Introduction
In the world of high-performance computing, we often discover that the biggest bottlenecks aren’t the hardware itself, but the software layers that manage it. Even with the most powerful NVIDIA GPUs, many AI teams find themselves wondering why their expensive hardware isn’t delivering the expected performance. One often-overlooked factor lies in how the operating system manages GPU tasks—a layer that introduces overhead and potential delays in processing.
This brings us to an important question: What if we could let the GPU manage its own tasks more directly? Could this approach make our AI workflows faster and more efficient? This is exactly what Hardware-Accelerated GPU Scheduling (HAGS) aims to accomplish—a feature that shifts scheduling responsibilities from the operating system to the GPU itself. While understanding HAGS is valuable, for enterprise AI teams, the real performance gains come from comprehensive solutions like WhaleFlux, which handle these low-level optimizations as part of a fully-managed infrastructure designed specifically for AI workloads.
Section 1: Demystifying Hardware-Accelerated GPU Scheduling (HAGS)
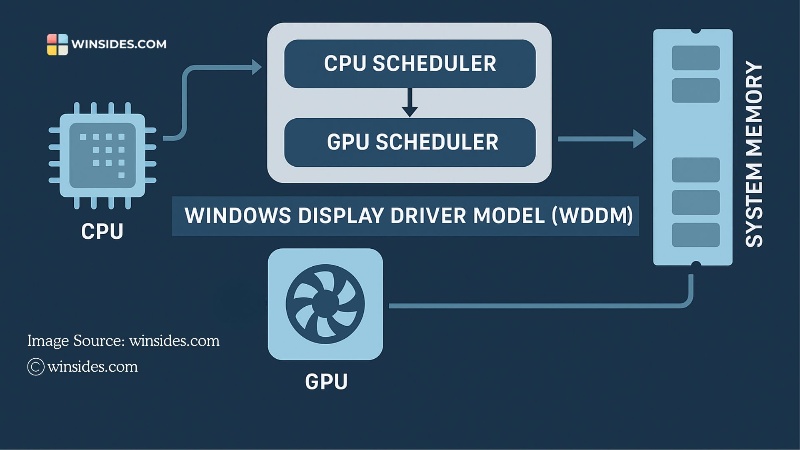
At its core, Hardware-Accelerated GPU Scheduling is exactly what its name suggests: it’s a feature that moves the responsibility of GPU task scheduling from your computer’s operating system (software-based scheduling) to a dedicated scheduling processor on the GPU itself (hardware-based scheduling).
Think of it this way: In a traditional restaurant kitchen without HAGS, every order from the dining room goes to a central manager (the Windows OS), who then decides which chef should handle which part of the order, when they should start, and in what sequence. This creates communication overhead and potential delays. With HAGS enabled, it’s like having an experienced head chef right in the kitchen who can immediately see all incoming orders and assign them to the most appropriate station without waiting for directions from management.
This dedicated scheduling hardware on modern NVIDIA GPUs can make faster, more efficient decisions about which tasks to run and when to run them. The primary goals are threefold: reducing the latency between task submission and execution, improving the consistency and smoothness of performance, and freeing up CPU resources that would otherwise be spent on managing the GPU’s workload.
Section 2: The Potential Benefits of HAGS for AI and Deep Learning
For AI practitioners, the theoretical benefits of HAGS align well with common performance challenges:
Reduced Latency:
In real-time AI inference scenarios—such as autonomous vehicle decision-making, live translation services, or interactive AI assistants—every millisecond counts. HAGS can minimize the delay between when a task is ready and when the GPU begins processing it, leading to faster response times.
Improved Performance Stability:
AI-powered visualization, scientific simulation, and real-time data analysis often suffer from inconsistent frame times or processing spikes. By giving the GPU direct control over its task queue, HAGS can provide more consistent timing, resulting in smoother performance and more predictable processing patterns.
Freed CPU Resources:
In many AI workflows, the CPU is already busy handling data preparation, model management, and other critical tasks. By offloading GPU scheduling overhead to the GPU itself, HAGS allows the CPU to dedicate more cycles to these essential functions, potentially creating a more balanced and efficient system overall.
These benefits are particularly noticeable in mixed-workload environments where the GPU needs to handle multiple types of tasks simultaneously, or in scenarios where low latency is more critical than raw throughput.
Section 3: The Reality Check: HAGS in a Professional AI Context
While HAGS sounds promising in theory, its practical impact on enterprise-scale AI training is more nuanced. For teams running large-scale distributed training jobs that fully saturate high-end NVIDIA GPUs like the H100 or A100 for days or weeks at a time, the performance gains from HAGS are often minimal or non-existent.
The reason is simple: when a GPU is completely dedicated to a single, massive training task, there’s very little scheduling complexity required. The GPU knows exactly what to do—process one batch after another continuously. In this scenario, the potential bottlenecks are elsewhere in the system:
- Data Transfer Limitations: The speed of PCIe lanes moving data from CPU to GPU
- Memory Bandwidth: How quickly the GPU can access its own VRAM
- Multi-Node Communication: The efficiency of NVLink and InfiniBand connections between multiple GPUs
- Storage I/O: How quickly training data can be read from storage systems
These infrastructure-level constraints typically have a far greater impact on overall training time than micro-optimizations at the GPU scheduling level. This reality highlights an important principle: for peak AI performance, you need an optimized computing stack from the ground up, not just a single OS-level toggle.
Section 4: The WhaleFlux Approach: Holistic GPU Scheduling and Orchestration
This is where WhaleFlux operates at a fundamentally different—and more impactful—level. While HAGS focuses on scheduling tasks within a single GPU, WhaleFlux specializes in orchestrating workloads across entire multi-GPU clusters. Think of HAGS as optimizing traffic flow at a single intersection, while WhaleFlux manages the entire city’s transportation network.
WhaleFlux delivers value through three key approaches that address the real bottlenecks in enterprise AI:
Intelligent Job Scheduling:
Rather than just managing tasks on one GPU, WhaleFlux dynamically assigns entire AI training jobs to the most available and suitable GPUs across your cluster. Whether your workload needs the raw power of NVIDIA H100s for foundation model training or the cost-efficiency of A100s for fine-tuning tasks, WhaleFlux ensures the right job reaches the right hardware at the right time.
Maximized Aggregate Utilization:
For businesses, the most important metric isn’t the utilization of a single GPU, but the utilization of your entire GPU fleet. WhaleFlux ensures that your cluster of H100s, H200s, A100s, and RTX 4090s operates at peak efficiency as a unified system. This holistic approach to resource management delivers far greater cost savings than any single-GPU optimization could achieve.
Abstracted Complexity:
With WhaleFlux, your team doesn’t need to worry about enabling HAGS, managing driver versions, or tuning low-level settings. Our pre-configured, optimized environments handle all these details automatically. Your data scientists can focus on developing better models while WhaleFlux ensures they’re running on infrastructure that’s fine-tuned for maximum performance and stability.
Section 5: Should You Enable HAGS? A Practical Guide
Given what we now understand about HAGS and enterprise AI infrastructure, here’s straightforward guidance for different scenarios:
For Individual Developers and Research Teams:
If you’re working on a single workstation with an NVIDIA GPU like the RTX 4090, HAGS is certainly worth testing. Enable it in your Windows display settings, run your typical AI workloads and benchmarks, and compare the results. Some users may see noticeable improvements in interactive AI applications or mixed-workload scenarios, while others might see little difference. The best approach is to experiment and see what works for your specific setup.
For AI Enterprises and Scaling Startups:
Don’t let HAGS distract you from the optimizations that truly matter at scale. Instead of focusing on single-GPU settings, direct your attention to cluster-level efficiency and resource management. This is exactly where a platform like WhaleFlux delivers immediate value. By providing access to a fully-managed fleet of NVIDIA GPUs—including H100, H200, A100, and RTX 4090—through simple monthly rental or purchase options, WhaleFlux handles all layers of the performance stack. Your team gets optimized performance without the infrastructure management burden, allowing you to focus on what really matters: developing innovative AI solutions.
Conclusion
Hardware-Accelerated GPU Scheduling represents an interesting evolution in how systems manage GPU resources, offering potential benefits for specific use cases, particularly on individual workstations and in mixed-workload environments. However, it’s crucial to recognize that HAGS is not a silver bullet for enterprise AI performance challenges.
The true path to AI computational efficiency lies in intelligent, large-scale resource orchestration that optimizes entire GPU clusters rather than individual processors. Platforms like WhaleFluxdeliver this comprehensive approach by managing the complete GPU infrastructure—from low-level settings like HAGS to high-level job scheduling across multiple nodes. This allows AI businesses to achieve maximum performance and cost-efficiency while focusing their valuable engineering resources on algorithm development and model innovation, rather than on hardware configuration and infrastructure management.