numbers that captures its semantic meaning. Sentences about “server latency troubleshooting” will have mathematically similar vectors, distinct from those about “annual leave policy.”
- Tool: Use open-source models (e.g.,
all-MiniLM-L6-v2) or cloud APIs (OpenAI, Cohere). The choice balances cost, speed, and accuracy.
Step 3: Storing in a Vector Database
These vectors, paired with their original text (metadata), are stored in a specialized vector database. This database performs similarity search: when a query comes in, it’s vectorized, and the database finds the stored vectors closest to it in meaning—not just matching keywords.
- Popular Options: Pinecone (managed), Weaviate (open-source), or pgvector (PostgreSQL extension).
Phase 3: Integration, Deployment & Iteration
1. Building the Retrieval and Query Pipeline:
This is your application logic. It must:
- Take a user query.
- Process and vectorize it.
- Query the vector database for the top-k relevant chunks.
- Format these chunks and the original query into a coherent prompt for the LLM.
- Send the prompt to the LLM and return the answer, ideally with citations.
2. Choosing and Running the LLM:
The LLM is the reasoning engine. You have two main paths:
API Route (Simplicity):
Use GPT-4, Claude, or another API. It’s easy to start but raises concerns about data privacy, cost at scale, and lack of customization.
Self-Hosted Route (Control & Customization):
Run an open-source model like Llama 2, Mistral, or a fine-tuned variant on your infrastructure. This offers data sovereignty and long-term cost control but introduces significant infrastructure complexity.
Here is where a specialized AI infrastructure platform becomes critical.
Managing a performant, self-hosted LLM for a production knowledge base requires robust GPU resources. WhaleFluxdirectly addresses this challenge. It is an integrated AI services platform designed to streamline the deployment and management of private LLMs. Beyond providing optimized access to the full spectrum of NVIDIA GPUs—from H100 and H200 for high-throughput training and inference to A100 and RTX 4090 for cost-effective development—WhaleFlux intelligently manages multi-GPU clusters. Its core value lies in maximizing GPU utilization, which dramatically lowers cloud compute costs while ensuring the high speed and stability necessary for a responsive, enterprise-grade AI knowledge system. By handling the operational burden of GPU orchestration, model serving, and AI observability, WhaleFlux allows your team to focus on refining the knowledge retrieval logic and user experience, not on infrastructure headaches.
3. Iteration and Optimization:
Launch is just the beginning. You must:
Monitor:
Track query logs. Are answers accurate? Which queries return poor results?
Evaluate:
Use metrics like retrieval precision (did it fetch the right chunks?) and answer faithfulness (is the answer grounded in the chunks?).
Refine:
Adjust chunk sizes, tweak embedding models, add metadata filters (e.g., “search only in v2.1 documentation”), or fine-tune the LLM’s instructions for better answers.
Conclusion: The Strategic Asset
Building an AI-usable knowledge base is a technical implementation and a strategic initiative to institutionalize your company’s knowledge. It transforms static information into an active, conversational asset that scales expertise, ensures consistency, and accelerates decision-making.
By following this blueprint—from focused planning and meticulous data processing to robust deployment with the right infrastructure—you move beyond experimenting with AI to operationalizing it. You stop asking your AI what it knows and start telling it what your companyknows. That is the foundation of true competitive advantage.
FAQ: Building an AI-Powered Knowledge Base
Q1: What are the first three steps to start building a knowledge base for my AI?
A: Start with a tight, well-defined use case (e.g., “answer internal HR policy questions”). Then, identify and gather all relevant source documents for that use case. Finally, design a simple, automated pipeline to keep this source data updated. Starting small ensures manageable complexity and clearer success metrics.
Q2: What’s the key difference between a traditional search-based knowledge base (like a wiki) and an AI-ready one?
A: A traditional wiki relies on keyword matching and depends on the user to formulate the right query and sift through results. An AI-ready knowledge base uses semantic search via vector embeddings, allowing the AI to understand the meaning behind a query. It actively retrieves relevant information to construct a direct, conversational answer, not just a list of links.
Q3: What is the biggest technical challenge in building this system?
A: One of the most significant challenges is the end-to-end integration and performance optimization of the pipeline. Ensuring low-latency retrieval from the vector database combined with fast, stable inference from a large language model requires careful engineering and powerful, well-managed infrastructure, particularly for self-hosted models. Bottlenecks in any component can ruin the user experience.
Q4: We want data privacy and plan to self-host our LLM. What infrastructure should we consider?
A: Self-hosting demands a focus on GPU performance and management. You’ll need to select the right NVIDIA GPU for your model size and user load (e.g., A100 or H100 for large-scale production). The greater challenge is efficiently orchestrating these expensive resources to avoid waste and ensure stability. An integrated AI platform like WhaleFlux is purpose-built for this, providing optimized GPU management, model serving tools, and observability to turn complex infrastructure into a reliable utility.
Q5: Is it very expensive to build and run such a system?
A: Costs vary widely. Using cloud-based LLM APIs has a low upfront cost but can become expensive with high volume. Self-hosting has higher initial infrastructure costs but can be more predictable and cheaper long-term. The key to cost control, especially for self-hosting, is maximizing GPU utilization. Idle or poorly managed compute is the primary source of waste. Platforms that optimize cluster efficiency, like WhaleFlux, are essential for transforming capital expenditure into predictable, value-driven operating costs.
From Static Docs to AI Answers: How RAG Makes Your Company Knowledge Instantly Searchable
The Untapped Goldmine in Your Company
Imagine a new employee asking your company’s AI assistant a complex, niche question: “What was the technical rationale behind the pricing model change for our flagship product in Q3 last year, and what were the projected impacts?” Instead of sifting through hundreds of emails, meeting notes, and PDF reports, they receive a concise, accurate summary in seconds, citing the original strategy memos and financial projections.
This is not a glimpse of a distant future. It’s the reality enabled by Retrieval-Augmented Generation (RAG), a transformative AI architecture that is turning static document repositories into dynamic, conversational knowledge bases. In an era where data is the new currency, RAG is the technology that finally allows businesses to spend it effectively.
Demystifying RAG: The “Retrieve-Read” Revolution
At its core, RAG is a sophisticated framework that marries the depth of understanding of a Large Language Model (LLM) with the precision of a search engine. It solves two critical flaws of standalone LLMs: their reliance on potentially outdated or general training data, and their tendency to “hallucinate” or invent facts when they lack specific information.
The process is elegantly logical, working in three continuous phases:
1. Retrieval:
When a user asks a question, the system doesn’t guess. Instead, it acts like a super-powered librarian. It converts the query into a numerical representation (a vector) and performs a lightning-fast semantic search through a vector database containing your company’s documents—be they PDFs, wikis, or slide decks. It retrieves the chunks of text most semantically relevant to the question.
2. Augmentation:
Here, the magic of context happens. The retrieved, relevant text passages are woven together with the user’s original question into a new, enriched prompt. Think of it as giving the AI a curated dossier of background information before it answers.
3. Generation:
Finally, this augmented prompt is fed to the LLM. Now instructed with verified, internal company data, the model generates a response that is not only coherent and linguistically fluent but, most importantly, grounded in your proprietary facts. It cites the source material, drastically reducing inaccuracies.
From Chaos to Clarity: Real-World Applications
The shift from keyword search to answer generation is profound. Employees no longer need to know the exact filename or jargon; they can ask naturally.
Supercharged Customer Support:
Agents receive AI-synthesized answers from the latest product manuals, engineering change logs, and past support tickets, slashing resolution times and ensuring consistency.
Accelerated R&D and Onboarding:
New engineers can query the entire history of design decisions. Legal and compliance teams can instantly cross-reference policies against new regulations.
Informed Decision-Making:
Executives can request a synthesis of market analysis, internal performance data, and competitor intelligence from the past quarter to prepare for a board meeting.
The business value is clear: dramatic gains in operational efficiency, risk mitigation through accurate information, and unlocking the latent value trapped in decades of digital documentation.
Tackling the RAG Implementation Challenge: The Infrastructure Hurdle
However, building a responsive, reliable, and scalable RAG system is not just a software challenge—it’s a significant infrastructure and operational hurdle. The two core components are computationally demanding:
The Vector Search Database:
This system must perform millisecond-level similarity searches across billions of document vectors. While this itself requires optimized compute, the greater burden often lies in the next stage.
The Large Language Model (LLM):
This is where the real computational heavy lifting occurs. Running an inference-optimized LLM (like a 70B parameter model) to generate high-quality, low-latency answers requires powerful, and often multiple, GPUs with substantial high-bandwidth memory (HBM).
The GPU Dilemma: Choosing the right GPU is critical. Do you opt for the raw inference power of an NVIDIA H100, the massive 141GB memory of an H200 for loading enormous models, or the cost-effective balance of an A100? This decision impacts everything from answer speed to how many concurrent users you can support. Mismatched or under-resourced hardware leads to slow, frustrating user experiences that doom adoption.
Furthermore, managing a GPU cluster—scheduling jobs, monitoring health, optimizing utilization across different teams (e.g., R&D training vs. live RAG inference)—becomes a full-time DevOps nightmare. Idle GPUs waste immense capital, while overloaded ones create performance bottlenecks. This is where the journey from a promising prototype to a robust enterprise system often stalls.
Introducing WhaleFlux: Your AI Infrastructure Catalyst
This is precisely the challenge WhaleFlux is designed to solve. WhaleFlux is not just another cloud GPU provider; it is an intelligent, integrated AI platform built to remove the core infrastructure barriers that slow down AI deployment, including sophisticated RAG systems.
For companies implementing RAG, WhaleFlux delivers decisive advantages:
Optimized GPU Resource Management:
WhaleFlux’s core intelligence lies in its sophisticated scheduler that optimizes utilization across multi-GPU clusters. It ensures your RAG inference engine has the dedicated, right-sized power it needs—whether that’s a fleet of NVIDIA RTX 4090s for development or a cluster of H100s for production—without wasteful idle time, directly lowering compute costs.
Full-Spectrum NVIDIA GPU Access:
WhaleFlux provides flexible access to the entire lineup of NVIDIA data center GPUs. You can select the perfect tool for each job: H200s for memory-intensive models with massive context windows, H100s for ultimate throughput, or A100s for a proven balance of performance and value. This allows you to architect your RAG system with the right computational foundation.
Beyond Hardware: An Integrated AI Platform:
WhaleFlux understands that deployment is more than hardware. The platform integrates essential services like AI Observability for monitoring your RAG pipeline’s health and latency, and tools for managing AI Agents and models. This integrated approach provides the stability and speed necessary for enterprise-grade RAG, transforming it from a fragile demo into a mission-critical utility.
By handling the complexity of infrastructure, WhaleFlux allows your team to focus on what matters most: refining your knowledge base, improving retrieval accuracy, and building incredible user experiences that make your company’s collective intelligence instantly accessible.
The Future Is Conversational
The transition from static documents to interactive AI answers represents a fundamental leap in how organizations leverage knowledge. RAG provides the blueprint, turning information archives into active participants in decision-making and innovation.
The path forward involves thoughtful design of your knowledge ingestion pipelines, continuous refinement of your prompts, and—as discussed—a strategic approach to the underlying computational engine. With the infrastructure complexity expertly managed by platforms like WhaleFlux, businesses can confidently deploy these systems, ensuring that their most valuable asset—their collective knowledge—is no longer at rest, but actively powering their future.
FAQ: RAG and AI Infrastructure
Q1: What exactly is RAG in simple terms?
A: RAG (Retrieval-Augmented Generation) is an AI technique that first “looks up” relevant information from your specific company documents (like a super-smart search) and then uses that found information to write a precise, sourced answer. It prevents the AI from making things up by grounding its responses in your actual data.
Q2: What’s the main business advantage of RAG over a standard chatbot?
A: The key advantage is accuracy and relevance. A standard chatbot relies only on its pre-trained, general knowledge, which may be outdated or lack your proprietary information, leading to errors. RAG pulls from your live, internal knowledge base, ensuring answers are factual, current, and specific to your business context.
Q3: Why is GPU choice so important for running a RAG system?
A: The LLM that generates answers is computationally intensive. A powerful GPU like an NVIDIA H100 or A100 provides the speed (high teraflops) and memory bandwidth to deliver quick, low-latency responses. For very large knowledge bases or models, GPUs with more high-bandwidth memory (like the H200) are crucial to hold all the necessary data for accurate, context-rich answers.
Q4: How does WhaleFlux specifically help with AI projects like RAG?
A: WhaleFlux tackles the major operational hurdles. It provides optimized access to top-tier NVIDIA GPUs (like H100, H200, A100) and intelligently manages them to maximize efficiency and minimize cost. More than just hardware, its integrated platform includes AI Observability and management tools, ensuring your RAG deployment is stable, performant, and scalable without requiring you to become a full-time infrastructure expert.
Q5: We’re interested in RAG. Where should we start?
A: Start small but think strategically.
1. Identify a Pilot Use Case:
Choose a specific, high-value knowledge domain (e.g., product support docs, internal process wikis).
2. Design Your Pipeline:
Plan how to chunk, index, and update your documents into a vector database.
3. Plan for Infrastructure:
Consider performance requirements (user concurrency, response time) and evaluate if your current hardware can meet them. This is where exploring a managed solution like WhaleFlux early on can prevent future bottlenecks and accelerate your time-to-value.
4. Iterate and Refine:
Continuously test the quality of retrievals and generated answers, refining your prompts and data processing steps.
How RAG Supercharges Your AI with a Live Knowledge Base
Imagine an AI that doesn’t just generate eloquent text based on its training data, but one that can instantly reference your company’s latest reports, answer specific questions about yesterday’s meeting notes, or provide accurate customer support based on real-time policy changes. This isn’t science fiction; it’s the reality made possible by Retrieval-Augmented Generation (RAG) powered by a live knowledge base. This powerful combination is transforming how enterprises deploy AI, moving from static, sometimes inaccurate chatbots to dynamic, informed, and trustworthy intelligent agents.
The Limitations of Traditional LLMs
Large Language Models (LLMs) are remarkable knowledge repositories, but they come with inherent constraints:
Static Knowledge:
Their knowledge is frozen at the point of their last training cut-off. They are oblivious to recent events, new products, or internal company developments.
Hallucinations:
When asked about information beyond their training data, they may generate plausible-sounding but incorrect or fabricated answers.
Lack of Source Grounding:
Traditional LLM responses don’t cite sources, making it difficult to verify the origin of the information, a critical requirement in business and legal contexts.
Domain Blindness:
Generic models lack deep, specific knowledge of proprietary internal data, industry jargon, or confidential company processes.
These limitations create significant risks and reduce the utility of AI for mission-critical business applications. This is where RAG comes to the rescue.
What is RAG and How Does It Work?
Retrieval-Augmented Generation (RAG) is a hybrid architecture that elegantly marries the creative and linguistic prowess of an LLM with the precision and dynamism of an external knowledge base.
Think of it as giving your AI a powerful, constantly-updated reference library and teaching it how to look things up before answering.
Here’s a simplified breakdown of the RAG process:
1. The Live Knowledge Base:
This is the cornerstone. It can be any collection of documents—PDFs, Word docs, Confluence pages, Slack channels, SQL databases, or real-time data streams. The key is that this base is live; it can be updated, amended, and expanded at any moment.
2. Indexing & Chunking:
The documents are broken down into manageable “chunks” (e.g., paragraphs or sections). These chunks are then converted into numerical representations called embeddings—dense vectors that capture the semantic meaning of the text. These embeddings are stored in a specialized, fast-retrieval database known as a vector database.
3. The Retrieval Step:
When a user asks a question (the query), it too is converted into an embedding. The system performs a lightning-fast similarity search across the vector database to find the chunks whose embeddings are most semantically relevant to the query.
4. The Augmented Generation Step:
The retrieved, relevant text chunks are then packaged together with the original user query and fed into the LLM as context. The instruction to the LLM is essentially: “Using only the provided context below, answer the user’s question. If the answer is not in the context, say you don’t know.”
This elegant dance between retrieval and generation solves the core problems:
- Accuracy & Freshness: Answers are grounded in the live knowledge base, ensuring they are current and factual.
- Reduced Hallucinations: By constraining the LLM to the provided context, fabrications plummet.
- Source Citation: The system can easily provide references to the exact documents and passages used, building trust and enabling verification.
- Customization: The AI’s expertise is defined by the documents you provide, making it an instant expert on your unique domain.
Building Your Live Knowledge Base: The Technical Core
The “live” aspect of RAG is what makes it transformative for businesses. Implementing it requires careful consideration:
Data Ingestion Pipeline:
A robust, automated pipeline is needed to continuously ingest data from various sources (APIs, cloud storage, internal databases, web scrapers). Tools like Apache Airflow or Prefect can orchestrate this flow.
Embedding Models:
The choice of model (e.g., OpenAI’s text-embedding-ada-002, open-source models like BGE-M3 or Snowflake Arctic Embed) significantly impacts retrieval quality. It must align with your language and domain.
Vector Database:
This is the workhorse. Systems like Pinecone, Weaviate, or Milvus are built to handle millions of vectors and perform sub-second similarity searches, even under heavy load. They must support constant, real-time updates without performance degradation.
The LLM:
The final generator. This can be a proprietary API (GPT-4, Claude) or a self-hosted open-source model (Llama 3, Mistral). The choice here balances cost, latency, data privacy, and control.
The Computational Challenge: Why RAG Demands Serious GPU Power
Running a live RAG system at enterprise scale is computationally intensive. The process is not a single API call but a cascade of operations:
Query Embedding:
Encoding the user’s question in real-time.
Vector Search:
A high-dimensional nearest-neighbor search across millions of vectors.
LLM Context Processing:
The generator LLM must now process a much larger input context (the original prompt plus the retrieved passages), which drastically increases the computational load compared to a simple query. This is where inference speed and stability become critical for user experience.
Deploying and managing the necessary infrastructure—especially for the embedding models and the LLM—requires significant GPU resources. This is often the hidden bottleneck that slows down AI deployment and inflates costs.
This is precisely where a platform like WhaleFlux becomes a strategic accelerator.
WhaleFlux is an intelligent GPU resource management platform designed specifically for AI enterprises. It optimizes the utilization of multi-GPU clusters, allowing businesses to run demanding RAG workloads—from embedding generation to large-context LLM inference—more efficiently and cost-effectively. By intelligently orchestrating workloads across a fleet of powerful NVIDIA GPUs(including the latest H100, H200, and A100, as well as versatile options like the RTX 4090), WhaleFlux ensures your live knowledge base is not just smart, but also fast and reliable. It simplifies deployment, maximizes hardware efficiency, and provides the observability tools needed to keep complex AI systems running smoothly. For companies building mission-critical RAG systems, such infrastructure optimization is not a luxury; it’s a necessity for maintaining a competitive edge.
Real-World Superpowers: Use Cases
A RAG system with a live knowledge base unlocks transformative applications:
Dynamic Customer Support:
A support bot that instantly knows about the latest product update, a just-issued service bulletin, or a specific customer’s contract details, providing accurate, personalized answers.
Corporate Intelligence & Onboarding:
New employees can query an AI that knows all HR policies, recent project documentation, and team directories, drastically reducing ramp-up time.
Real-Time Financial & Market Analysis:
An analyst can ask, “Summarize the risks mentioned in our last five earnings call transcripts,” with the AI pulling and synthesizing information from the most recent documents.
Healthcare Diagnostics Support:
A system that augments a doctor’s knowledge by retrieving the latest medical research, clinical guidelines, and similar patient case histories in seconds.
Conclusion
RAG with a live knowledge base is more than a technical upgrade; it’s a paradigm shift for enterprise AI. It moves AI from being a gifted but unreliable storyteller to a precise, knowledgeable, and up-to-date expert consultant. It bridges the gap between the vast, static knowledge of pre-trained models and the dynamic, specific needs of a business.
While the architectural design is crucial, its real-world performance hinges on robust, scalable, and efficient computational infrastructure. Building this intelligent, responsive “second brain” for your AI requires not just smart software, but also powerful and wisely managed hardware. By combining the RAG architecture with a platform like WhaleFlux for optimal GPU resource management, enterprises can truly supercharge their AI initiatives, unlocking unprecedented levels of accuracy, relevance, and operational efficiency.
5 FAQs on RAG and Live Knowledge Bases
1. What’s the main advantage of RAG over just fine-tuning an LLM on my data?
Fine-tuning teaches the LLM how to speak in a certain style or about certain topics from your data, but it doesn’t reliably add new factual knowledge and is expensive to update. RAG, on the other hand, directly provides the LLM with the specific facts it needs from your live knowledge base at the moment of query. This makes RAG superior for dynamic information, source citation, and reducing hallucinations, as the model’s core knowledge isn’t altered.
2. How “live” can the knowledge base truly be?
The latency depends on your ingestion pipeline. If your system is connected to a real-time data stream (e.g., a news feed or transaction log), and your vector database supports real-time updates, the “retrieval” step can access information that was added milliseconds ago. For most business applications, updates on an hourly or daily basis are sufficiently “live” to provide a major advantage over static models.
3. Isn’t this just a fancy search engine?
It’s a significant evolution. A search engine returns a list of documents. A RAG system understandsthe question, finds the most relevant information within those documents, and then synthesizes a coherent, natural language answer based on that information. It completes the last mile from information retrieval to knowledge delivery.
4. What are the biggest challenges in building a production RAG system?
Key challenges include: designing an effective chunking strategy for your documents, ensuring the retrieval quality is high (poor retrieval leads to poor answers), managing the latency of the multi-step process, handling document updates and deletions in the vector index, and scaling the computationally expensive LLM inference to handle the augmented context prompts reliably.
5. How can WhaleFlux help in deploying and running such a system?
WhaleFlux addresses the core infrastructure challenges. Deploying the embedding models and LLMs required for a responsive RAG system demands powerful, scalable GPU resources. WhaleFlux optimizes the utilization of NVIDIA GPU clusters (featuring the H100, A100, and other high-performance models), ensuring your inference runs fast and stable while controlling cloud costs. Its platform provides the management, observability, and efficiency needed to take a RAG proof-of-concept into a high-traffic, mission-critical production environment.
Building a “Knowledge Base” It Can Actually Use
In the race to deploy powerful AI, many organizations focus overwhelmingly on model selection—scouring the latest benchmarks for the largest, most sophisticated large language model (LLM). Yet, even the most advanced model, when deployed in isolation, often disappoints. It hallucinates facts, struggles with domain-specific queries, and fails to leverage the organization’s most valuable asset: its proprietary data. The true differentiator isn’t just the model itself; it’s the specialized knowledge base you build for it.
Think of your AI as an immensely talented but generalist new hire. Without access to the company drive, past project reports, customer feedback logs, and technical manuals, its usefulness is severely limited. A knowledge base equips your AI with this context, transforming it from a generic chatterbox into a precise, informed, and reliable expert tailored to your business.
But building a knowledge base your AI can actually use—one that consistently delivers accurate, relevant, and actionable insights—is a significant engineering challenge. It’s more than just dumping documents into a folder. It requires a strategic architecture designed for machine understanding, seamless integration, and scalable performance.
The “Why”: Beyond the Hype of Raw Model Power
Why is a knowledge base non-negotiable?
Curbing Hallucinations:
LLMs are probabilistic pattern generators. Without grounded, verifiable sources, they confidently invent answers. A knowledge base provides the “source of truth” that the model can retrieve from, citing real documents and data, thereby dramatically improving accuracy and trustworthiness.
Enabling Domain Expertise:
Your competitive edge lies in what you know that others don’t. A knowledge base infused with your proprietary research, product specs, and internal processes allows your AI to operate at expert levels in your niche.
Dynamic Information Access:
Unlike static, fine-tuned models that become outdated, a well-architected knowledge base can be updated in near real-time. New pricing sheets, updated regulations, or the latest support tickets can be made instantly available to the AI.
Cost and Efficiency:
Constantly retraining or fine-tuning massive models on new data is prohibitively expensive and slow. A retrieval-augmented generation (RAG) approach, which pairs a model with a dynamic knowledge base, is a far more agile and cost-effective way to keep your AI current.
The “How”: Blueprint for an Actionable Knowledge Base
Building an effective system involves several key pillars:
1. Ingestion & Processing: From Chaos to Structure
This is the foundational step. You must gather data from all relevant sources: PDFs, Word docs, Confluence pages, Salesforce records, database exports, and even structured data from APIs. The magic happens in processing: chunking text into semantically meaningful pieces, extracting metadata (source, author, date), and converting everything into a unified format. The goal is to break down information silos and create a normalized pool of “knowledge chunks.”
2. Vectorization & Embedding: The Language of AI
For an AI to “understand” and retrieve text, it needs a numerical representation. This is where embedding models come in. Each text chunk is converted into a high-dimensional vector (a list of numbers) that captures its semantic meaning. Sentences about “quarterly sales targets” and “Q3 revenue goals” will have vectors that are mathematically close to each other in this “vector space,” even if the wording differs.
3. The Vector Database: The AI’s Memory Core
These vectors are stored in a specialized database optimized for similarity search—the vector database. When a user asks a question, that query is also vectorized. The database performs a lightning-fast search to find the stored vectors (knowledge chunks) that are most semantically similar to the query. This is the core retrieval mechanism.
4. Retrieval Augmented Generation (RAG): The Intelligent Synthesis
In a RAG pipeline, the retrieved relevant chunks are not the final answer. They are passed as context, along with the original user query, to the LLM (e.g., an OpenAI model or an open-source Llama 2/3 variant running in-house). The system instructs the model: “Using only the following context, answer the question…” The LLM then synthesizes a coherent, natural-language answer grounded in the provided sources. This combines the precision of retrieval with the linguistic fluency of generation.
5. Infrastructure: The Often-Overlooked Engine
This entire pipeline—running embedding models, querying vector databases, and hosting the inference engine for the LLM—demands serious, scalable computational power, particularly from GPUs. The embedding and inference stages are intensely parallelizable tasks that run orders of magnitude faster on GPUs. However, managing a multi-GPU cluster efficiently is a major operational hurdle. Under-provision, and your knowledge base responds sluggishly, crippling user experience. Over-provision, and you hemorrhage money on idle cloud GPUs. The stability of your GPU resources directly impacts the reliability and speed of your AI’s access to its knowledge.
Here is where a specialized tool can become a secret weapon in its own right. ConsiderWhaleFlux, a smart GPU resource management platform designed for AI enterprises. WhaleFlux optimizes the utilization of multi-GPU clusters, ensuring that the computational heavy-lifting behind your knowledge base—from embedding generation to LLM inference—runs efficiently and stably. By dynamically managing workloads across a fleet of NVIDIA GPUs (including the H100, H200, A100, and RTX 4090), it helps drastically reduce cloud costs while accelerating deployment cycles. WhaleFlux is more than just GPU management; it’s an integrated platform that also provides AI Model services, Agent frameworks, and Observability tools, offering a cohesive environment to build, deploy, and monitor sophisticated AI applications like a RAG-powered knowledge base. For companies needing tailored solutions, WhaleFlux further offers customized AI services, providing the flexible, powerful infrastructure foundation that makes advanced AI projects practically and economically viable.
6. Continuous Iteration: The Feedback Loop
Launching is just the beginning. You need observability tools to monitor: What queries are failing? Which retrieved documents are rated as helpful? Where is the model still hallucinating? This feedback loop is essential for curating your knowledge base, refining chunking strategies, and improving overall system performance.
Best Practices for Success
- Start with a High-Value, Contained Domain: Don’t boil the ocean. Begin with a specific department’s knowledge (e.g., HR policies or product support) to prove value and iterate.
- Prioritize Data Quality: Garbage in, garbage out. Clean, well-structured source documents yield vastly better results than messy scans or inconsistent formats.
- Implement Robust Access Controls: Your knowledge base will contain sensitive information. The retrieval system must respect user permissions, ensuring individuals only access chunks they are authorized to see.
- Cite Your Sources: Always design your AI’s responses to explicitly reference the documents it used. This builds user trust and allows for easy verification.
Conclusion
Your AI’s ultimate capability is not determined solely by the model you license, but by the quality, architecture, and accessibility of the knowledge you connect it to. Building a dynamic, well-engineered knowledge base moves AI from a fascinating experiment to a core operational asset. It turns generic intelligence into proprietary expertise. By combining a strategic RAG architecture with a powerful and efficiently managed infrastructure—the kind that platforms like WhaleFlux enable—you provide your AI with the secret weapon it needs to truly deliver on its transformative promise. The future belongs not to the organizations with the biggest AI models, but to those who can most effectively teach their AI what they know.
FAQs: Building an AI-Powered Knowledge Base
Q1: What’s the main difference between fine-tuning an LLM and using a RAG (Retrieval-Augmented Generation) system with a knowledge base?
A: Fine-tuning adjusts the model’s internal weights on a specific dataset, making it better at a style or domain but “locking in” knowledge at the time of training. It’s expensive to update. RAG keeps the general model unchanged but dynamically retrieves relevant information from an external knowledge base for each query. This allows for real-time updates, provides source citations, and is generally more cost-effective for leveraging proprietary data.
Q2: We have terabytes of documents. Is building a knowledge base too expensive and complex?
A: The complexity and cost are front-loaded in the design and infrastructure phase. Start with a focused, high-ROI subset of data to validate the pipeline. The long-term operational cost, especially using an efficient RAG approach, is typically much lower than constantly fine-tuning large models. Strategic use of GPU resources, managed through platforms like WhaleFlux, is key to controlling inference costs and ensuring scalable performance as your knowledge base grows.
Q3: Can the knowledge base handle highly structured data (like databases) alongside unstructured documents?
A: Absolutely. A robust knowledge base architecture can ingest both. Structured data from SQL databases or APIs can be converted into descriptive text chunks (e.g., “Customer [ID] purchased [Product] on [Date]”). When vectorized, this allows the AI to answer precise, data-driven questions by retrieving these structured facts, seamlessly blending them with insights from PDFs or wikis.
Q4: What kind of GPUs are necessary for running a private knowledge base system, and is buying or renting better?
A: The requirement depends on the scale of your knowledge base, user concurrency, and the size of the LLM used for inference. For production systems, NVIDIA GPUs like the A100 or H100 are common for their memory bandwidth and parallel processing power. The buy-vs-rent decision hinges on long-term usage patterns and capital expenditure strategy. Some integrated platforms offer flexible models. For instance, WhaleFlux provides access to a full suite of NVIDIA GPUs (including H100, H200, A100, and RTX 4090), allowing enterprises to procure or lease resources according to their specific needs, providing a middle path that prioritizes efficiency and control.
Q5: How does a tool like WhaleFlux specifically help a knowledge base project?
A: WhaleFlux addresses the critical infrastructure layer. It ensures that the GPU-intensive components of the knowledge base pipeline—embedding models and the LLM inference engine—run on optimally utilized, cost-effective NVIDIA GPU clusters. This directly translates to faster query response times, higher system stability under load, and lower cloud compute bills. Furthermore, as an integrated platform offering AI observability, it provides crucial monitoring tools to track the performance and accuracy of your knowledge base retrievals, creating a complete environment for development and deployment.