Introduction: The LLM Fine-Tuning Bottleneck
The AI revolution is in full swing, and large language models (LLMs) are at its core. Businesses everywhere are scrambling to harness their power – not just using off-the-shelf models, but customizing them for specific tasks like customer service chatbots, specialized content generation, or industry-specific analysis. This customization process, known as fine-tuning, is essential for unlocking truly valuable AI applications. However, fine-tuning these behemoths comes with a massive, often underestimated, hurdle: the computational bottleneck.
Pain Point 1: Astronomical Compute Costs:
Fully retraining even a moderately sized LLM requires staggering amounts of processing power, primarily driven by expensive GPU resources. The energy consumption and cloud bills for such full fine-tuning can quickly become prohibitive, especially for smaller teams or frequent iterations.
Pain Point 2: Multi-GPU Management Headaches:
To handle these workloads, enterprises need clusters of powerful GPUs. But managing these clusters efficiently is a nightmare. Allocating resources, preventing idle time, handling job scheduling, and ensuring smooth communication between GPUs requires significant DevOps expertise and constant attention, diverting resources from core AI development.
Pain Point 3: Slow and Unstable Workflows:
The sheer scale often leads to painfully slow training times. Worse, jobs can crash mid-training due to resource contention, instability in the cluster, or hardware failures, wasting precious time, money, and effort. Getting a reliably tuned model into deployment feels like an uphill battle.
The thesis is clear: To overcome these barriers and make custom LLM development truly scalable and cost-effective, we need a dual approach: Parameter-Efficient Fine-Tuning (PEFT) methods to drastically reduce the computational demand, combined with intelligent GPU resource management to maximize the efficiency and reliability of the resources we do use.
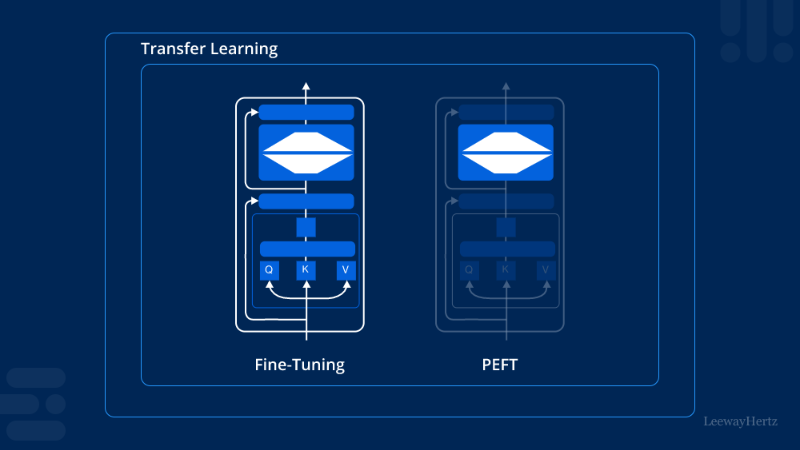
Demystifying PEFT (Parameter-Efficient Fine-Tuning)
Think of a massive LLM as a complex machine with billions of adjustable knobs (parameters). Traditional fine-tuning requires turning all these knobs to adapt the machine to a new task. PEFT takes a smarter approach: it freezes the vast majority of the original model and only adjusts a very small, strategic subset of parameters or adds lightweight “adapters.”
Here’s why PEFT is revolutionary for LLM customization:
Dramatically Reduced Compute/GPU Requirements:
By focusing updates on a tiny fraction of the model (often <1%), PEFT slashes the memory (VRAM) footprint and processing power needed. Tasks that once required top-tier, expensive multi-GPU setups might now run effectively on a single powerful GPU or smaller clusters.
Faster Training Cycles:
With vastly fewer parameters to update, training converges much quicker. What took days might now take hours. This acceleration enables faster experimentation and iteration cycles – crucial for finding the optimal model for your task.
Easier Multi-Task Management:
PEFT allows you to train and store multiple small “adapter” modules for different tasks on top of the same base LLM. Switching tasks is as simple as loading a different, lightweight adapter, avoiding the need for multiple, massive, fully-tuned models.
Resource Accessibility:
PEFT democratizes LLM fine-tuning. It makes powerful customization feasible for teams without access to enormous data center resources, enabling innovation beyond just the largest tech giants.
The GPU Challenge: Powering PEFT Efficiently
PEFT is a game-changer, but let’s be realistic: it doesn’t eliminate the need for capable GPUs. You’re still working with a massive base model that needs to be loaded into GPU memory and run efficiently during training. The demands are significantly lower than full fine-tuning, but they are still substantial, especially for larger base models (like Llama 2 70B or GPT-class models) or larger datasets.
Furthermore, simply having access to GPUs isn’t enough. Bottlenecks persist that undermine the efficiency gains promised by PEFT:
Underutilized Expensive GPUs:
In typical multi-GPU clusters, significant idle time is common due to poor job scheduling or resource allocation. You’re paying for expensive hardware (like H100s or A100s) that isn’t always working at full capacity.
Difficulty Scaling PEFT Jobs:
While a single PEFT job might fit on one GPU, efficiently distributing multiple concurrent experiments or scaling a single large PEFT job across a cluster requires sophisticated orchestration. Doing this manually is complex and error-prone.
Cloud Cost Unpredictability & Wastage:
Traditional cloud GPU rentals, often billed by the hour, encourage users to over-provision “just in case,” leading to wasted spending. Idle time is literally money burning away. Budgeting becomes difficult.
Instability in Long-Running Jobs:
PEFT jobs, though faster than full fine-tuning, can still run for hours or days. Cluster instability, resource conflicts, or hardware glitches can crash jobs, forcing expensive restarts and delaying projects.
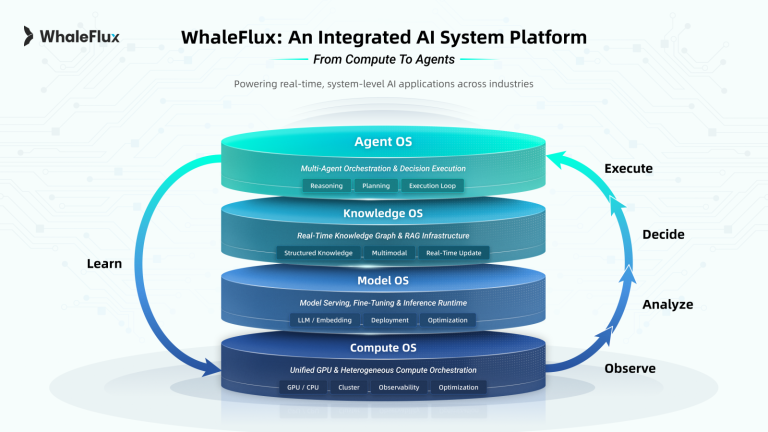
Introducing WhaleFlux: Optimized GPU Power for AI Enterprises
This is where WhaleFlux enters the picture. WhaleFlux is an intelligent GPU resource management platform built from the ground up for the demanding needs of AI enterprises. Think of it as the ultimate conductor for your orchestra of GPUs. Its core mission is simple: maximize the value derived from every single GPU cycle you pay for.
WhaleFlux tackles the GPU resource challenge head-on, delivering tangible benefits specifically tailored for workloads like PEFT fine-tuning:
Intelligent Orchestration:
WhaleFlux doesn’t just allocate GPUs; it dynamically optimizesworkloads. It intelligently packs multiple PEFT jobs onto available GPUs based on their real-time resource needs (VRAM, compute). For example, it might run several smaller model PEFT jobs efficiently on a cluster of RTX 4090s, while dedicating H100s or H200s to larger, more demanding base models. It handles job queuing, scheduling, and scaling automatically, ensuring peak cluster utilization.
Significant Cost Reduction:
By ruthlessly eliminating idle time and ensuring right-sized resource allocation for every job, WhaleFlux slashes your cloud GPU spend. You only pay for the raw power you actually use effectively. Its optimization directly translates into lower bills and a much better return on your GPU investment.
Enhanced Speed & Stability:
WhaleFlux’s intelligent management prevents resource contention crashes. It ensures jobs have consistent, dedicated access to the resources they need, leading to faster completion times and dramatically improved reliability. Say goodbye to frustrating mid-training failures. Your PEFT jobs run smoother and finish faster.
Powerful Hardware Options:
WhaleFlux provides access to the latest and most powerful NVIDIA GPUs essential for modern AI: the blazing-fast NVIDIA H100 and H200, the workhorse NVIDIA A100, and the cost-effective powerhouse NVIDIA RTX 4090. You can choose the perfect mix for your specific PEFT workloads, balancing performance and budget.
Flexible, Predictable Access:
WhaleFlux offers flexible purchase or rental options for dedicated resources tailored to your sustained AI development needs. Crucially, WhaleFlux operates on monthly minimum commitments, not hourly billing. This model provides cost predictability and eliminates the waste and budgeting headaches associated with per-hour cloud GPU rentals, perfectly aligning with the ongoing nature of AI development and experimentation.
Synergy in Action: WhaleFlux Supercharges PEFT Workflows
Let’s see how the powerful combination of PEFT and WhaleFlux transforms real-world AI development:
Scenario 1: Running Multiple Concurrent PEFT Experiments:
Your research team needs to test PEFT on 5 different customer support tasks using a medium-sized LLM. Without orchestration, this could require 5 separate GPUs, likely with significant idle time per GPU. WhaleFlux analyzes the resource requirements of each job and intelligently packs them onto, say, 2 or 3 available GPUs (e.g., A100s or RTX 4090s), maximizing GPU utilization. Result: Faster results for all experiments, lower overall GPU cost, and higher researcher productivity.
Scenario 2: Scaling a Single Large PEFT Job:
You need to fine-tune a massive LLM (like Llama 2 70B) on a large proprietary dataset using PEFT. Even with PEFT, this demands significant VRAM and compute. WhaleFlux seamlessly handles the distributed training across a cluster of high-memory GPUs (like H100s or H200s). It optimizes the communication between GPUs, manages the data pipeline, and ensures stability throughout the potentially long training process. Result: A complex job completes faster and more reliably than manual cluster management could achieve.
Scenario 3: Ensuring Stability for Long-Running Tuning:
A critical PEFT job for a new product feature is estimated to take 48 hours. The fear of a crash midway is palpable. WhaleFlux provides resource persistence, monitors cluster health, and implements fault tolerance mechanisms. If a minor glitch occurs, WhaleFlux can often recover the job without losing significant progress. Result: Critical projects finish on time, avoiding costly delays and rework.
The Outcome: The synergy is undeniable. PEFT drastically reduces the parameter-level computational load. WhaleFlux maximizes the resource-level efficiency and stability of the GPU power needed to execute PEFT. Together, they deliver:
- Faster Iteration Cycles: Experiment and deploy custom models quicker.
- Lower Cost Per Experiment: Achieve more tuning within your budget.
- Higher Researcher Productivity: Free your team from infrastructure headaches.
- More Stable Deployments: Get reliable, production-ready models faster.
Conclusion
The path to cost-effective, rapid, and reliable LLM customization is clear. PEFT provides the algorithmic efficiency by smartly minimizing the parameters that need updating. WhaleFlux delivers the infrastructure efficiency by intelligently maximizing the utilization, stability, and cost-effectiveness of the essential GPU resources.
PEFT makes fine-tuning feasible; WhaleFlux makes it scalable, predictable, and profitable for enterprises. WhaleFlux isn’t just a tool; it’s the essential platform foundation for any AI team serious about accelerating their LLM development, controlling costs, and achieving production success without the infrastructure nightmares.