Imagine teaching a child. You don’t give them a thousand specialized flashcards for every specific problem they’ll ever encounter. Instead, you teach them fundamental skills—reading, pattern recognition, logical reasoning—that they can then apply to learn new subjects, solve unexpected puzzles, and adapt to novel situations. For decades, much of machine learning has been stuck in the “flashcard” phase: training a massive, specialized model for one very specific task. But what if we could build AI that learns more like the child? This is the promise of two transformative paradigms: Multi-Task Learning (MTL) and Meta-Learning.
These approaches are moving us from models that simply recognize patterns to models that learn how to learn, making AI more efficient, robust, and adaptable. Let’s break down how they work and why they represent a significant leap forward.
Part 1: The Power of Shared Knowledge – Multi-Task Learning
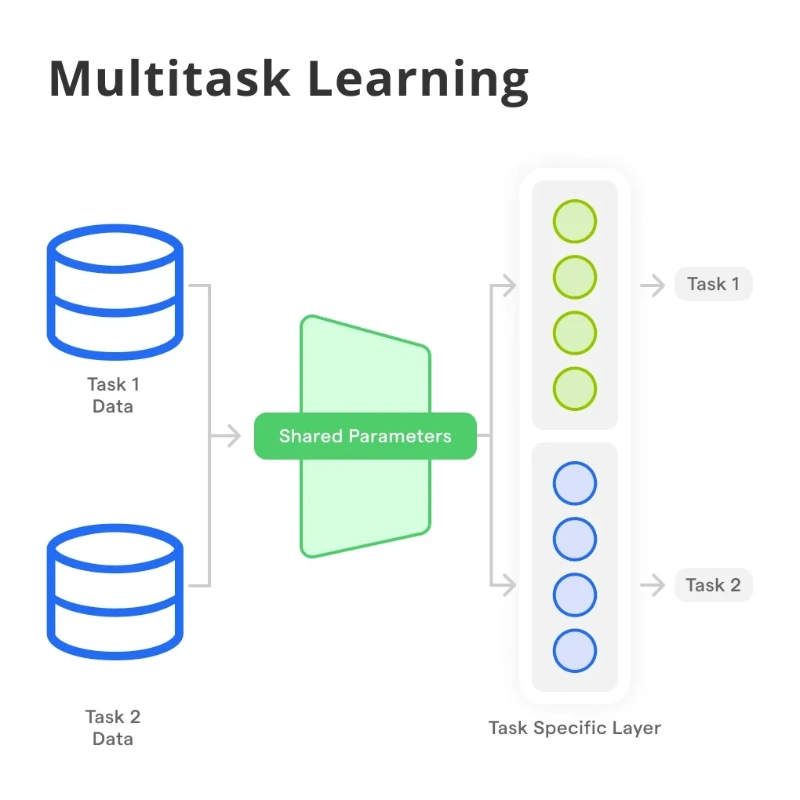
Traditional AI models are specialists. A vision model for detecting pneumonia in X-rays knows nothing about segmenting tumors or identifying fractures. It sees only its own narrow world. Multi-Task Learning challenges this by training a single model on multiple related tasks simultaneously.
The Core Idea: The model shares a common “backbone” of neural network layers that learn general, transferable features. Then, smaller, task-specific “heads” branch off to handle the particulars of each job. Think of it as a medical student studying both cardiology and pulmonology; knowledge of blood circulation informs their understanding of lung function, and vice versa.
How It Works & Key Benefits:
1.Improved Generalization and Reduced Overfitting:
By learning from multiple tasks, the model is forced to find features that are useful across problems. This acts as a powerful regularization, preventing it from latching onto spurious, task-specific noise in the data. It builds a more robust internal representation of the world.
2.Data Efficiency:
A task with limited data (e.g., rare disease detection) can be boosted by co-training with data-rich tasks (e.g., common anatomical feature detection). The model learns from the broader data pool.
3.The “Blessing of Discrepancy”:
Sometimes, tasks provide complementary signals. Learning to predict depth in an image can improve the model’s ability to perform semantic segmentation, as understanding object boundaries aids in estimating distance.
Architectures: Common MTL setups include hard parameter sharing (the shared backbone) and soft parameter sharing (where separate models are encouraged to have similar parameters through regularization). A key challenge is negative transfer—when learning one task hurts another. Modern solutions involve dynamic architectures or loss-balancing algorithms (like Gradient Surgery or uncertainty-based weighting) to manage the learning process across tasks.
Bridging Theory and Practice: The Platform Challenge
Implementing MTL or meta-learning can be complex, requiring careful orchestration of models, tasks, and gradients. This is where integrated platforms become invaluable. For instance, Whaleflux is a unified AI development platform designed to streamline these advanced workflows. It provides the infrastructure and tools to easily design, train, and manage multi-task and meta-learning systems, allowing researchers and engineers to focus on innovation rather than boilerplate code. By abstracting away the complexity of distributed training and dynamic computation graphs, platforms like Whaleflux make these sophisticated learning paradigms more accessible and scalable for real-world applications.
Part 2: Learning the Learning Algorithm – Meta-Learning
If MTL is about learning many tasks at once, meta-learning is about preparing to learn new tasks quickly. It’s often called “learning to learn.” The goal is to train a model on a distribution of tasks so that, when presented with a new, unseen task from that distribution, it can adapt with only a few examples.
The Analogy: You don’t teach someone to assemble 100 specific pieces of furniture. Instead, you teach them how to read any instruction manual, use a screwdriver and a wrench, and understand general assembly principles. Then, when faced with a new bookshelf, they can figure it out quickly.
The Meta-Learning Process (The Inner and Outer Loop):
- Meta-Training: The model is exposed to many different tasks (e.g., classifying different sets of animal species, translating between different language pairs).
- Inner Loop: For each task, the model undergoes a few steps of learning (like a few gradient updates). This is its “fast adaptation” phase.
- Outer Loop: The performance after this fast adaptation is evaluated. Crucially, the meta-learner updates the initial conditions or the learning algorithm itself to make future fast adaptations more effective across all tasks.
Popular Approaches:
- Model-Agnostic Meta-Learning (MAML): This influential algorithm finds a stellar initial set of parameters. From this “golden starting point,” the model can fine-tune to any new task with just a few gradient steps and little data. It’s like finding the perfect posture and grip before learning any specific sport.
- Metric-Based (e.g., Siamese Networks, Prototypical Networks): These learn a clever feature space where examples can be compared. To classify a new example, they compare it to a few labeled “support” examples. This is the engine behind few-shot image classification.
- Optimizer-Based: Here, the meta-learner actually learns the update rule (the optimizer), potentially discovering more efficient learning patterns than stochastic gradient descent for rapid adaptation.
The Synergy and The Future
MTL and meta-learning are deeply connected. MTL can be seen as a specific, static form of meta-learning where the “task” is to perform well on all training tasks simultaneously. Meta-learning takes this further, optimizing for the ability to adapt. In practice, they can be combined: a model can be meta-trained to be a good multi-task learner.
The implications are vast:
- Personalized AI: An educational app that meta-learns from millions of students can adapt to your learning style in minutes.
- Robotics: A robot that can learn to manipulate new objects after seeing just a few demonstrations.
- Sustainable AI: Drastically reducing the need for massive, task-specific datasets and computation, moving toward more sample-efficient and generalizable models.
We are transitioning from the era of the single-task expert model to the era of the adaptive, generalist learner. By embracing multi-task and meta-learning, we are not just building models that perform tasks—we are building models that understand how to acquire new skills, bringing us closer to truly flexible and intelligent systems.
FAQs
1. What’s the key difference between Multi-Task Learning and Meta-Learning?
Multi-Task Learning (MTL) trains a single model to perform multiple, predefined tasks well at the same time, sharing knowledge between them. Meta-Learning trains a model on a variety of tasksso that it can quickly learn new, unseen tasks with minimal data. MTL is about concurrent performance; meta-learning is about preparation for future adaptation.
2. Does Meta-Learning require even more data than traditional AI?
It requires a different kind of data. Instead of one massive dataset for one task, you need many tasks (each with its own dataset) for meta-training. While the total data volume can be large, the power lies in the fact that each new task post-training requires very little data (few-shot learning). The upfront cost enables long-term efficiency.
3. What is “negative transfer” in Multi-Task Learning, and how is it solved?
Negative transfer occurs when learning one task interferes with and degrades performance on another task, often because the tasks are too dissimilar or the model architecture forces unhelpful sharing. Solutions include adaptive architectures (letting the model learn what to share), gradient manipulation techniques (to balance task updates), and weighting losses based on task uncertainty or difficulty.
4. Is Meta-Learning the same as “foundation models” or large language models (LLMs) that can be prompted?
They are related but distinct. Models like GPT are trained on a massive, broad dataset (effectively a multi-task objective at scale) and exhibit impressive few-shot abilities through prompting—a form of in-context learning. This shares the spirit of meta-learning. However, classic meta-learning explicitly optimizes the training process for fast adaptation (e.g., via MAML’s inner/outer loop), whereas LLMs’ few-shot ability emerges from scale and architecture. Meta-learning principles help explain and could further enhance these capabilities.
5. How can I start experimenting with these techniques?
Begin with clear, related tasks for MTL (e.g., object detection and segmentation in images). Use deep learning frameworks like PyTorch or TensorFlow that support flexible model architectures. For meta-learning, start with standard few-shot benchmarks like Omniglot or Mini-ImageNet. Leverage open-source libraries that provide implementations of MAML and other algorithms. For production-scale development, consider using integrated platforms like Whaleflux, which are built to manage the complexity of these advanced training paradigms.