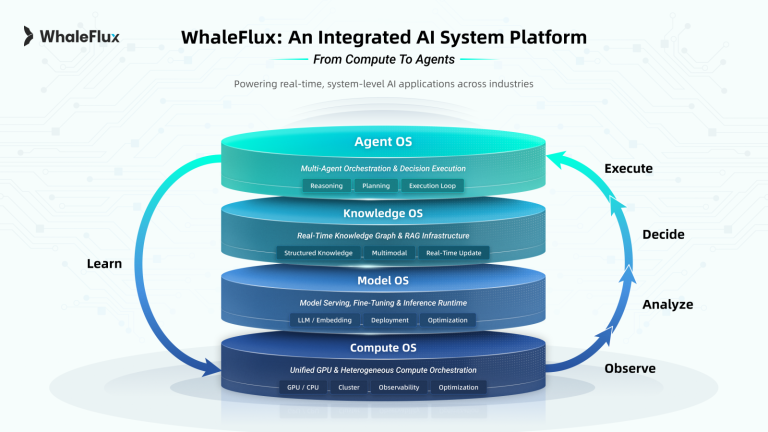
I. Introduction: The Critical Role of Inference in AI
Imagine asking a chatbot to help plan your vacation, and it responds instantly with perfect recommendations for flights, hotels, and activities. Or picture a doctor’s computer analyzing a medical scan in seconds, highlighting potential areas of concern. These aren’t scenes from a sci-fi movie; they are real-world applications powered by a crucial stage of artificial intelligence called deep learning inference.
Inference is the moment of truth for any AI model. It’s the process where a fully trained model is put to work, making predictions or generating outputs based on new, unseen data. While training a model is like a student spending years in a library studying, inference is that student now taking their final exams and applying their knowledge in a high-stakes career.
However, delivering fast, reliable, and cost-effective inference at scale is one of the biggest challenges businesses face today. When an AI application becomes popular, it needs to handle thousands or millions of requests simultaneously without slowing down or breaking. This requires not just powerful hardware but intelligent management of that hardware. This is where the journey from a powerful AI model to a successful AI product begins, and it’s a journey that WhaleFlux is built to optimize.
II. The Mechanics and Demands of Deep Learning Inference
A. What is an Inference Model?
When we talk about “deep learning inference,” we’re specifically referring to a model that has been prepared for deployment. Think of the difference between a chef developing a new recipe in a test kitchen versus serving that dish in a busy restaurant. The core ingredients are the same, but in the restaurant, everything is pre-measured, optimized for speed, and organized to handle a constant stream of orders.
An inference model is that optimized, “serving-ready” version. To achieve this, models often undergo techniques like:
- Pruning: Removing unnecessary parts of the model that aren’t critical for accuracy, making it leaner and faster—like trimming the fat off a piece of meat before cooking.
- Quantization: Reducing the precision of the numbers used in the model’s calculations. This is like using whole numbers instead of complex decimals for everyday math; it’s faster and requires less computational power, with often a minimal impact on the final result.
B. Key Performance Metrics for Inference
The success of an inference system is measured by a few critical metrics that directly impact user experience and cost:
- Latency: This is the delay between a user’s request and the model’s response. For a user chatting with an AI, high latency (a slow response) feels clunky and unresponsive. The goal is to achieve low latency, making interactions feel instantaneous.
- Throughput: If latency is about speed for one user, throughput is about scale for all users. It measures how many inferences the system can process per second. A high-throughput system can support millions of users without breaking a sweat.
- Cost-Efficiency: This is the total cost per inference. With models running 24/7, even a tiny reduction in the cost per query can lead to massive savings over time. Inefficient resource use quickly leads to ballooning cloud bills.
- Stability: The system must deliver consistent performance, whether it’s handling ten requests or ten thousand. Fluctuating performance or unexpected downtime erodes user trust and disrupts business operations.
III. Overcoming the Hardware Hurdle in Inference
A. The GPU as an Inference Engine
At the heart of performant inference lies the Graphics Processing Unit (GPU). GPUs are exceptionally good at this job because they are designed to perform thousands of small calculations simultaneously, which is exactly what a neural network does during inference.
However, not all inference workloads are the same, and neither are all GPUs. Matching the right GPU to the task is key to balancing performance and cost:
NVIDIA H100/H200:
These are the supercomputers of the GPU world. They are designed for massive-scale inference, such as running the largest large language models (LLMs) that require immense memory bandwidth and speed to generate responses quickly for a vast number of users.
NVIDIA A100:
Known as the versatile workhorse, the A100 is a reliable and powerful choice for a wide range of complex inference tasks, from serving advanced recommendation engines to complex computer vision models.
NVIDIA RTX 4090:
This GPU offers an excellent balance of performance and cost for smaller models, experimental projects, or deployments at the “edge” (closer to where data is generated, like in a retail store or a factory).
B. Common Inference Bottlenecks
Simply having powerful GPUs isn’t enough. Companies often run into two major bottlenecks:
Resource Contention and Inefficiency:
When multiple models or users compete for the same GPU resources, it creates a traffic jam. One resource-intensive request can slow down everything else, leading to unpredictable latency spikes. Furthermore, GPUs are often underutilized, sitting idle for periods but still costing money.
Unpredictable Costs and Performance:
On traditional cloud platforms, you might be sharing physical hardware with other “noisy neighbors.” Their activity can affect your performance, and the pay-as-you-go, per-second billing can make monthly costs difficult to forecast, turning infrastructure into a financial variable rather than a stable expense.
IV. How WhaleFlux Streamlines Deep Learning Inference
A. Intelligent Resource Management for Peak Performance
This is where WhaleFlux transforms the inference workflow. WhaleFlux acts as an intelligent air traffic controller for your GPU cluster. Its smart scheduling system dynamically allocates incoming inference requests across the available GPUs, ensuring that no single card becomes a bottleneck.
By efficiently balancing the load, WhaleFlux eliminates resource contention, guaranteeing consistently low latency for end-users. More importantly, it maximizes the utilization of every GPU in the cluster. A GPU that is working efficiently is a GPU that delivers more inferences for the same cost, directly driving down your cost per inference and providing a clear return on investment.
B. A GPU Fleet for Every Inference Need
We provide access to a curated fleet of the most powerful and relevant NVIDIA GPUs on the market, including the H100, H200, A100, and RTX 4090. This allows you to select the perfect GPU for your specific model and traffic patterns, optimizing for the best price-to-performance ratio.
To provide stability and predictability, we offer flexible purchase or rental options with a minimum one-month term. This model eliminates the volatility of hourly billing and allows for accurate budgeting, giving your finance team peace of mind and your engineers a stable foundation to build upon.
C. Ensuring Inference Stability and Speed
For an AI product to be successful, it must be reliable. WhaleFlux’s platform is engineered for 24/7 production environments. The deep observability and automated management features ensure that your inference service remains stable even under heavy or fluctuating loads. This reliability translates directly into a superior user experience—your customers get fast, accurate answers every time they interact with your AI, building trust and loyalty in your brand.
V. Conclusion: Deploy with Confidence and Efficiency
Efficient and reliable deep learning inference is no longer a technical luxury; it is a business necessity. It is the bridge that connects a powerful AI model to a successful, user-loving product. The challenges of latency, throughput, cost, and stability can be daunting, but they are not insurmountable.
WhaleFlux provides the managed GPU power and intelligent orchestration needed to cross this bridge with confidence. By offering the right hardware combined with sophisticated software that ensures peak efficiency, we help you deploy your deep learning models faster, more reliably, and at a significantly lower total cost.
Ready to optimize your inference workload and deliver an exceptional AI experience? Explore how WhaleFlux can power your deployment and turn your AI models into business assets.