Mastering LLM Inference: A Comprehensive Guide to Inference Optimization
Introduction
Running a state-of-the-art LLM in production is more than just having the right model — it’s like owning a high-performance sports car but being stuck in traffic. The model has the power to generate insights, but without proper inference mechanism, you’re left idling, wasting time and resources. As LLMs grow larger, the inference process becomes the bottleneck that can turn even the most advanced model into a sluggish, expensive system.
Inference optimization is the key to unlocking that potential. It’s not just about speeding things up; it’s about refining the engine — finding the sweet spot between performance and resource consumption to enable scalable, efficient AI applications. In this blog, we will show you how to optimize your LLM inference pipeline to keep your AI running at full throttle. From hardware acceleration to advanced algorithms and distributed computing, optimizing inference is what allows LLMs to get ready for high-demand, real-time tasks.
Understanding LLM Inference
Before diving into optimization techniques, it’s crucial to understand the two core steps of LLM inference: prefill and decoding.
- Prefill: Tokenization and Contextualization
In the prefill stage, the model receives an input, typically in the form of text, and breaks it down into tokens. These tokens are then transformed into numerical representations, which the model processes in its neural network. The goal of prefill is to set up a context in which the model can begin its generative task.
- Decoding: The Generation Phase
Once the input is tokenized and contextualized, the model begins to generate output, one token at a time, based on the patterns it learned during training. The efficiency of this phase dictates the overall performance of the system, especially in latency-sensitive applications.
However, decoding isn’t as straightforward as it seems. Generating text, for example, can require vast amounts of computation. Longer sequences, higher complexity in prompt structure, and the model’s size all contribute to making this phase resource-demanding.
- Challenges
The challenges in LLM inference lie primarily in latency, computation cost, and memory consumption. As models grow in size, they require more computational power and memory to generate reliable responses, making optimization essential for practical deployment.
How to Optimize LLM Inference
Now is the time for the main entrée. We will cover common LLM inference optimization techniques based on various participants of the pipeline, such as: hardware, algorithm, system, deployment and external tool.
- Hardware Acceleration. LLM inference can benefit from using a combination of CPUs, GPUs, and specialized hardware like TPUs and FPGAs.
- Leveraging heterogeneous hardware for parallel inference.
GPUs are well-suited for parallel processing tasks and excel at handling the matrix operations common in LLMs. For inference, distributing workloads across multiple GPUs, while utilizing CPUs for lighter orchestration, can significantly reduce latency and improve throughput.
By combining GPUs and CPUs in a heterogeneous architecture, you can ensure each hardware component plays to its strengths—CPUs handling sequential operations and GPUs accelerating tensor calculations. This dual approach maximizes performance and minimizes cost, especially in cloud-based and large-scale deployments.
- Specialized Hardware: TPUs and FPGAs
TPUs (Tensor Processing Units) are purpose-built for deep learning tasks and optimized for matrix multiplication, which is essential to LLMs training and inference. TPUs can outperform GPUs for some workloads, especially in large-scale inference scenarios. On the other hand, FPGAs (Field-Programmable Gate Arrays) offer customization, enabling users to create highly efficient hardware accelerators tailored to specific inference tasks, though their implementation can be more complicated.
Each of these specialized units—GPUs, TPUs, and FPGAs—can accelerate LLM inference, but the choice of hardware should align with the specific needs of your application, balancing cost, speed, and scalability.
- Algorithmic Optimization.
Efficient algorithms always stay at the heart of systematic optimization. The context here can be diverse, ranging from the self-attention mechanism design to task-specific scenarios. Below, we list a few common techniques related to faster LLM inference algorithms.
- Selective Context Compression
LLMs often handle long contexts to generate coherent text. Selective context compression involves identifying and pruning less relevant information from the input, allowing the model to focus on the most crucial parts of the text. This reduces the amount of data processed, cutting down both memory usage and inference time. This technique is especially useful for real-time applications where input lengths can vary dramatically, allowing the model to scale efficiently without sacrificing output quality.
- Speculative Decoding
LLMs are mostly autoregressive models, where tokens are generated one by one, with each token prediction depending on the previous ones. Speculative decoding is different: it predicts multiple possible tokens in parallel, significantly reducing the time spent on each decision. While this approach seems more efficient, it also raises the challenge of managing the predicted tokens, ensuring that the final output is the most accurate one.
- Continuous Batching
In continuous batching, incoming requests are buffered in a queue for a short duration. Once the batch reaches a sufficient size or time threshold, the model processes the batch in one pass. This approach shows more effectiveness when dealing with large data stream applications, like serving large-scale search engines or recommendation systems. One significant challenge is to adaptively determine the optimal batch sizes according to different application scenarios.
- Distributed Computing. A common technique during LLMs training, distributed computing can certainly be adopted during the inference phase. By spreading the workload across multiple servers or GPUs, we have more resources to handle inference with larger models. One good example is parallel decoding.
- Parallel Decoding
Parallel decoding optimizes inference by allowing multiple tokens to be processed simultaneously. This technique splits the task across multiple computational units, therefore may speed up the inference process. It is particularly useful for handling batch processing, where large amount of data needs to be processed in a short time frame. However, parallel decoding can strain memory resources, especially for large models. Thus, balancing the batch size and memory usage is crucial to preventing bottlenecks.
In addition to reducing latency and accommodating larger models for inference, distributed computing offers other benefits, such as load balancing fault tolerance. It becomes easier to manage traffic spikes and prevent any single unit from becoming overloaded. This enhances the overall reliability and availability of the system, allowing for consistent inference performance under heavy load.
- Industrial Inference Frameworks. For organizations looking to deploy LLMs at scale, there are frameworks like DeepSpeed and TurboTransformers that offer ready-made solutions to streamline the inference process. Both frameworks are open-sourced.
- DeepSpeed
Developed by Microsoft, DeepSpeed is a powerful framework that provides tools for model parallelism and pipeline parallelism, enabling large models to be split across multiple devices for faster inference. Zero Redundancy Optimizer (ZeRO) is a crucial part for inference because it reduces memory overhead by partitioning model parameters and gradients across devices. Inference can leverage ZeRO’s parameter partitioning to fit larger models on devices with limited memory. DeepSpeed also incorporates techniques like activation checkpointing and quantization to further optimize resource usage.
- TurboTransformers
Built specifically for transformer-based models, TurboTransformers focus on techniques like tensor fusion and dynamic quantization to optimize the execution of large models. One of TurboTransformers’ standout features is its efficient attention mechanism. By optimizing attention through techniques like block sparse attention or local attention, it reduces the time complexity of the attention layers. One apparent limitation of TurboTransformers is the lack of flexibility with other models. In addition, it highly relies on NVIDIA’s CUDA ecosystem.
The principle of this step is straightforward: provide the best customer experience with reasonably small cost. However, it is non-trivial to implement in production environments, which require careful attention to performance and resource utilization.
The techniques mentioned above can all contribute to effective and efficient LLM serving. The deployment usually involves lots of engineering efforts such as user interaction, docker container, etc. In addition, we introduce another practice for inference optimization in the serving and deployment phase: Mixture-of-experts.
- Mixture-of-experts (MoE) Models
MoE divides the LLM into multiple expert sub-models, each responsible for specific tasks. Only a subset of these experts is activated for each inference request, therefore enabling faster responses without sacrificing accuracy, as only the most relevant experts are engaged.
Case Study and Real-world Applications
LLM inference optimization has been driving impactful transformation across industries, many have already reaped the rewards of these advancements. In healthcare, for example, MedeAnalytics and PathAI have successfully integrated LLMs for diagnostic assistance and record summarization. The Selective context compression technique has been applied to help prioritize crucial patient data, thus improving efficiency.
Another example is the social media, where user-generated content is a primary driver of engagement on online forums, video-sharing websites, etc. Multi-modal LLMs have been actively studied for text and image analysis and generation. Many of the techniques mentioned above have been adopted in both training and inference phase.
Challenges: where LLM Inference Still Struggles
Living in Manhattan, even with the most efficient city planning and traffic control, drivers suffer from time to time. Same story for LLM inference, the model size always grows, capturing more modalities, accommodating more down-stream domains, etc. The punchline of LLM inference is the efficiency-accuracy trade-off, according to various applications. Can we design the LLM system to achieve the optimal trade-off? If yes, what compromise is exactly reasonable? Besides these high-level challenges, there are several concrete scenarios where better techniques would be helpful.
- Inference optimization for multi-modal LLMs.
- In-context generation with long interaction.
- Efficient load-balancing in dynamic environments.
Conclusion
Optimizing LLM inference is essential for making these advanced models practical and scalable in real-world applications. This blog explores key techniques that enhance LLM inference performance, covering various aspects of the LLM ecosystem, including hardware, algorithms, system architecture, deployment, and external tools. While current optimization methods are already sophisticated and versatile, the growing integration of LLMs across industries presents new challenges that will require continued innovation in inference efficiency.
Maximizing Efficiency in AI: The Role of LLM Serving Frameworks
Introduction
In the vast and ever-evolving landscape of artificial intelligence, LLM serving stands out as a pivotal component for deploying sophisticated machine learning models. At its core, LLM serving refers to the methodologies and technologies used to deliver large language models’ capabilities to end-users seamlessly. Large language models, or LLMs, serve as the backbone of numerous applications, providing the ability to parse, understand, and generate human-like text in real-time. Their significance extends beyond mere novelty, as they are reshaping how businesses operationalize AI to gain actionable insights and propel their customer experiences.
The evolution of LLM serving technology is a testimony to the AI industry’s commitment toward efficiency and scalability. Pioneering technologists in AI infrastructures recognized the need for robust, auto-scalable solutions that could not only withstand the growing demands but also streamline the complexity entailed in deploying and managing these cognitive powerhouses. Today, as we witness the blossoming of AI businesses across the globe, LLM serving mechanisms have become central to successful AI strategies, representing one of the most discussed topics within the industry.
Embracing an integrated framework for LLM serving paves the way for organizations to harvest the full spectrum of AI’s potential — making this uncharted territory an exciting frontier for developers, enterprises, and technology enthusiasts alike.
Understanding LLMs in AI
Large Language Models (LLMs) are revolutionizing the way we interact with artificial intelligence. These powerful tools can understand and generate human-like text, making them indispensable in today’s AI industry. But what exactly are LLMs, and why are they so significant?
LLMs are advanced machine learning models that process and predict language. They are trained on vast amounts of text data, learning the nuances of language structure and meaning. This training enables them to perform a variety of language-related tasks, such as translation, summarization, and even creative writing.
In the current AI landscape, LLMs play a pivotal role. They power chatbots, aid in customer service, enhance search engine results, and provide smarter text predictions. Their ability to understand context and generate coherent responses has made them vital for businesses seeking to automate and improve communication with users.
Popular examples of LLMs include OpenAI’s GPT-3 and Google’s BERT. GPT-3, known for its ability to produce human-like text, can write essays, create code, and answer questions with a high degree of accuracy. BERT, on the other hand, is designed to understand the context of words in search queries, improving the relevancy of search engine results.
By integrating LLMs, industries are witnessing a significant transformation in how machines understand and use human language. As these models continue to evolve, their potential applications seem limitless, promising a future where AI can communicate as naturally as humans do.
Key Components of LLM Serving
When deploying large language models (LLMs) like GPT-3 or BERT, understanding the server and engine components is crucial. The server acts as the backbone, processing requests and delivering responses. Its computing power is essential, as it directly influences the efficiency and speed with which the LLM operates. High-powered servers can rapidly perform complex language model inferences, translating to quicker response times and a smoother user experience. The ability to service multiple requests concurrently without delay is paramount, especially using resource-intensive LLMs.
Meanwhile, the engine of the serving system is akin to the brain of the operation—it’s where the algorithms interpret input data to provide human-like text. The engine’s performance is hinged on the server’s ability to provide the necessary computing power, which comes from high-quality CPUs and GPUs and sufficient memory for processing.
For an LLM to deliver its full potential, the server and engine must work in unison, leveraging high throughput and low latency to ensure user satisfaction. Auto-scaling capabilities and AI-specific infrastructures further empower these components, providing dynamic resource allocation to match demand. This ensures that services remain responsive across varying workloads, ultimately delivering a consistently efficient user experience.
In essence, the interplay between a server’s computing power and the LLM engine is a dance of precision and power, with each component magnifying the other’s effectiveness. A robust server infrastructure elevates the LLM’s performance, turning AI’s promise into a reality across user interactions.
LLM Serving Frameworks: A Comparative Analysis
When it comes to deploying large language models (LLMs), selecting the right serving framework is crucial. It’s not just about keeping the lights on; it’s about blazing a trail for efficient, scalable LLM inference that can keep pace with your needs. Let’s examine various frameworks such as TensorRT-LLM, vLLM, and RayServe to see how they stack up.
TensorRT-LLM: The Speed Demon
NVIDIA’s TensorRT-LLM is revered for its ability to deliver low latency and high throughput, essential for rapid LLM deployment. This high-performance deep learning inference optimizer and runtime is adept at auto-scaling across various NVIDIA GPUs. For those with CUDA-enabled environments, TensorRT-LLM shines by fine-tuning models for peak performance, ensuring every ounce of computing power is well-utilized. When throughput takes precedence, TensorRT-LLM is a game-changer.
vLLM: The Memory Magician
vLLM stands out in its approach to memory optimization. It is designed for scenarios where memory is a bottleneck yet high-speed LLM inference is non-negotiable. Offering a compromise between powerful performance and modest hardware demands, vLLM is a valuable asset, particularly in edge computing environments where conserving resources is paramount. If you’re wrestling with memory constraints but can’t compromise on speed, vLLM warrants serious consideration.
RayServe: The Flexible Powerhouse
With simplicity and flexibility at its core, RayServe offers a serving solution that is not only model-agnostic but also excels in diverse computational settings. Its auto-scaling prowess, based on incoming traffic, ensures optimal resource allocation while maintaining low latency. This makes RayServe ideal for those who desire a straightforward yet robust framework capable of dynamically adapting to fluctuating demands.
Benchmarking for Your Needs
Benchmarking these frameworks against your specific requirements is essential. Throughput, latency, and memory usage are critical metrics you’ll need to appraise. While TensorRT-LLM may boast superior throughput, vLLM could address your memory constraints with finesse. RayServe, with its auto-scaling abilities, ensures that LLM deployment is effectively managed over different loads.
Making an informed decision on the LLM serving framework affects the success of your application. By weighing your performance needs against various limitations, you can pinpoint a framework that satisfies immediate requirements and grows in tandem with your long-term goals. Whether you prioritize the sheer speed of TensorRT-LLM, the memory efficiency of vLLM, or the adaptability of RayServe, the right server framework is key to meeting your LLM inference challenges.
Challenges and Solutions in LLM Serving
Scaling LLM deployment to meet the high demands of modern user bases presents notable challenges. One primary concern for many organizations is the resource-intensive nature of these models, which can result in significant costs and technical constraints. Latency is another critical issue, with the need to provide real-time responses often at odds with the computational complexity involved in LLM inference.
Innovative solutions, such as PagedAttention and continuous batching, have emerged to address these hurdles. PagedAttention is a mechanism that reduces memory consumption during inference by carefully managing how memory is allocated and used, allowing for sophisticated LLMs to serve on more modest hardware without compromising processing speed. Continuous batching harnesses the power of parallel processing, executing multiple inference tasks collectively, thereby driving down latency and making the most of the computing resources at hand.
The key to success in LLM serving lies in striking the perfect balance between resource allocation, cost management, and system responsiveness. By employing these innovative techniques, organizations can improve efficiency, reduce overhead, and maintain a competitive edge in the fast-paced world of AI.
The future of LLM serving hinges on advancements in the technology that powers these language models. The distinction lies in the infrastructure and strategies employed to deliver the capabilities of LLMs to end-users efficiently. As the serving aspect evolves, AI businesses will likely see more robust, adaptable, and cost-effective solutions emerging. This will impact not only the accessibility and scalability of LLMs but also the breadth of applications and services AI companies can offer.
Enhancements in LLM serving tech are on track to streamline complex AI operations, making it easier for businesses to implement sophisticated natural language processing features. This will facilitate new heights of personalization and automation within the industry, fueling innovation and potentially altering the competitive landscape.
To sum up, the progression in LLM serving is crucial for shaping the application of Large Language Models within AI businesses, promising to drive growth and transformative change across the AI industry.
LLM Serving 101: Everything About LLM Deployment & Monitoring
A General Guide to Deploying an LLM
- Infrastructure Preparation:
- Choose a deployment environment: local servers, cloud services (like AWS, GCP, Azure), or hybrid.
- Ensure that you have the requisite computational resources: CPUs, GPUs, or TPUs, depending on the size of the LLM and expected traffic.
- Configure networking, storage, and security settings according to your needs and compliance requirements.
- Model Selection and Testing:
- Select the appropriate LLM (GPT-4, BERT, T5, etc.) for your use-case based on factors like performance, cost, and language support.
- Test the model on a smaller scale to ensure it meets your accuracy and performance expectations.
- Software Setup:
- Set up the software stack needed for serving the model, including machine learning frameworks (like TensorFlow or PyTorch), and application servers.
- Containerize the model and related services using Docker or similar technologies for consistency across environments.
- Scaling and Optimization:
- Implement load balancing to distribute the inference requests effectively.
- Apply optimization techniques like model quantization, pruning, or distillation to improve performance.
- API and Integration:
- Develop an API to interact with the LLM. The API should be robust, secure, and have rate limiting to prevent abuse.
- Integrate the LLM’s API with your application or platform, ensuring seamless data flow and error handling.
- Data and Privacy Considerations:
- Implement data management policies to handle the input and output securely.
- Address privacy laws and ensure data is handled in compliance with regulations such as GDPR or CCPA.
- Monitoring and Maintenance:
- Set up monitoring systems to track the performance, resource utilization, and health of the deployment.
- Plan for regular maintenance, updates to the model, and the software stack.
- Automation and CI/CD:
- Implement continuous integration and continuous deployment (CI/CD) pipelines for automated testing and deployment of changes.
- Automate scaling, using cloud services’ auto-scaling features or orchestration tools like Kubernetes.
- Failover and Redundancy:
- Design the system for high availability with redundant instances across zones or regions.
- Implement a failover strategy to handle outages without disrupting the service.
- Documentation and Training:
- Document your deployment architecture, API usage, and operational procedures.
- Train your team to troubleshoot and manage the LLM deployment.
- Launch and Feedback Loop:
- Soft launch the deployment to a restricted user base, if possible, to gather initial feedback.
- Use feedback to fine-tune performance and usability before a wider release.
- Compliance and Ethics Checks:
- Conduct an audit for compliance with ethical AI guidelines.
- Implement mechanisms to monitor biased outputs or misuse of the model.
Deploying an LLM is not a one-time event but an ongoing process. It’s essential to keep improving and adapting your approach based on new advancements in technology, changes in data privacy laws, and evolving business requirements.
Best Practices for Monitoring the Performance of an LLM After Deployment
After deploying a Large Language Model (LLM), monitoring its performance is crucial to ensure it operates optimally and continues to meet user needs and expectations. Here are some best practices for monitoring the performance of an LLM post-deployment:
- Establish Key Performance Indicators (KPIs):
- Define clear KPIs that align with your business objectives, such as response time, throughput, error rate, and user satisfaction.
- Application Performance Monitoring (APM):
- Utilize APM tools to monitor application health, including latency, error rates, and uptime to quickly identify issues that may impact the user experience.
- Infrastructure Monitoring:
- Track the utilization of computing resources like CPU, GPU, memory, and disk I/O to detect possible bottlenecks or the need for scaling.
- Monitor network performance to ensure data is flowing smoothly between the model and its clients.
- Model Inference Monitoring:
- Measure the inference time of the LLM, as delays could indicate a potential problem with the model or infrastructure.
- Log Analysis:
- Collect and analyze logs to gain insights into system behavior and user interactions with the LLM.
- Ensure logs are structured to facilitate easy querying and analysis.
- Anomaly Detection:
- Implement anomaly detection systems to flag any deviations from normal performance metrics. This could indicate an issue that requires attention.
- Quality Assurance:
- Continuously evaluate the accuracy and relevance of the LLM’s outputs. Set up automated testing or use human reviewers to assess quality.
- Track changes in performance after updates to the model or related software.
- User Feedback:
- Collect and analyze user feedback for qualitative insights into the LLM’s performance and user satisfaction.
- Integrate mechanisms for users to report issues with the model’s responses directly.
- Automate Incident Response:
- Develop automated alerting mechanisms to notify your team of critical incidents needing immediate attention.
- Create incident response protocols and ensure your team is trained to handle various scenarios.
- Usage Patterns:
- Monitor usage patterns to understand how users are interacting with the LLM. Look for trends like peak usage times, common queries, and feature utilization.
- Failover and Recovery:
- Regularly test failover procedures to ensure the system can quickly recover from outages.
- Monitor backup systems to make sure they are capturing data accurately and can be restored as expected.
- Security Monitoring:
- Implement security monitoring to detect and respond to threats such as unauthorized access or potential data breaches.
- Regular Audits:
- Conduct regular audits to ensure that the LLM is compliant with all relevant policies and regulations, including data protection and privacy.
- Continual Improvement:
- Use the insights gained from monitoring to continuously improve the system. This should include tuning the model and updating the infrastructure to address any identified issues.
- Collaboration and Sharing:
- Facilitate information sharing and collaboration between different team members (data scientists, engineers, product managers) to leverage different perspectives for better monitoring and quick resolution of issues.
By implementing these best practices, you can establish a robust monitoring framework that helps maintain the integrity, availability, and quality of the LLM service you provide.
Tools Used for Real-time Monitoring of LLMs
There are several tools available that can be used for real-time monitoring of Large Language Models (LLMs). Here are some examples categorized by their primary function:
All-in-one LLM Serving
WhaleFlux Serving: an open source LLM server with deployment, monitoring, injection and auto-scaling service. It is built to improve the execution process of LLM service comprehensively and designs a configuration recommendation module for automatic deployment on any GPU clusters and a performance detection module for auto-scaling.
Application Performance Monitoring (APM) Tools
- New Relic: Offers real-time insights into application performance and user experiences. It can track transactions, application dependencies, and health metrics.
- Datadog: A monitoring service for cloud-scale applications, providing visibility into servers, containers, services, and functions.
- Dynatrace: Uses AI to provide full-stack monitoring, including user experience and infrastructure monitoring, with root-cause analysis for detected anomalies.
- AppDynamics: Provides application performance management and IT Operations Analytics for businesses and applications.
Infrastructure Monitoring Tools
- Prometheus: An open-source monitoring solution that offers powerful querying capabilities and real-time alerting.
- Zabbix: Open-source, enterprise-level software designed for real-time monitoring of millions of metrics collected from various sources like servers, virtual machines, and network devices.
- Nagios: A powerful monitoring system that enables organizations to identify and resolve IT infrastructure problems before they affect critical business processes.
Cloud-Native Monitoring Tools
- Amazon CloudWatch: Monitors AWS cloud resources and the applications you run on AWS. It can track application and infrastructure performance.
- Google Operations (Stackdriver): Provides monitoring, logging, and diagnostics for applications on the Google Cloud Platform. It aggregates metrics, logs, and events from cloud and hybrid applications.
- Azure Monitor: Collects, analyzes, and acts on telemetry data from Azure and on-premises environments to maximize the performance and availability of applications.
Log Analysis Tools
- Elastic Stack (ELK Stack – Elasticsearch, Logstash, Kibana): An open-source log analysis platform that provides real-time insights into log data.
- Splunk: A tool for searching, monitoring, and analyzing machine-generated big data via a web-style interface.
- Graylog: Streamlines log data from various sources and provides real-time search and log management capabilities.
Error Tracking and Exception Monitoring
- Sentry: An open-source error tracking tool that helps developers monitor and fix crashes in real time.
- Rollbar: Provides real-time error alerting and debugging tools for developers.
Quality of Service Monitoring
- Wireshark: A network protocol analyzer that lets you capture and interactively browse the traffic running on a computer network.
- PRTG Network Monitor: Monitors networks, servers, and applications for availability, bandwidth, and performance.
Enhancing LLM Inference with GPUs: Strategies for Performance and Cost Efficiency
How to Run Large Language Models (LLMs) on GPUs
LLMs (Large Language Models) have caused revolutionary changes in the field of deep learning, especially showing great potential in NLP (Natural Language Processing) and code-based tasks. At the same time, HPC (High Performance Computing), as a key technology for solving large-scale complex computational problems, also plays an important role in many fields such as climate simulation, computational chemistry, biomedical research, and astrophysical simulation. The application of LLMs to HPC tasks such as parallel code generation has shown a promising synergistic effect between the two.
Why Use GPUs for Large Language Models?
GPUs (Graphics Processing Units) are crucial for accelerating LLMs due to their massive parallel processing capabilities. They can handle the extensive matrix operations and data flows inherent in LLM training and inference, significantly reducing computation time compared to CPUs. GPUs are designed with thousands of cores that enable them to perform numerous calculations simultaneously, which is ideal for the complex mathematical computations required by deep learning algorithms. This parallelism allows LLMs to process large volumes of data efficiently, leading to faster training and more effective performance in various NLP tasks and applications.
Key Differences Between GPUs and CPUs
GPUs and CPUs (Central Processing Units) differ primarily in their design and processing capabilities. CPUs have fewer but more powerful cores optimized for sequential tasks and handling complex instructions, typically with a few cores (dual to octa-core in consumer settings). They are suited for jobs that require single-threaded performance and can execute various operations with high control.
In contrast, GPUs are designed with thousands of smaller cores, making them excellent for parallel processing. They can perform the same operation on multiple data points at once, which is ideal for tasks like rendering images, simulating environments, and training deep learning models including LLMs. This architecture allows GPUs to process large volumes of data much faster than CPUs, giving them a significant advantage in handling parallelizable workloads.
How GPUs Power LLM Training and Inference
Leveraging Parallel Processing for LLMs
LLMs leverage GPU architecture for model computation by utilizing the massive parallel processing capabilities of GPUs. GPUs are equipped with thousands of smaller cores that can execute multiple operations simultaneously, which is ideal for the large-scale matrix multiplications and tensor operations inherent in deep learning. This parallelism allows LLMs to process vast amounts of data efficiently, accelerating both training and inference phases. Additionally, GPUs support features like half-precision computing, which can further speed up computations while maintaining accuracy, and they are optimized for memory bandwidth, reducing the time needed to transfer data between memory and processing units.
GPU-Accelerated Inference for Real-time Applications
GPUs enhance the inference of large-scale models like LLMs through strategies such as parallel processing, quantization, layer and tensor fusion, kernel tuning, precision optimization, batch processing, multi-GPU and multi-node support, FP8 support, operator fusion, and custom plugin development. Advancements like FP8 training and tensor scaling techniques further improve performance and efficiency.
These techniques, as highlighted in the comprehensive guide to TensorRT-LLM, enable GPUs to deliver dramatic improvements in inference performance, with speeds up to 8x faster than traditional CPU-based methods. This optimization is crucial for real-time applications such as chatbots, recommendation systems, and autonomous systems that require quick responses.
Key Optimization Techniques for LLMs on GPUs
Quantization and Fusion Techniques for Faster Inference
Quantization is another technique that GPUs use to speed up inference by reducing the precision of weights and activations, which can decrease the model size and improve speed. Layer and tensor fusion, where multiple operations are merged into a single operation, also contribute to faster inference by reducing the overhead of managing separate operations.
NVIDIA TensorRT-LLM and GPU Optimization
NVIDIA’s TensorRT-LLM is a tool that optimizes LLM inference by applying these and other techniques, such as kernel tuning and in-flight batching. According to NVIDIA’s tests, applications based on TensorRT can show up to 8x faster inference speeds compared to CPU-only platforms. This performance gain is crucial for real-time applications like chatbots, recommendation systems, and autonomous systems that require quick responses.
GPU Performance Benchmarks in LLM Inference
Token Processing Speed on GPUs
Benchmarks have shown that GPUs can significantly improve inference speed across various model sizes. For instance, using TensorRT-LLM, a GPT-J-6B model can process 34,955 tokens per second on an NVIDIA H100 GPU, while a Llama-3-8B model can process 16,708 tokens per second on the same platform. These performance improvements highlight the importance of GPUs in accelerating LLM inference.
Challenges in Using GPUs for LLMs
The High Cost of Power Consumption and Hardware
High power consumption, expensive pricing, and the cost of cloud GPU rentals are significant considerations for organizations utilizing GPUs for deep learning and high-performance computing tasks. GPUs, particularly those designed for high-end applications like deep learning, can consume substantial amounts of power, leading to increased operational costs. The upfront cost of purchasing GPUs is also substantial, especially for the latest models that offer the highest performance.
Cloud GPU Rental Costs
Additionally, renting GPUs in the cloud can be costly, as it often involves paying for usage by the hour, which can accumulate quickly, especially for large-scale projects or ongoing operations. However, cloud GPU rentals offer the advantage of flexibility and the ability to scale resources up or down as needed without the initial large capital outlay associated with purchasing hardware.
Cost Mitigation Strategies for GPU Usage
Balancing Costs with Performance
It’s important for organizations to weigh these costs against the benefits that GPUs provide, such as accelerated processing times and the ability to handle complex computational tasks more efficiently. Strategies for mitigating these costs include optimizing GPU utilization, considering energy-efficient GPU models, and carefully planning cloud resource usage to ensure that GPUs are fully utilized when needed and scaled back when not in use.
Challenges of Cost Control in Real-World GPU Applications
Real-world cost control challenges in the application of GPUs for deep learning and high-performance computing are multifaceted. High power consumption is a primary concern, as GPUs, especially those used for intensive tasks, can consume significant amounts of electricity. This not only leads to higher operational costs but also contributes to a larger carbon footprint, which is a growing concern for many organizations.
The initial purchase cost of GPUs is another significant factor. High-end GPUs needed for cutting-edge deep learning models are expensive, and organizations must consider the return on investment when purchasing such hardware.
Optimizing Efficiency: Key Strategies for Success
Advanced GPU Cost Optimization Techniques
Recent advancements in GPU technology for cost control in deep learning applications include vectorization for enhanced data parallelism, model pruning for reduced computational requirements, mixed precision computing for faster and more energy-efficient computations, and energy efficiency improvements that lower electricity costs. Additionally, adaptive layer normalization, specialized inference parameter servers, and GPU-driven visualization technology further optimize performance and reduce costs associated with large-scale deep learning model inference and analysis.
WhaleFlux: An Open Source in Optimizing GPU Costs
WhaleFlux is a service designed to optimize the deployment, monitoring, and autoscaling of LLMs on multi-GPU clusters. It addresses the challenges of diverse and co-located applications in multi-GPU clusters that can lead to low service quality and GPU utilization. WhaleFlux comprehensively deconstructs the execution process of LLM services and provides a configuration recommendation module for automatic deployment on any GPU cluster. It also includes a performance detection module for autoscaling, ensuring stable and cost-effective serverless LLM serving.
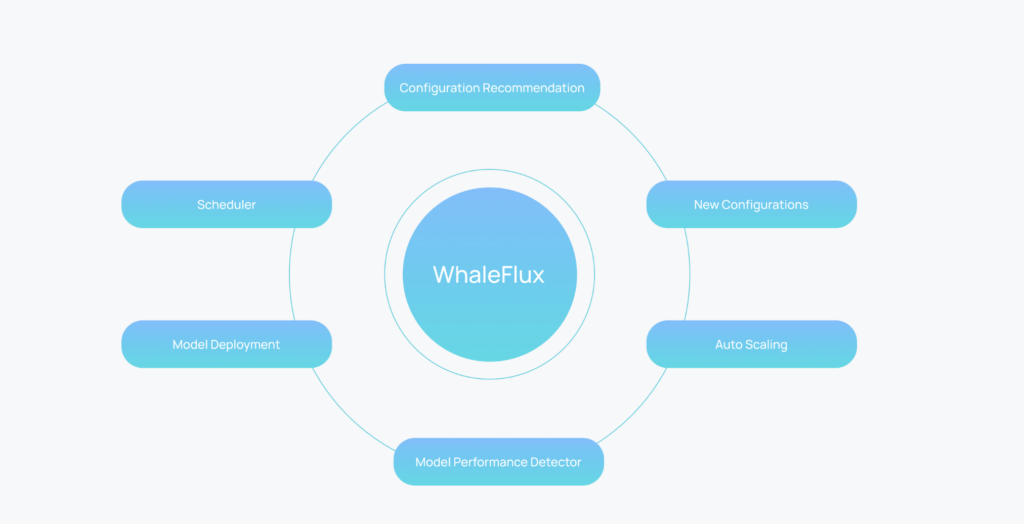
The service configuration module in Enova is designed to determine the optimal configurations for LLM services, such as the maximal number of sequences handled simultaneously and the allocated GPU memory. The performance detection module monitors service quality and resource utilization in real-time, identifying anomalies that may require autoscaling actions. Enova’s deployment execution engine manages these processes across multi-GPU clusters, aiming to reduce the workload for LLM developers and provide stable and scalable performance.
Future Innovations in GPU Efficiency
Emerging Technologies for Better GPU Performance
WhaleFlux’s approach to autoscaling and cost-effective serving is innovative as it specifically targets the needs of LLM services in multi-GPU environments. The service is designed to be adaptable to various application agents and GPU devices, ensuring optimal configurations and performance across diverse environments. The implementation code for WhaleFlux is publicly available for further research and development.
Future Outlook
Emerging technologies such as application-transparent frequency scaling, advanced scheduling algorithms, energy-efficient cluster management, deep learning job optimization, hardware innovations, and AI-driven optimization enhance GPU efficiency and cost-effectiveness in deep learning applications.
Fine-Tuning vs. Pre-Training: How to Choose for Your AI Application
Imagine you are standing in a grand library, where the books hold centuries of human thoughts. But you are tasked with a singular mission: find the one book that contains the precise knowledge you need. Do you dive deep and explore from scratch? Or do you pick a book that’s already been written, and tweak it, refining its wisdom to suit your needs?
This is the crossroads AI business and developers face when deciding between pre-training and fine-tuning. Both paths have their own fun and challenges. In this blog, we explore what lies at the heart of each approach: definitions, pros and cons, then the strategy to choose wisely.
Introduction
What is Pre-Training?
Pre-training refers to the process of training an AI model from scratch on a large dataset to learn general patterns and representations. Typically, this training happens over many iterations, requiring substantial computational resources, time, and data. The model, in essence, develops a deep understanding of the general features within the data, and can be used for inference at convenience.
The outcome of pre-training is usually a relatively stable, effective model adapted to the application scenarios as designed. It could be specified on a certain data domain and particular tasks, or applicable to general usage. Typical examples of pre-trained models include large language models like ChatGPT, Llama, Claude; or large vision models such as CLIP.
What is Fine-Tuning?
The fine-tuning process usually takes a pre-trained model and adjusts it to perform a specific task. This involves updating the weights of the pre-trained model using a smaller, task-specific dataset. Since the model already understands general patterns in the data (from pre-training), fine-tuning further improves it to specialize in your particular problem while reusing the knowledge from pre-training.
This process is often quicker and less resource-intensive than pre-training, as the pre-trained model already captures a wide range of useful features. And more importantly, the task-specific dataset is usually small. Fine-tuning is widely used especially for domain specialization, recent developments include finance, education, science, medicine, etc.
A Little More on the History
The liaison between fine-tuning and pre-training does not emerge in the era of LLMs. In fact, the development of deep learning brings about a perspective of these two “routines”. We can view the brief history of deep learning as three stages with respect to pre-training and fine-tuning.
- First stage (20thcentury): supervised fine-tuning only
- Second stage (early 21stcentury to 2020): supervised layer-wise pretraining + supervised fine-tuning
- Third stage (2020 to date): unsupervised layer-wise pretraining+ supervised fine-tuning
Indeed as we define above, especially for the recent foundation models, the pre-training phase on large datasets follows unsupervised fashion, i.e. for general knowledge, then the fine-tuning phase tailors the model into specific applications. However before this stage, reducing the horizon of the scale, we are already using supervised pretraining and fine-tuning for typical deep learning tasks.
Pros and Cons
If pre-training is the great journey across the general knowledge, then fine-tuning is the delicate craft of specialization. We promised fun and challenges for each approach, now it’s time to check them out.
Pros of Pre-Training
- Full control over the model: Pre-training gives you complete flexibility in designing the architecture and learning objectives, enabling the model to suit your specific needs.
- Task-generalized learning: Since pre-trained models learn from vast, diverse datasets, they develop a rich and generalized understanding that can transfer across multiple tasks.
- Potential for state-of-the-art performance: Starting from scratch allows for new innovations in the model structure, potentially pushing the boundaries of what AI can achieve.
Cons of Pre-Training
- High resource cost: Pre-training is computationally intensive, often requiring large-scale infrastructure (like cloud servers or specialized hardware) and extensive time.
- Vast amounts of data required: For meaningful pre-training, you need enormous datasets, which can be difficult or expensive to acquire for niche applications.
- Extended development time: Pre-training models from scratch can take weeks or even months, significantly slowing down the time to market.
The pros and cons of fine-tuning are straightforward by flipping the coin. In addition to that, we also mention a few nuances.
Pros of Fine-Tuning
- Straightforward:lower resource requirements, less strict data requirement.
- Faster to market: This becomes critical if you are running an AI business and would like to take one step faster than the competitors
- Flexible with target domains and tasks.Your AI applications and business may vary with time, or simply require a refinement of functionality. Fine-tuning makes that much easier.
Cons of Fine-Tuning
- Straightforward:less architectural flexibility, potential suboptimal performance.
- Model bias inheritance: Pre-trained models can sometimes carry biases from the datasets they were trained on. If your fine-tuned task is sensitive to fairness or requires unbiased predictions, this could be a concern. In general, the quality of fine-tuned models depends more or less on the pre-trained model.
When to Choose Fine-tuning
Fine-tuning is ideal when you want to leverage the power of large pre-trained models without the overhead of training from scratch. It’s particularly advantageous when your problem aligns with the general patterns already learned by the pre-trained model but requires some degree of customization to achieve optimal results. We raise several factors, with priority arranged in order:
- Limited resources: Either computational power or the dataset, if acquiring the resources is hard, fine-tuning a pre-trained model is more realistic.
- Sensitive timeline: Fine-tuning is mostly faster than pre-training, not just because of training from scratch. There are always risks that pre-training is sub-optimal and requires further refinement on the model architectures etc.
- Not necessarily the best model: If the performance requirements are not SOTA, but just a reliable, stable application of your foundation model, then fine-tuning is usually enough to achieve the goal. But it is considered much harder to beat all other models just by fine-tuning.
- Leverage existing frameworks: If your application fits well within existing frameworks (such as system compatibility), fine-tuning offers a simpler, more efficient solution.
Your Product’s Role
Inference acceleration refers to techniques that optimize the speed and efficiency of model predictions once the model is trained or fine-tuned. Whichever approach you choose, a faster inference time is always beneficial, both in the development stage and on market. We mention one major factor that the impact of inference acceleration on fine-tuning is more immediate.
- A Matter of Priority: During pre-training, the model’s complexity and computational demands are very high, and the primary concern is optimizing the learning process. The fine-tuning process, on the other hand, will soon move forward to the evaluation or deployment phase, when inference acceleration saves significant resources.
Inference Process of LLM
LLMs, particularly decoder-only models, use auto-regressive method to generate output sequences. This method generates tokens one at a time, where each step in the sequence requires the model to process the entire token history—both the input tokens and previously generated tokens. As the sequence length increases, the computational time required for each new token grows rapidly, making the process less efficient.
Inference Acceleration Methods
- Data-level acceleration: improve the efficiency via optimizing the input prompts (i.e., input compression) or better organizing the output content (i.e., output organization). This category of methods typically does not change the original model.
- Model-level acceleration: design an efficient model structure or compressing the pre-trained models in the inference process to improve its efficiency. This category of methods (1) often requires costly pre-training or a smaller amount of fine-tuning cost to retain or recover the model ability, and (2) is typically lossy in the model performance.
- System-level acceleration: optimize the inference engine or the serving system. This category of methods (1) does not involve costly model training, and (2) is typically lossless in model performance. The challenge is it also requires more efforts on the system design.
An Example of System-level Acceleration: WhaleFlux
WhaleFlux falls into the system-level acceleration, with a focus on GPU scheduling optimization. It is an open-source service for LLM deployment, monitoring, injection, and auto-scaling. Here are the major technical features and values:
- Automatic configuration recommendation.
- Real-time performance monitor.
- Stable, efficient and scalable. Increase resource utilization by over 50%and enhance comprehensive GPU memory utilization from 40% to 90%.
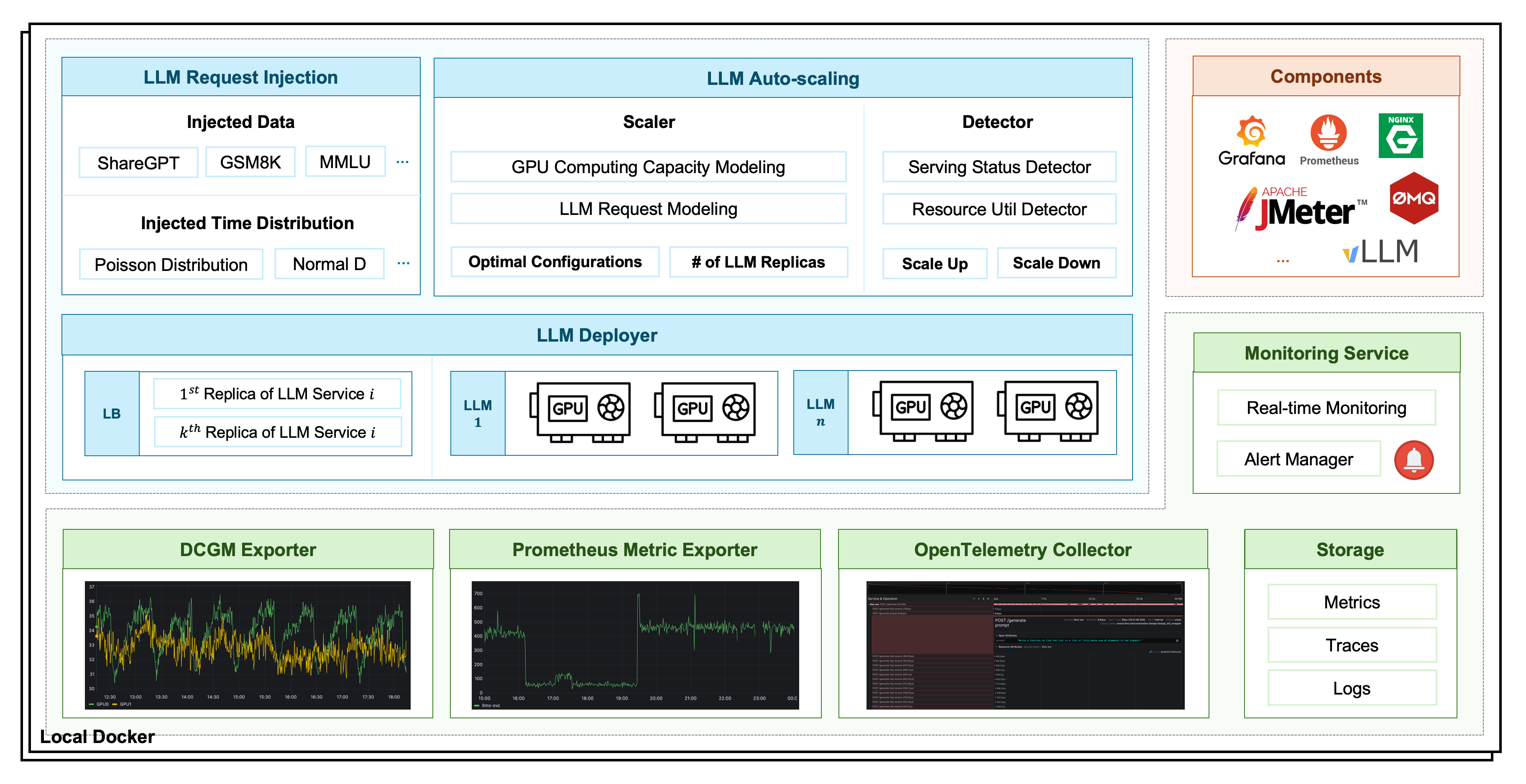
The figure above shows the components and functionalities of WhaleFlux. For more details we refer to the Github repo and the official website of WhaleFlux.
Conclusion
Choosing between fine-tuning and pre-training, by the end of day, depends on your specific project’s needs, resources, and goals. Fine-tuning is the go-to option for most businesses and developers who require fast, cost-effective solutions. On the other hand, pre-training is the preferred approach when developing novel AI applications that require deep customization, or when working with unique, domain-specific data. Though pre-training is more resource-intensive, it can lead to state-of-the-art performance and open the door to new innovations.
For practical concerns, most applications would favor inference acceleration techniques during pre-training and fine-tuning stages, especially for real-time predictions or deployment on edge devices. Data and model-level acceleration are more studied in the academic field, while system-level acceleration has more immediate effectiveness. We hope the content in this blog helps with your choice for your AI applications.
Inference Acceleration: Unlocking the Extreme Performance of AI Models
Introduction
In current era of increasingly widespread artificial intelligence applications, inference acceleration has played a crucial role in enhancing model performance and optimizing user experience. The operating speed in real-world scenarios is vital to the practical effectiveness of applications, especially in scenarios requiring real-time responses, such as recommendation systems, voice assistants, intelligent customer service, and medical image analysis.
The significance of inference acceleration lies in improving speed of system response, reducing computational costs and saving hardware resources. In many real-time scenarios, the speed of model inference not only affects the user experience but also the system’s real-time feedback capabilities. For example, recommendation systems need to make quick recommendations based on users’ real-time behavior, intelligent customer service needs to immediately understand user’s inquiries and generate appropriate responses, and medical image analysis requires models to quickly and accurately analyze a large amount of medical image data. Therefore, through inference acceleration, models can quickly respond to various requests while ensuring accuracy, thereby providing users with a smoother interactive experience.
Challenges
Despite the significant value that inference acceleration brings, it also faces some challenges.
· High computational load: Large AI models, such as natural language processing models (e.g. GPT-3) and computer vision models (e.g. YOLO, ResNet), typically contain hundreds of millions to trillions of parameters, leading to an extremely large computational load. The computational load during the inference phase can significantly impact the model’s response time, especially in high-concurrency environments.
· Hardware limitations: The inference process requires high hardware resource. Although the cloud has powerful computational resources, many applications (e.g. smart homes, edge monitoring, etc.) require models to run on edge devices. The computational capabilities of these devices are often insufficient to support the efficient operation of large models, which may result in high latency and delayed response.
· Memory and bandwidth consumption: AI models consume a large amount of memory and bandwidth resources during inference. For example, large models typically require tens or even hundreds of GB of memory. When memory is insufficient, the system may frequently invoke external storage, for further increasing latency. Moreover, if the model needs to be loaded from a remote cloud, bandwidth limitations can also affect loading speeds.
Solution
In case of what I mentioned above, here are several leverages for inference acceleration.
- Model Compression
Model compression is a way of reducing model parameters and computational load. by optimizing the model structure, it can improve inference efficiency. The main model compression technologies includequantization, pruning and knowledge distillation.
· Quantization:
Quantization can reduce model parameters from high precision to low precision, such as from 32-bit floating-point numbers to 8-bit integers. This approach can significantly reduce the model’s memory usage and computational load with minimal impact on model accuracy. Quantization tools from TensorFlow Lite and PyTorch make this process simpler.
·Pruning
Pruning reduces computational load by removing unimportant weights or neurons in neural networks. Some weights in the model have a minor impact on the prediction results, and by deleting these weights, computational load can be reduced while maintaining accuracy. For example, BERT models can be reduced in size by more than 50% through pruning techniques.
· Knowledge Distillation
The core of knowledge distillation is to train a small model to simulate the performance of a large model, maintaining similar accuracy but significantly reducing computational load. This method is often used to accelerate inference without significantly reducing model accuracy.
- Hardware Acceleration
In addition to model compression, hardware acceleration can also effectively improve model inference speed. Common hardware acceleration methods include:
· GPU Acceleration
GPUs can process a large number of computational tasks in parallel, making them particularly suitable for computationally intensive models during the inference phase. Common deep learning frameworks (such as TensorFlow and PyTorch) support GPU acceleration, significantly increasing speed during inference.
· FPGA and TPU Acceleration
Specialized hardware (such as Google’s TPU or FPGA) plays an important role in accelerating AI inference. FPGAs have a flexible architecture that can adapt to the inference requirements of different models, while TPUs are specifically designed for deep learning and are particularly suitable for Google’s cloud services.
· Edge Inference Device Acceleration
For edge computing needs, many inference acceleration devices, such as the NVIDIA Jetson series, are specifically developed for edge AI, enabling models to run efficiently under limited hardware conditions.
- Software Optimization
In addition to hardware and model structure optimization, software optimization techniques also play a key role in inference acceleration:
· Batch Inference
Batch inference involves packaging multiple inference requests together to accelerate processing speed through parallel computing. This method is very effective in dealing with high-concurrency requests.
· Memory Optimization
By optimizing memory usage, the inference process can be more efficient. For example, pipeline techniques and buffer management can reduce the repeated loading of data and memory consumption, thereby improving overall inference efficiency.
· Model Parallelism and Tensor Decomposition
Distributing the model across multiple GPUs and using tensor decomposition techniques to distribute computations across different computational units can increase inference speed.
Case
Inference acceleration has shown significant effects in many practical applications across various fields:
· Natural Language Processing (NLP)
In the field of natural language processing, the response speed of sentiment analysis and chatbot applications has been significantly improved through quantization and GPU acceleration. Especially in the customer service field, NLP-based chatbots can quickly respond to multi-round conversations with users.
· Recommendation Systems
Recommendation systems need to generate recommendation results in a very short time, and inference acceleration technology plays an important role. Through GPU acceleration and batch inference, personalized recommendation systems can provide personalized content to a large number of users in a shorter time, increasing user retention rates.
· Computer Vision
In scenarios such as autonomous driving and real-time monitoring, inference acceleration is particularly crucial. Edge inference and model compression technologies enable computer vision models to process camera inputs in real-time and react according to the processing results, ensuring safety.
· Biomedical
In medical image analysis, inference acceleration technology helps doctors analyze a large amount of image data in a shorter time, supporting rapid diagnosis. Through model pruning and quantization, medical AI models can efficiently analyze patient images, reducing misdiagnosis rates and saving medical resources.
Conclusion
Through model compression, hardware acceleration, and software optimization, inference acceleration has already demonstrated significant advantages in production environments, improving model response speed, reducing computational costs, and saving resources. Currently, WhaleFlux, a new optimization tool for computational power and performance is on the verge of launching. With the same hardware, it can conduct a more granular analysis of AI models and match them with precise resources. This effectively reduces the inference latency of large models by over 50%, maximizing the operational performance of the models and providing businesses with more cost-effective and efficient computational services.
In the future, with continuous innovation in inference acceleration, real-time AI applications will become more widespread, providing efficient and intelligent solutions for various industries.