Hardware-Level Sovereignty: Architecting Zero-Trust GPU Enclaves for Proprietary AI
Introduction
In the industrial AI landscape of 2026, a company’s most valuable asset is no longer its software code or its brand—it is its Proprietary AI Weights. These digital “brains,” refined through millions of dollars in compute and curated datasets, represent the definitive competitive edge. However, as enterprises move these models into production, they face a harrowing security paradox: How do you run your most sensitive intelligence on high-performance infrastructure without exposing it to the underlying host, the cloud provider, or malicious lateral actors?
Traditional perimeter-based security is dead. In its place, the industry is shifting toward Hardware-Level Sovereignty. This architectural shift moves beyond firewalls and encryption-at-rest to create Zero-Trust GPU Enclaves—secure, isolated environments where data and models are only decrypted within the silicon itself. This article explores the mechanics of this high-stakes security evolution and why WhaleFlux is the cornerstone for enterprises that refuse to compromise on data sovereignty.
The Death of Implicit Trust in the AI Era
Until recently, cloud security relied on a chain of “implicit trust.” You trusted the hypervisor, you trusted the system administrator, and you trusted that the data in the GPU memory was isolated from other tenants. In 2026, this model is insufficient for Mission-Critical AI.
The rise of “Confidential Computing” has turned the focus toward the hardware. Zero-Trust GPU Enclaves utilize Trusted Execution Environments (TEEs) provided by modern silicon—such as NVIDIA’s Hopper (H100) and Blackwell (B200) architectures. These enclaves ensure that even if the host operating system is compromised, the model weights and inference data remain encrypted and inaccessible to everyone except the authorized hardware root of trust.
WhaleFlux: The Bastion for Proprietary Intelligence
While many cloud providers offer “security as a service,” WhaleFlux approaches security as a foundational architectural requirement. We recognize that for global innovators, sovereignty isn’t a feature—it’s the prerequisite for scaling.
WhaleFlux implements a Security-By-Design framework that provides Hardware-Level Isolation across our entire Compute Infra. By leveraging advanced GPU partitioning and automated failover protocols, WhaleFlux ensures that your Model Refinement and Agent Orchestration workflows are sequestered within hardened enclaves. Unlike legacy cloud providers where data “friction” can lead to leaks, WhaleFlux offers a Hardened Control Plane that mathematically proves the integrity of your environment before a single weight is loaded.
By building on WhaleFlux, enterprises move from “hope-based security” to Deterministic Sovereignty, where the silicon itself acts as the ultimate gatekeeper of your intellectual property.
Architecting the Zero-Trust GPU Enclave
A true Zero-Trust architecture for AI must secure the three primary states of data: At Rest, In Transit, and In Use.
1. Remote Attestation: The Cryptographic Handshake
Before your proprietary model is deployed on a WhaleFlux cluster, the hardware undergoes Remote Attestation. The system generates a cryptographic proof that the GPU enclave is in a known, secure state. Only once this proof is verified does the Key Management Service (KMS) release the decryption keys directly into the hardware-protected memory.
2. Memory Encryption and Isolation
Once the model is active, the data “In Use” is encrypted within the GPU’s VRAM. This prevents “cold boot” attacks or memory scraping. At WhaleFlux, we utilize Hardware-Level Sovereignty to ensure that even our own engineers cannot view the plaintext prompts or outputs of your Autonomous Agents.
3. Zero-Trust Orchestration
Security must scale. WhaleFlux’s Agent Orchestration layer extends these hardware protections to multi-step workflows. As your agents call external tools or access vector databases, the identity-based access controls ensure that data remains siloed, preventing lateral movement across your enterprise stack.
Why Sovereignty is the New ROI
The push for hardware-level sovereignty is driven by more than just fear; it’s driven by the economics of Risk Management. In 2026, a single leak of a specialized model’s weights can lead to immediate commoditization of a company’s niche advantage.
Enterprises choosing WhaleFlux typically see a 40-70% reduction in TCO not just through compute efficiency, but through the avoidance of “Sovereignty Premiums” charged by legacy hyperscalers. By providing an integrated stack where security is built-in rather than “bolted-on,” WhaleFlux allows you to scale your intelligence without scaling your risk surface.
Conclusion
The era of “experimental AI” is over. We have entered the era of Industrial-Scale Autonomy, where the resilience of your infrastructure is just as important as the accuracy of your models. Hardware-Level Sovereignty is the only way to ensure that as your AI becomes more powerful, it remains strictly under your control.
Through WhaleFlux, the promise of a Zero-Trust AI future is a reality. By providing the hardened enclaves and the architectural intelligence needed to protect your proprietary assets, WhaleFlux empowers you to build the future with absolute confidence. In the high-stakes world of AI, don’t just build—secure your sovereignty.
Frequently Asked Questions (FAQ)
1. What exactly is a “Zero-Trust GPU Enclave”?
It is a hardware-enforced “black box” within the GPU where data is processed in an encrypted state. It ensures that the model and data are invisible to the host OS, the hypervisor, and the infrastructure provider, allowing for truly confidential AI.
2. How does WhaleFlux handle my model weights differently than other providers?
WhaleFlux uses Remote Attestation to ensure the hardware is secure before loading weights. We provide a Hardened Control Plane where weights remain encrypted until they reach the secure enclave of the GPU, ensuring that your IP never exists in plaintext on our servers.
3. Does hardware-level isolation impact the performance of AI inference?
While there is a minimal overhead for encryption, modern architectures like NVIDIA’s Blackwell (B200) are designed for confidential computing at line-rate. WhaleFlux optimizes this to ensure that security does not come at the cost of your 99.9% SLA.
4. Is this level of security necessary for all AI models?
If your model is built on proprietary data or represents a unique competitive advantage (e.g., specialized medical, financial, or engineering models), hardware-level sovereignty is essential to prevent IP theft and ensure regulatory compliance.
5. Can I use WhaleFlux for sovereign AI requirements in specific jurisdictions?
Yes. WhaleFlux is designed to meet the growing global demand for Sovereign AI Stacks. Our infrastructure allows for regional isolation and strict data residency, making it the ideal platform for multinational enterprises navigating complex regulatory environments.
Scaling Retail AI Computer Vision with Unified Infrastructure
Introduction: The Visual Revolution in Retail
The retail industry is undergoing a quiet but profound transformation. For decades, cameras in stores were passive observers—silent witnesses used only for forensic evidence after a theft had occurred. Today, those same lenses are becoming the “eyes” of an intelligent digital nervous system. Retail AI computer vision is no longer a pilot project for tech giants; it is the essential infrastructure for any merchant looking to survive in a high-inflation, high-shrinkage economy.

From automated checkout and real-time inventory tracking to advanced heat mapping and loss prevention, computer vision AI retail applications are redefining the physical store. However, the move from a simple setup to a sophisticated AI-native environment presents a massive technical hurdle. It requires immense parallel processing power, specialized model adaptation, and the ability to turn visual data into autonomous action.
This is where the synergy between retail AI computer vision technology and a unified infrastructure becomes critical. Platforms like WhaleFlux are bridging the gap, providing the Elastic AI Compute and Fine-tuning capabilities that allow retailers to deploy professional-grade vision systems without the overhead of a Silicon Valley tech firm.
1. The Core Components of Retail AI Computer Vision Technology
To understand how this technology works, we must look at the three pillars that support every modern computer vision AI retail deployment:
Real-Time Inference at the Edge
Unlike a chatbot, retail vision cannot afford high latency. If a customer walks out with an un-scanned item, the system must detect it in milliseconds. This requires high-performance GPUs located either on-site or in a low-latency edge cloud. WhaleFlux provides the NVIDIA-powered compute necessary to handle these dense video streams, ensuring that frames are processed as fast as they are captured.
The Move to Fine-Tuning
A generic computer vision model can recognize a “bottle,” but it cannot distinguish between a $500 bottle of vintage wine and a $10 bottle of table wine. This is a crucial distinction for inventory and loss prevention.
WhaleFlux excels at Fine-tuning. By using the WhaleFlux AI Models & Data platform, retailers can take a base vision model and “fine-tune” it on their specific SKU library. This allows the system to recognize thousands of specific products with near-perfect accuracy.
Behavioral Analytics
Beyond identifying objects, retail AI computer vision is now learning to identify intent. Is a customer browsing, or are they exhibiting “looping” behavior associated with organized retail crime? By analyzing skeletal tracking and movement patterns, AI can alert security before an incident occurs.
2. Why WhaleFlux is the “Nervous System” for Smart Retail
Scaling retail AI computer vision technology across hundreds of stores is a logistical nightmare. Traditionally, retailers had to manage fragmented hardware, inconsistent model versions, and frequent system crashes.
WhaleFlux solves this through a Unified AI Platform approach:
AI Observability: Preventing the “Black Screen”
In a retail environment, a crashed AI system means lost revenue or unmonitored theft. WhaleFlux’s AI Observabilitytools are specifically designed for high-stress GPU environments. By monitoring hardware health in real-time, WhaleFlux can reduce hardware failures by 98%. For a retailer with 500 locations, this means the difference between a functional security net and a broken, expensive liability.
Cost Optimization
Compute costs are the silent killer of AI ROI. Many cloud providers charge a premium for idle GPU time. WhaleFlux allows for Elastic AI Compute, meaning retailers only pay for the heavy lifting when it’s needed—such as during peak shopping hours—slashing overall compute costs by up to 70%.
3. From Vision to Action: The AI Agent Revolution
The most significant evolution in computer vision ai retail is the transition from “seeing” to “doing.” This is the realm of the AI Agent.
Imagine a scenario where a camera detects a spill in Aisle 4. In a traditional system, a human would eventually see a notification and call a janitor. In an AI-native store powered by the WhaleFlux AI Agent Platform, the vision system triggers an “Agent” that:
- Verifies the spill.
- Checks the janitorial schedule.
- Automatically sends a notification to the nearest employee’s handheld device.
- Logs the incident for liability protection.
This “Observation -> Reasoning -> Action” loop is what separates a simple camera from a truly intelligent retail system. By integrating fine-tuned vision models with autonomous agents, WhaleFlux helps retailers automate the mundane, allowing human staff to focus on customer service.
4. Overcoming the Challenges of Computer Vision AI Retail
Despite the benefits, implementing retail AI computer vision technology comes with hurdles, primarily surrounding data privacy and integration.
Privacy-First AI:
Modern systems use “anonymized tracking,” where customers are represented as numeric IDs rather than identifiable faces. WhaleFlux’s secure infrastructure ensures that the data used for fine-tuning remains private and compliant with global regulations like GDPR.
System Integration:
A vision system is useless if it doesn’t talk to the Point of Sale (POS) or Inventory Management System. The WhaleFlux platform provides the connective tissue, allowing AI agents to interact with legacy retail software through standardized APIs.
Conclusion: The Future of the Intelligent Store
The era of the “dumb” retail store is ending. As retail ai computer vision becomes the standard, the competitive gap between tech-enabled retailers and those relying on manual processes will widen into a chasm.
The successful retailer of 2026 will be defined by their ability to orchestrate three things: Compute, Models, and Agents.Through WhaleFlux, the complexity of this orchestration is simplified. By providing the elastic compute needed for vision processing, the platform for precise model fine-tuning, and the observability to keep the lights on, WhaleFlux is empowering the retail sector to see more, understand more, and ultimately, achieve more. The store of the future is watching—not just to protect its assets, but to better serve its customers.
Frequently Asked Questions
1. Does WhaleFlux provide the cameras for retail AI?
WhaleFlux is an infrastructure and platform provider. We provide the AI Compute (GPUs), the Fine-tuningenvironment, and the AI Agent Platform. You can connect your existing high-quality IP cameras to our infrastructure to turn them into an intelligent vision system.
2. How does “Fine-tuning” help in a grocery store setting?
Generic AI models often struggle to tell the difference between different types of produce (e.g., Gala vs. Fuji apples). By using WhaleFlux AI Models & Data, you can fine-tune a model on your specific inventory, allowing for 99%+ accuracy in automated checkout and inventory scanning.
3. Is retail AI computer vision too expensive for mid-sized businesses?
Historically, yes. However, WhaleFlux’s Elastic AI Compute and Observability tools help optimize resource usage, reducing costs by up to 70%. This makes professional-grade computer vision ai retail solutions accessible to mid-market retailers, not just global giants.
4. How does WhaleFlux handle hardware failures in remote store locations?
Our AI Observability tool monitors the health of the GPU clusters in real-time. It can predict hardware stress and potential failures before they happen, reducing downtime by 98% and allowing for proactive maintenance rather than reactive “firefighting.”
5. Can I use the WhaleFlux AI Agent Platform for loss prevention?
Absolutely. You can design an AI Agent that triggers an alert when the vision system detects “suspicious” patterns, such as shelf sweeping or hiding items. The agent can then automatically notify floor security or flag the footage for review, creating a seamless loss-prevention workflow.
The Future of Computer Science in the Age of AI: Evolution or Replacement?
Introduction: The Dawn of the “AI-Native” Computer Science Era
For over half a century, Computer Science (CS) has been defined by the art of writing explicit instructions for machines. We built compilers, optimized databases, and designed intricate algorithms to solve human problems. However, the meteoric rise of Generative AI has sent a shockwave through the industry. Suddenly, the “black box” of neural networks is performing tasks—coding, debugging, and architecting—that were once the exclusive domain of human engineers.

This shift has ignited a polarizing debate: Is AI and computer science a partnership, or is AI a “replacement engine” for the very field that created it? If you browse any tech forum today, you will encounter the same anxious questions: Will computer science be replaced by ai? Is a CS degree still worth it?
The truth is more nuanced than a simple “yes” or “no.” We are witnessing an evolution. We are moving away from the era of “Hand-Coded Logic” and into the era of “AI Orchestration.” In this new landscape, the traditional boundaries of software engineering are blurring, giving way to a more integrated stack where hardware, models, and autonomous agents work in unison. Companies like WhaleFlux are at the forefront of this transition, providing the infrastructure—from Elastic AI Compute to AI Agent Platforms—that allows computer scientists to stop wrestling with raw code and start building intelligent systems.
In this article, we will explore why AI computer science is the most significant career pivot in history, why the focus has shifted from “0-to-1 pre-training” to “strategic fine-tuning,” and how platforms like WhaleFlux are ensuring that the human computer scientist remains the most critical component of the tech stack.
1. The Symbiosis: Understanding AI in Computer Science
To understand the future, we must first define the relationship between ai and computer science. AI is not a separate entity; it is a specialized branch of CS that has grown so powerful it is now “recursive”—it is being used to improve the very discipline from which it emerged.
Traditionally, computer science was about deterministic systems (Input A always yields Output B). AI computer scienceintroduced probabilistic systems (Input A yields the most likely Output B). This transition hasn’t made CS obsolete; it has simply added a new layer of complexity.
The Shift from Coding to Orchestration
In the past, a software engineer spent 80% of their time writing boilerplate code and 20% on system design. Today, AI handles the boilerplate. This allows the modern computer scientist to focus on:
- System Architecture: How do different AI models interact?
- Data Lineage: Is the data used for training clean and ethical?
- Compute Efficiency: How do we run these models without burning through a million-dollar budget?
This is where the concept of a Unified AI Platform becomes essential. WhaleFlux recognizes that the modern CS professional needs more than just a code editor. They need a dashboard that manages the entire lifecycle of an AI application—from the raw NVIDIA GPU compute to the final Autonomous Agent deployment.
2. The Strategic Shift: Why Fine-Tuning is the Real Winner
A common misconception when discussing AI in computer science is that every innovation requires building a model from scratch (0-to-1 pre-training). While companies like OpenAI or Google focus on pre-training foundational models, the rest of the world is realizing that the real value lies in Fine-tuning.
Why Not 0-to-1 Pre-training?
Pre-training a foundation model requires tens of thousands of GPUs, months of time, and billions of dollars. It is a feat of “Brute Force CS.” For 99% of businesses and developers, this is neither practical nor necessary.
The Power of Fine-Tuning on WhaleFlux
Fine-tuning is the process of taking a pre-trained model (like Llama 3 or Mistral) and training it on a smaller, domain-specific dataset to make it an expert in a particular field. This is the “Best AI for computer science” strategy today.
WhaleFlux specifically focuses on this middle-to-end stage of the AI lifecycle. Instead of asking you to build a brain from scratch, WhaleFlux provides:
Elastic AI Compute:
High-performance GPUs (H100, A100, etc.) optimized for the intense but shorter bursts of activity required for fine-tuning.
AI Models & Data Management:
A streamlined environment to upload your proprietary data and refine existing models.
Cost Efficiency:
By focusing on fine-tuning rather than pre-training, companies can achieve “SOTA” (State of the Art) results at 1/100th of the cost.
3. Will AI Take Over Computer Science Jobs?
The fear that AI will take over computer science jobs is understandable but largely misplaced. History shows that when a tool makes a task easier, the demand for that task doesn’t vanish—it explodes.
The Jevons Paradox in Software
When it becomes easier and cheaper to build software (thanks to AI), companies don’t stop building software; they decide to build ten times more of it. We are entering an era where every small business will want its own custom AI agent, every internal tool will need a natural language interface, and every hardware device will need embedded intelligence.
AI won’t replace the computer scientist; it will replace the manual coder. The jobs that are “at risk” are those that involve repetitive, low-level tasks. The jobs that are “exploding” are those that involve:
- AI Infrastructure Management: Managing GPU clusters and ensuring AI Observability.
- Prompt Engineering & Model Steering: Guiding AI to produce accurate, safe results.
- Agentic Workflow Design: Using platforms like the WhaleFlux AI Agent Platform to create autonomous systems that can actually do work, not just talk about it.
4. Redefining the Tech Stack: Compute, Models, and Agents
The traditional “Full Stack Developer” is being replaced by the “AI Stack Orchestrator.” To stay relevant, CS professionals must master a new four-layer stack, which is exactly how WhaleFlux is structured:
Layer 1: AI Compute & Observability
Hardware is the new bottleneck. You cannot do AI computer science without a deep understanding of GPU utilization. WhaleFlux’s AI Observability tools are game-changers here. They provide full-stack visibility, allowing engineers to:
- Reduce hardware failure rates by 98%.
- Slash compute costs by up to 70% through better resource allocation.
- Monitor GPU health in real-time to ensure fine-tuning jobs don’t crash halfway through.
Layer 2: AI Models & Data
This layer involves the selection and “polishing” of models. As mentioned, WhaleFlux facilitates efficient fine-tuning, allowing CS professionals to turn generic AI into specialized tools.
Layer 3: Knowledge & Reasoning
This is where RAG (Retrieval-Augmented Generation) and vector databases come in. It’s about giving the AI a “memory” and a “library” of your specific business data.
Layer 4: AI Agent Platform
This is the pinnacle of the new CS. A “Model” is just a brain in a jar; an “Agent” is a brain with hands and eyes. WhaleFlux’s AI Agent Platform allows developers to build autonomous entities that can observe a system, reason about a problem, and take action.
5. What is the Best AI for Computer Science Success?
If you are a student or a professional asking what the best AI for computer science is, the answer isn’t a specific chatbot. It is a Platform Mindset.
To succeed in 2026 and beyond, you need a platform that unifies these disparate elements. If you spend all your time configuring Linux drivers for GPUs, you aren’t being a computer scientist; you’re being a mechanic. WhaleFlux acts as the “Operating System for AI,” handling the “mechanic” work (infrastructure, observability, compute scaling) so you can focus on the “architect” work (fine-tuning and agent design).
Conclusion: Embracing the AI-Powered Future
So, will computer science be replaced by AI?
The answer is a resounding no. Computer science is not dying; it is graduating. We are moving from the “Digital Age” to the “Intelligence Age.” In this new era, the most successful computer scientists will be those who view AI as their most powerful collaborator.
The future of the field belongs to those who can bridge the gap between raw power and intelligent action. Whether it is through the Elastic AI Compute that powers a fine-tuning job, the AI Observability that keeps a global cluster running, or the AI Agent Platform that automates a complex business process, the tools are now here to amplify human creativity.
WhaleFlux is more than just a service provider; it is the infrastructure for this evolution. By focusing on the critical stages of fine-tuning and agent orchestration, WhaleFlux ensures that enterprises and developers can harness the power of AI without the prohibitive costs or complexity of the past.
The “Computer Scientist” of tomorrow won’t just write code; they will lead a digital workforce of AI agents. The question isn’t whether you will be replaced—it’s what you will build now that the limits have been removed.
Frequently Asked Questions (FAQ)
1. Does WhaleFlux support 0-to-1 model pre-training?
No. WhaleFlux is specialized for the Fine-tuning and inference stages of the AI lifecycle. We provide the elastic compute and model management tools necessary to adapt existing foundation models to specific data and use cases, which is the most cost-effective path for 99% of businesses.
2. Will AI take over computer science jobs in the next few years?
AI will automate many routine programming tasks, but it will not take over the role of a computer scientist. The field is shifting toward AI Orchestration. Professionals who master tools like WhaleFlux to manage GPU resources and deploy AI agents will find themselves in higher demand than ever.
3. What is “AI Observability,” and why is it important for CS?
In ai computer science, hardware is the most expensive asset. AI Observability (like that offered by WhaleFlux) provides deep monitoring of GPU clusters. It can reduce hardware failures by 98% and optimize costs by 70%, making it a critical skill for modern infrastructure engineers.
4. Why should I choose fine-tuning over building a model from scratch?
Building a model from scratch (pre-training) is extremely expensive and time-consuming. Fine-tuning allows you to leverage the “intelligence” of models like Llama 3 while customizing them with your own data. WhaleFlux makes this process seamless and affordable.
5. How does the WhaleFlux AI Agent Platform differ from a standard chatbot?
A chatbot simply answers questions. An AI Agent on the WhaleFlux platform can “Observe, Reason, and Act.” It can be integrated into your business workflows to autonomously perform tasks, making it a functional tool rather than just a conversational interface.
10x Productivity: Unlocking the Real Value of Human-AI Collaborative Workflows
For decades, the conversation around automation followed a predictable, fear-driven script: When will the machines take our jobs? As we navigate through 2026, that narrative has shifted from an existential threat to a strategic opportunity. The most successful organizations have realized that AI is not a replacement for human talent, but a profound multiplier of it.
We have moved beyond the “Replacement Era” and entered the “Augmentation Era.” The goal is no longer to automate humans out of the loop, but to architect Human-AI Collaborative Workflows that unlock a 10x leap in productivity. This isn’t just about working faster; it’s about fundamentally redefining what a single human professional is capable of achieving.
1. The Shift from Tool to Teammate
In the early days of AI, we treated models like digital encyclopedias—calculators for words. You asked a question, and it gave you an answer. Today, AI has evolved into a “Teammate” capable of complex reasoning, multi-step execution, and contextual understanding.
A 10x productivity workflow is built on a simple principle: Assign the “Compute” to the machine and the “Intent” to the human.
- The Machine (AI): Excels at pattern recognition, processing massive datasets, 24/7 monitoring, and initial drafting.
- The Human: Excels at strategic judgment, ethical oversight, nuanced empathy, and high-level creative direction.
When these two forces are synchronized, the bottleneck of “manual labor” disappears, leaving only the speed of thought.
2. The Infrastructure of Augmentation
To achieve 10x productivity, the underlying technology must be invisible and frictionless. If a creative professional has to wait three minutes for a model to respond, or if a developer has to manually manage GPU clusters to test an agent, the “flow state” is broken. Collaboration requires instantaneous power.
This is the core mission of WhaleFlux. To truly augment human capability, you need an environment where AI tools are as responsive as a thought. WhaleFlux provides the high-performance “engine” that powers these collaborative workflows. By unifying Surging Compute with Intelligent Scheduling, WhaleFlux ensures that when a human is ready to collaborate, the AI is ready to execute—without latency, without crashes, and without complexity.
3. Designing the 10x Workflow: Three Core Pillars
Successful augmentation isn’t accidental. It requires a deliberate architectural approach to how humans and AI interact.
I. Rapid Iteration Cycles (The “Sandwich” Method)
The most productive workflows follow a “Sandwich” structure:
- Human: Defines the goal and constraints.
- AI: Generates 10 diverse options or a comprehensive first draft.
- Human: Selects the best path, refines the nuances, and adds the “soul.”
WhaleFlux Impact: To make this cycle “10x,” the AI’s “turn” must be near-instant. WhaleFlux’s optimized model management layer allows for rapid-fire iterations. By reducing the time it takes to micro-tune or prompt a model, WhaleFlux keeps the human creator in the “Zone.”
II. Delegated Autonomy (Agentic Workflows)
Productivity explodes when humans stop managing tasks and start managing Agents. Instead of doing the research, you manage a “Research Agent.”
- WhaleFlux Impact: Running a fleet of agents is computationally heavy. WhaleFlux’s Agent Platform allows users to visually orchestrate these agents. More importantly, WhaleFlux’s Intelligent Dispatching ensures that these agents have the GPU “muscle” to work in the background while the human focuses on higher-level strategy.
III. Full-Stack Observability (The Trust Layer)
Collaboration fails without trust. If a human doesn’t know why an AI made a suggestion, they will spend more time double-checking the work than they saved by using the AI.
- WhaleFlux Impact: WhaleFlux provides Full-Stack Observability. It allows humans to “see inside” the AI’s decision process. This transparency is the “Trust Layer” that allows for true 10x scaling—because you can monitor, audit, and refine the AI’s output in real-time.
4. Real-World 10x Transformations
How does this look in practice across different professional domains?
Software Engineering: From Coding to Architecting
In 2026, senior developers aren’t typing every line of boilerplate code. They use AI agents to generate unit tests, document APIs, and refactor legacy code. The developer has become an Architect, overseeing a squad of AI “Junior Devs” powered by WhaleFlux’s low-latency compute. The result? Features that used to take months now ship in days.
Marketing & Content: The “Market-of-One”
Marketing teams are using collaborative workflows to generate personalized content at a scale previously impossible. A human strategist sets the brand voice; the AI generates 5,000 localized versions of a campaign. WhaleFlux manages the massive model-inference load, ensuring that personalized “Private AI” stays secure and cost-effective.
Data Science: From Cleaning to Insight
Data scientists used to spend 80% of their time cleaning data. Now, autonomous agents handle the “janitorial” work. The human spends their time asking the “What if?” questions, running thousands of simulations on WhaleFlux-optimized GPU clusters to find the one insight that changes the business.
5. The Competitive Advantage: Private Intelligence
The ultimate 10x workflow relies on Context. A generic AI tool can only take you so far. The real value is unlocked when the AI knows your data, your brand, and your proprietary methods.
However, moving that sensitive data to public AI clouds is a risk most enterprises can’t take.
WhaleFlux enables Private AI Intelligence. By allowing you to host and refine your own models on your own terms, WhaleFlux ensures that your collaborative workflows are fueled by your unique competitive secrets—safely. This hardware-level isolation means your 10x productivity boost doesn’t come at the cost of your data sovereignty.
6. Conclusion: The Rise of the “Centaur”
In chess, a “Centaur” is a team consisting of a human and a computer. These teams consistently beat both the best human players and the best computer programs.
The business world of 2026 belongs to the Centaurs.
By embracing Human-AI collaborative workflows, you aren’t just “cutting costs.” You are expanding the horizon of what is possible. You are allowing your team to move from the mundane to the monumental.
But a Centaur is only as fast as its fastest half. To unlock 10x productivity, you need an AI infrastructure that is as agile, powerful, and intelligent as your people.
WhaleFlux is that infrastructure. We provide the “Surging power” and the “Smart Scheduling” required to turn AI from a tool into a teammate.
Stop fearing the machine. Start building with it.
Ready to 10x your team’s output?
Discover WhaleFlux and see how our integrated AI platform can turn your human talent into a superhuman force.
From Generative AI to Predictive AI: The New Frontier of Decision-Making Intelligence
The “First Wave” of the AI revolution was defined by creativity. We marveled as Large Language Models (LLMs) penned poetry, generated photorealistic images, and drafted code from simple natural language prompts. This was the era of Generative AI—a transformative period that democratized content creation and personal productivity.
However, as we move deeper into 2026, the corporate boardroom is asking a different question. Creativity is valuable, but certainty is priceless. Businesses don’t just need AI that can write a marketing plan; they need AI that can tell them which marketing plan will actually work, which supply chain route will fail next Tuesday, and which customer is about to churn before they even know it themselves.
We are entering the Second Wave: Predictive and Prescriptive Intelligence. This is the shift from AI as a “Creator” to AI as a “Decision-Maker.”
1. The Limitation of “Just Generative”
Generative AI is inherently probabilistic regarding content. It predicts the next token in a sentence. While impressive, this “stochastic parroting” lacks a true understanding of cause and effect in the physical and financial world.
In a business context, a generative model might summarize a 100-page financial report perfectly. But it cannot, on its own, correlate that report with real-time geopolitical shifts, internal inventory levels, and fluctuating energy prices to provide a high-confidence forecast of Q4 margins.
Predictive Intelligence requires a different architecture. It demands the integration of structured historical data with unstructured real-time signals. It requires a system that doesn’t just “dream up” possibilities but calculates probabilities.
2. The Infrastructure Challenge of Predictive AI
Predictive models are notoriously data-hungry and compute-intensive in a way that differs from standard chat interfaces. To move from generative to predictive, an enterprise must handle:
High-Velocity Data Ingestion:
Processing millions of data points from IoT sensors, market feeds, and ERP systems.
Massive Parallel Processing:
Running complex simulations (like Monte Carlo methods) at scale.
Continuous Re-training:
Models must stay “fresh” to remain accurate as the world changes.
This is the technical “wall” where many AI projects fail. Traditional cloud environments often lead to skyrocketing costs and latency issues that make real-time prediction impossible.
This is where WhaleFlux
changes the game. To move from “creating content” to “forecasting outcomes,” you need an infrastructure that is built for high-performance execution. WhaleFlux provides the unified compute and model management layer that allows predictive engines to run at peak efficiency without the traditional overhead of fragmented AI stacks.
3. The Three Pillars of Decision-Making Intelligence
To achieve true predictive power in 2026, the industry is converging on three technical pillars:
I. Integrated Observability (The Feedback Loop)
You cannot predict the future if you don’t understand the present. Most AI systems today are “black boxes.” If a predictive model says, “Sales will drop by 10%,” but cannot explain why, no CEO will act on it.
- WhaleFlux Impact: WhaleFlux’s Full-Stack Observability doesn’t just monitor if a system is “up”; it tracks the decision-pathway of the models. By providing transparent insights into how data influences outcomes, WhaleFlux gives leaders the confidence to trust AI-driven forecasts.
II. Compute Orchestration (The Engine)
Predictive AI often involves “bursty” workloads. A retail company might need 1,000% more compute power on a Sunday night to run weekly inventory predictions than it does on a Monday morning.
- WhaleFlux Impact: Through Intelligent GPU Scheduling, WhaleFlux ensures that these massive predictive workloads get the priority they need exactly when they need it. By dynamically shifting resources, WhaleFlux prevents “compute bottlenecks,” ensuring that forecasts are delivered in minutes, not days.
III. Private Data Sovereignty (The Fuel)
The most valuable predictive insights come from your most sensitive data. You cannot send your proprietary trade secrets or customer behavioral data to a public cloud model for prediction without massive risk.
- WhaleFlux Impact: WhaleFlux enables Private AI Intelligence. It allows enterprises to host and refine predictive models within their own secure environment. This means your “Predictive Edge” stays entirely yours, protected by hardware-level isolation.
4. Real-World Applications: Forecasting the Future
The move to Predictive Intelligence is already reshaping core industries:
Manufacturing: The End of “Broken Machines”
Instead of a chatbot telling a technician how to fix a machine (Generative), predictive agents monitor vibration and heat signatures to tell the technician that the machine will break in 48 hours (Predictive). Using WhaleFlux to manage these high-frequency data models, manufacturers are achieving “Zero-Downtime” status.
Retail: Hyper-Accurate Inventory
In 2026, leading retailers no longer overstock. Predictive AI analyzes social media trends, local weather patterns, and historical sales to predict demand at a per-store level. With WhaleFlux optimizing the model micro-adjustments, these companies are reducing waste by up to 30%.
Logistics: Navigating Global Chaos
Global shipping is more volatile than ever. Predictive intelligence allows logistics firms to simulate thousands of “what-if” scenarios regarding port strikes, fuel spikes, or storms. WhaleFlux provides the high-performance environment needed to run these massive simulations in real-time, allowing for instant rerouting.
5. The Preservation of Value: Cost and Performance
The biggest fear of the “Predictive Era” is the cost. Running continuous simulations is expensive.
However, the “WhaleFlux Effect” changes the ROI equation. By optimizing the way models interact with GPUs and automating the lifecycle of the model (from data ingestion to refined output), WhaleFlux helps enterprises reduce their AI operational costs by up to 70%. This makes predictive intelligence accessible not just to the “Big Tech” giants, but to any enterprise ready to modernize its decision-making process.
6. Conclusion: From “What is?” to “What will be?”
The transition from Generative AI to Predictive AI is the transition from Information to Action. In 2026, the competitive advantage belongs to those who can see through the noise of the present to the probabilities of the future. But this vision requires more than just a smart algorithm; it requires a robust, observable, and efficient foundation.
WhaleFlux is that foundation. By unifying the “compute” and the “intelligence,” we enable businesses to stop guessing and start knowing. The frontier of decision-making intelligence is here—and it’s powered by high-performance, private, and observable AI.
Ready to forecast your future?
Discover WhaleFlux and see how our integrated AI platform can turn your data into your most powerful predictive asset.
Build Trustworthy AI: The Critical Role of Your Centralized Knowledge Base
In the race to adopt generative AI, enterprises have encountered a sobering reality check. The very large language models (LLMs) that promise unprecedented efficiency and innovation also harbor a critical flaw: they can, with supreme confidence, present fiction as fact. These “hallucinations” or fabrications aren’t mere bugs; they are inherent traits of models designed to predict the next most plausible word, not to act as verified truth-tellers. For a business, the cost of an AI confidently misquoting a contract, inventing a product feature, or misstating a financial regulation is measured in lost trust, legal liability, and operational chaos.
This crisis of trust threatens to stall the transformative potential of AI. But the solution isn’t to abandon the technology. It’s to ground it in unshakeable reality. The path to Trustworthy AI does not start with a more complex model; it starts with a more organized, accessible, and authoritative foundation: your Centralized Knowledge Base.
The Trust Deficit: Why Raw LLMs Fall Short in Business
A raw, general-purpose LLM is a brilliant but untetered polymath. Its knowledge is broad, static, and fundamentally anonymous.
1. The Black Box of Training:
An LLM’s “knowledge” is a probabilistic amalgamation of its training data—a snapshot of the internet up to a certain date. You cannot ask it, “Where did you learn this?” or “Show me the source document.” This lack of provenance is anathema to business processes requiring audit trails and accountability.
2. The Static Mind:
The world moves fast. Market conditions shift, products iterate, and policies are updated. An LLM frozen in time cannot reflect current reality, making its outputs potentially obsolete or misleading the moment they are generated.
3. The Generalist Trap:
Your company’s value lies in its unique intellectual property—proprietary methodologies, nuanced customer agreements, specialized technical documentation. A generalist LLM has zero innate knowledge of this private universe, leading to generic or, worse, incorrect answers when asked domain-specific questions.
Trustworthy AI, therefore, must be knowledgeable, current, and specialized. It must provide answers that are not just plausible, but verifiably correct.
The Centralized Knowledge Base: The Cornerstone of AI Trust
Imagine if your AI, before answering any question, could consult a single, curated, and constantly updated library containing every piece of information critical to your business. This is the power of pairing AI with a Centralized Knowledge Base.
This is not merely a data dump. A true Centralized Knowledge Base for AI is:
1. Unified:
It aggregates siloed information from across the organization—Confluence wikis, SharePoint repositories, CRM records, ERP databases, Slack archives, and legacy document systems—into a single logical access point.
2. Structured for Retrieval:
Content is processed (cleaned, chunked) and indexed, often using vector embeddings, to allow for semantic search. This means the AI can find information based on meaning and intent, not just keyword matching.
3. Authoritative & Governed:
It represents the “single source of truth.” Governance protocols ensure that only approved, vetted information enters the base, and outdated content is deprecated. This curation is what separates a knowledge base from a data lake.
4. Dynamic:
It is connected to live data sources or has frequent update cycles, ensuring the AI’s foundational knowledge reflects the present state of the business.
The Technical Architecture: From Knowledge to Trusted Answer
This is where the technical magic happens, primarily through a pattern called Retrieval-Augmented Generation (RAG).
1. The Query:
An employee asks, “What is the escalation protocol for a Priority-1 outage in the EU region?”
2. The Retrieval:
The system queries the Centralized Knowledge Base. Using semantic search, it retrieves the most relevant, authoritative chunks of text—the latest incident response playbook, the specific EU compliance annex, and the relevant team contact list.
3. The Augmentation:
These retrieved documents are fed to the LLM as grounding context, alongside the original user question.
4. The Grounded Generation:
The LLM is now instructed: “Answer the user’s question based solely on the provided context below. Do not use your prior knowledge. Cite the source documents for your answer.”
This architecture flips the script. The LLM transitions from a generator of original content to a synthesizer and communicator of verified information. The trust shifts from the opaque model to the transparent, curated knowledge base.
The Implementation Challenge: It’s Not Just Software
Building this system at an enterprise scale is a significant undertaking. The challenges are multifaceted:
1. Data Integration:
Connecting and normalizing data from dozens of disparate, often legacy, systems.
2. Pipeline Engineering:
Creating robust, automated pipelines for ingestion, embedding, and indexing that can handle constant updates without breaking.
3. Performance at Scale:
A RAG system’s user experience hinges on speed. This requires executing two computationally heavy tasks in near real-time: high-speed semantic search across billions of vector embeddings, and running a large LLM inference with a massively expanded context window (the original prompt plus the retrieved documents).
This final challenge—performance at scale—is where the rubber meets the road and where infrastructure becomes the critical enabler or blocker. Deploying and managing the embedding models and multi-billion parameter LLMs required for a responsive, trustworthy AI system demands immense, efficient, and reliable GPU compute power.
This is precisely the challenge that WhaleFlux is designed to solve. As an intelligent GPU resource management platform built for AI enterprises, WhaleFlux transforms complex infrastructure from a bottleneck into a strategic asset. It optimizes workloads across clusters of high-performance NVIDIA GPUs—including the flagship H100 and H200 for training and largest models, the data center workhorse A100, and the versatile RTX 4090 for development and inference. By maximizing GPU utilization and streamlining deployment, WhaleFlux ensures that the retrieval and generation steps of your RAG pipeline are fast, stable, and cost-effective. It provides the observability tools needed to monitor system health and the flexible resource provisioning (through purchase or tailored rental agreements) to scale your Trustworthy AI initiative with confidence. In essence, WhaleFlux provides the powerful, efficient, and manageable computational backbone required to turn the architectural blueprint of a knowledge-grounded AI into a high-performance, production-ready reality.
Use Cases: Trust in Action
When AI is anchored in a centralized knowledge base, it unlocks reliable, high-value applications:
1. Customer Support that Actually Helps:
Agents and chatbots provide answers directly from the latest technical manuals, warranty terms, and service bulletins, slashing resolution time and eliminating policy guesswork.
2. Compliant and Accurate Financial Reporting:
Analysts can query an AI to draft reports or summaries, with every statement grounded in the latest SEC filings, internal audit notes, and accounting standards, ensuring compliance.
3. Onboarding and Expertise Transfer:
New hires interact with an AI that is an expert on internal processes, past project post-mortems, and cultural guidelines, dramatically accelerating proficiency and preserving institutional knowledge.
4. Legal & Contractual Safety:
Legal teams can use AI to review clauses or assess risk, with the model referencing the exact language of master service agreements, regulatory frameworks, and past case summaries stored in the knowledge base.
Conclusion: Trust is a Technical Achievement
Building trustworthy AI is not an abstract goal; it is a concrete engineering outcome. It is achieved by intentionally constructing a system where the LLM’s extraordinary ability to understand and communicate is deliberately constrained and guided by a definitive source of truth. Your Centralized Knowledge Base is that source.
It moves AI from being an entertaining but risky novelty to a reliable, accountable, and invaluable colleague. It transforms AI outputs from something you must skeptically fact-check into something you can inherently trust and act upon. In the age of AI, your competitive advantage will not come from using the biggest model, but from building the most trustworthy one. And that trust is built, byte by byte, in your knowledge base.
5 FAQs on Building Trustworthy AI with a Centralized Knowledge Base
1. What’s the difference between using a Centralized Knowledge Base with RAG versus fine-tuning an LLM on our documents?
Fine-tuning adjusts the style and biases of an LLM’s existing knowledge, teaching it to write or respond in a certain way. It is poor at adding new, specific factual knowledge and is static and expensive to update. RAG with a Centralized Knowledge Base dynamically retrieves and uses your specific facts at the moment of query. This makes RAG superior for ensuring accuracy, providing source citations, and handling constantly changing information, which is core to building trust.
2. How do we ensure the information in our Centralized Knowledge Base is itself accurate and maintained?
The knowledge base requires a governance layer separate from the AI. This involves: 1) Clear Ownership: Assigning data stewards for different domains (e.g., legal, product, support). 2) Defined Processes: Establishing workflows for submitting, reviewing, and publishing new content, and for archiving old content. 3) Integration with Source Systems: Where possible, directly pull from primary systems of record (e.g., CRM, official docs repo) to avoid copy/paste errors. The AI is only as trustworthy as the knowledge you feed it.
3. Is our data safe when used in such a system?
A properly architected RAG system with a centralized knowledge base can enhance security. Unlike sending data to a public API, this architecture can be deployed entirely within your private cloud or VPC. The knowledge base and AI models are accessed internally. Access controls from the knowledge base layer can also propagate, ensuring users only retrieve information they are authorized to see. Always verify your specific implementation meets your compliance standards (SOC 2, HIPAA, GDPR).
4. How do we measure the “trustworthiness” of our AI outputs?
Key metrics include: Citation Accuracy: Does the cited source actually support the generated answer? Answer Relevance: Does the answer directly address the query based on the context? Hallucination Rate: The percentage of answers containing unsupported factual claims. User Feedback: Direct thumbs up/down ratings on answer quality and correctness. Operational Metrics:Reduction in escalations or corrections needed in domains like customer support.
5. Our POC works, but scaling the system is slow and expensive. How can WhaleFlux help?
Scaling a production-grade, knowledge-grounded AI system introduces massive computational demands for vector search and LLM inference. WhaleFlux directly addresses this by providing optimized, managed access to the necessary NVIDIA GPU power (like H100, A100 clusters). It eliminates infrastructure complexity, maximizes hardware utilization to lower cost per query, and provides the observability to ensure system stability. This allows your team to focus on refining the knowledge and application logic, while WhaleFlux ensures the underlying engine performs reliably and efficiently at scale.
WhaleFlux Signals a Shift Toward Architecting Enterprise AI Systems as Enterprise AI Enters a New Phase in 2026
SAN FRANCISCO, Jan. 21, 2026 /PRNewswire/ — As enterprise AI adoption moves beyond experimentation and into production, the industry is entering a new phase where system reliability, governance, and long-term operability matter more than model performance alone. WhaleFlux today announced its positioning as an AI system builder, reflecting a broader shift in how organizations deploy AI at scale.
Over the past decade, rapid advances in foundation models have driven widespread AI experimentation. However, many enterprises now face a different bottleneck: building AI systems that can operate continuously within real-world constraints such as compliance, cost control, and operational stability. As a result, the focus is shifting from developing better models to engineering better systems.
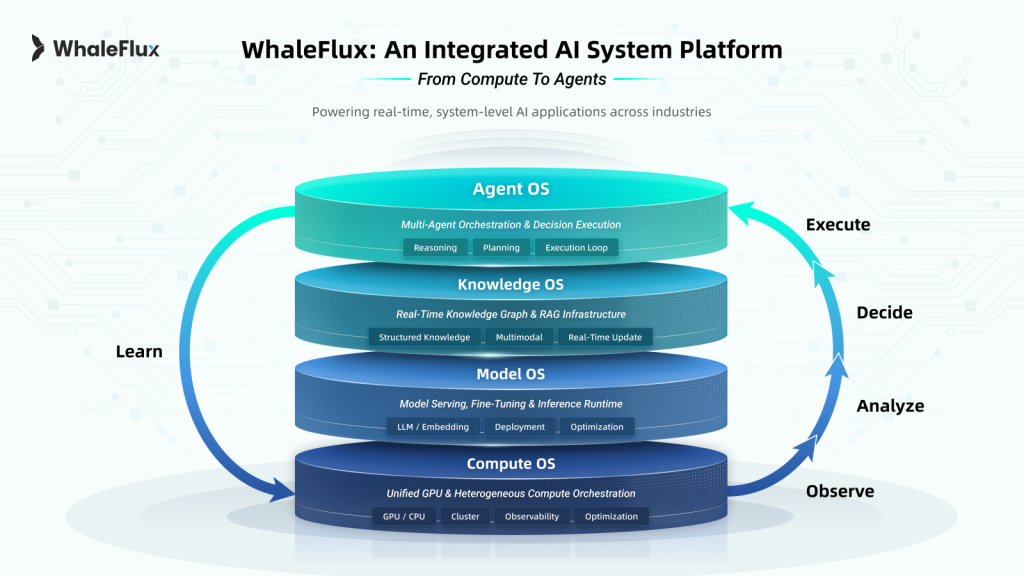
From Model-Centric AI to System-Centric AI
WhaleFlux began as a GPU infrastructure management company and initiated a strategic expansion in early 2025 to address this emerging gap. Rather than focusing on standalone tools or individual models, the company has developed a system-level platform designed for long-running, workflow-oriented enterprise AI.
“At scale, AI systems fail not because models are weak, but because systems are fragile,” said Jolie Li, COO of WhaleFlux. “The challenge is no longer model development — it’s system engineering.”
To support this transition, WhaleFlux consolidated its platform into a unified Compute–Model–Knowledge–Agent architecture, designed to provide enterprises with a stable foundation for production AI.
- Compute Layer — An autonomous scheduling and management engine for private GPU environments, enabling predictable performance, cost efficiency, and operational visibility across heterogeneous hardware.
- Model Layer — An optimized runtime environment for model serving, fine-tuning, and inference, ensuring the scalable deployment and optimization of LLMs and embeddings.
- Knowledge Layer — A secure enterprise knowledge foundation combining Retrieval-Augmented Generation (RAG) with structured access control, allowing AI agents to reason over private data while maintaining strict governance.
- Agent Layer — A workflow orchestration engine that enables multi-step, policy-aware execution, ensuring AI agents operate within predefined operational and compliance boundaries.
Together, these layers support AI workflows that are traceable, controllable, and designed to run reliably over time.
Validated in High-Stakes Industry Environments
Throughout 2025, WhaleFlux deployed its system architecture across regulated and mission-critical settings. In finance, institutional teams used on-premise AI agents for strategy evaluation and risk analysis while keeping sensitive data within private infrastructure. In healthcare, research institutions adopted federated learning workflows to enable collaborative pathology research without transferring patient data. In manufacturing, industrial producers applied AI-assisted modeling to complex chemical and reaction environments, improving visibility where traditional sensing methods are limited.
These deployments reflect growing demand for AI systems designed to operate under real-world constraints rather than controlled laboratory conditions. WhaleFlux also shared system-level insights at global industry events including NVIDIA GTC and GITEX Global.
Looking Ahead
As enterprises enter 2026, WhaleFlux expects AI adoption to increasingly shift toward agent-driven, workflow-oriented systems composed of multiple coordinated components. The company positions itself as an AI system builder, providing the architectural foundation enterprises use to design, deploy, and govern AI systems over time.
About WhaleFlux
Headquartered in San Francisco, WhaleFlux builds system platforms for enterprise AI environments. By integrating GPU compute scheduling, private knowledge management, and intelligent agent orchestration, WhaleFlux helps organizations transform AI capabilities into stable, production-ready systems.
For more information, visit www.whaleflux.com or follow us on LinkedIn
Media Contact
Niki Yan
Head of Marketing, WhaleFlux
Email: niki@whaleflux.com
Website: www.whaleflux.com
The Cost of Intelligence: A Practical Guide to AI’s Total Cost of Ownership
When we talk about AI costs, the conversation often starts and ends with the eye-watering price of training a large model. While training is indeed a major expense, it’s merely the most visible part of a much larger financial iceberg. The true financial impact of an AI initiative—its Total Cost of Ownership (TCO)—is spread across its entire lifecycle: from initial experimentation and training, through deployment and maintenance, to the ongoing cost of serving predictions (inference) at scale. This TCO includes not just explicit cloud bills, but also hidden expenses like energy consumption, engineering overhead, and the opportunity cost of idle resources.
Understanding this full spectrum is crucial for making strategic decisions, ensuring ROI, and building sustainable AI practices. This guide will break down the explicit and hidden costs across the AI lifecycle and provide a framework for smarter financial management.
Part 1: The Upfront Investment: Training and Development Costs
The training phase is the R&D capital of AI. It’s a high-stakes investment with complex cost drivers.
1.1 The Obvious Culprit: Compute Power for Training
This is the cost most people think of. Training modern models, especially large neural networks, requires immense computational power, almost always from expensive GPUs or specialized AI accelerators (like TPUs).
- Hardware Choice Matters: Using an NVIDIA A100 GPU cluster is vastly more expensive per hour than using older generation GPUs or even high-end CPUs, but it can complete the job in a fraction of the time. The calculation is Cost = (Instance Hourly Rate) x (Hours to Convergence).
- The Experimentation Multiplier: A single successful training run is never the whole story. Data scientists run dozens or hundreds of experiments: tuning hyperparameters, testing different architectures, and validating against new data splits. The cumulative cost of all failed or exploratory experiments often dwarfs the cost of the final training job. This is a major hidden cost in the development phase.
1.2 The Data Foundation: Curation, Storage, and Preparation
Before a single calculation happens, there’s the data.
- Acquisition & Labeling: Purchasing datasets or paying for data annotation/labeling can be a significant upfront cost.
- Storage: Storing terabytes of raw and processed data in cloud object storage (like S3) or fast SSDs for active work incurs ongoing costs.
- Processing & Engineering: The compute cost for running data pipelines (using tools like Spark) to clean, transform, and featurize data is a substantial pre-training expense often overlooked in simple models.
1.3 The Human Capital: Development Time and Expertise
The salaries of your data scientists, ML engineers, and researchers are the largest TCO component for many organizations. Inefficient workflows—waiting for resources, debugging environment issues, manually tracking experiments—drastically increase this human cost by slowing down development cycles.
Enter WhaleFlux: This is where an integrated platform shows its value in cost control. WhaleFlux tackles training costs head-on by providing a centralized, managed environment. Its experiment tracking capabilities bring order to the chaotic experimentation phase, allowing teams to reproduce results, avoid redundant runs, and kill underperforming jobs early—directly reducing wasted compute spend. Furthermore, its intelligent resource scheduling can optimize job placement across cost-effective hardware (like leveraging spot instances where possible), making every training dollar more efficient.
Part 2: The Deployment Bridge: Turning Code into Service
A trained model file is useless to a business application. Deploying it is a separate engineering challenge with its own cost profile.
2.1 Infrastructure and Orchestration
- Serving Infrastructure: You need servers (virtual or physical) to host your model API. This means selecting VMs, containers (Kubernetes pods), or serverless functions, each with different cost models (reserved vs. on-demand, per-second billing).
- Orchestration Overhead: Managing Kubernetes clusters or serverless deployments requires dedicated DevOps/MLOps engineering time, a significant hidden operational cost.
2.2 Engineering for Production
Building the actual deployment pipeline—CI/CD, monitoring, logging, security hardening—requires substantial engineering effort. This cost is often buried in broader platform team budgets but is essential and non-trivial.
2.3 The Model “Tax”: Optimization and Conversion
A model trained for peak accuracy is often too bulky and slow for production. The process of model optimization—through techniques like quantization (reducing numerical precision), pruning (removing unnecessary parts of the network), or compilation for specific hardware—requires additional engineering time and compute resources for the conversion process itself.
Part 3: The Long Tail: Inference and Operational Costs
This is where costs scale with success. As your application gains users, inference costs become the dominant, ongoing expense.
3.1 The Per-Prediction Price Tag: Compute for Inference
Every API call costs money.
Hardware Efficiency:
A model running on an underpowered CPU may have a low hourly rate but process requests slowly, hurting user experience. A powerful GPU has a high hourly rate but processes many requests quickly. The key metric is cost per 1,000 inferences (CPTI). Optimizing models and choosing the right hardware (even considering edge devices) is critical to minimizing CPTI.
Load Patterns & Scaling:
Traffic is rarely steady. Provisioning enough servers for peak load means paying for them to sit idle during off-hours. Autoscaling solutions help but add complexity and can have warm-up delays (the “cold start” problem), which impacts both cost and latency.
3.2 The Silent Energy Guzzler
Energy consumption is a direct and growing cost center, both financially and environmentally.A large GPU server can consume over 1,000 watts. At scale, 24/7, this translates to massive electricity bills in your own data center or is baked into the premium of your cloud provider’s rates. Optimizing inference isn’t just about speed; it’s about doing more predictions per watt.
3.3 The Maintenance Burden: Monitoring, Retraining, and Governance
- Observability: You need tools to monitor model performance, data drift, and system health. These tools have their own cost, and analyzing their outputs requires human time.
- Model Decay & Retraining: Models degrade as the world changes. The cost of periodically gathering new data, retraining, and re-deploying updated models is a recurring operational expense over the model’s lifetime.
- Governance & Compliance: Managing model versions, audit trails, and ensuring compliance with regulations (like GDPR) requires processes and tools, contributing to the long-term TCO.
WhaleFlux’s Operational Efficiency: In the inference phase, WhaleFlux directly targets operational spend. Its intelligent model serving can auto-scale based on real-time demand, ensuring you’re not paying for idle resources. Its built-in observability provides clear visibility into performance and cost-per-model metrics, helping teams identify optimization opportunities. By unifying the toolchain, it also reduces the operational overhead and “tool sprawl” that inflates engineering maintenance costs.
Part 4: A Framework for Managing AI TCO
To control costs, you must measure and analyze them holistically.
1.Shift from Project to Product Mindset:
View each model as a product with its own P&L. Account for all lifecycle costs, not just initial development.
2.Implement Cost Attribution:
Use tags and dedicated accounts to track cloud spend down to the specific project, team, and even individual model or training job. You can’t manage what you can’t measure.
3.Optimize Across the Lifecycle:
- Training: Use experiment tracking, early stopping, and consider more efficient model architectures from the start.
- Deployment: Invest in model optimization (quantization, pruning) to reduce inference costs.
- Inference: Right-size hardware, implement auto-scaling, and explore cost-effective hardware options (inferentia chips, etc.).
4.Evaluate Build vs. Buy vs. Platform:
Continually assess if building and maintaining custom infrastructure is more expensive than leveraging a managed platform that consolidates costs and provides efficiency out-of-the-box.
Conclusion: Intelligence on a Budget
The true “Cost of Intelligence” is a marathon, not a sprint. It’s the sum of a thousand small decisions across the model’s lifespan. By looking beyond the sticker shock of training to include deployment complexity, per-prediction economics, energy use, and ongoing maintenance, organizations can move from surprise at the cloud bill to strategic cost governance.
Platforms like WhaleFlux are designed explicitly for this TCO challenge. By integrating the fragmented pieces of the ML lifecycle—from experiment tracking and cost-aware training to optimized serving and unified observability—they provide the visibility and control needed to turn AI from a capital-intensive research project into an efficiently run, cost-predictable engine of business value. The goal is not just to build intelligent models, but to do so intelligently, with a clear and managed total cost of ownership.
FAQs: The Total Cost of AI Ownership
1. Is training or inference usually more expensive?
For most enterprise AI applications that are deployed at scale and used continuously, inference costs almost always surpass training costs over the total lifespan of the model. Training is a large, one-time (or periodic) capital expenditure, while inference is an ongoing operational expense that scales directly with user adoption.
2. What are the most effective ways to reduce inference costs?
The two most powerful levers are: 1) Model Optimization: Quantize and prune your production models to make them smaller and faster. 2) Hardware Right-Sizing: Profile your model to run on the least expensive hardware that meets your latency requirements (e.g., a modern CPU vs. a high-end GPU). Autoscaling to match traffic patterns is also essential.
3. How significant is energy cost in the overall TCO?
It is a major and growing component. For cloud deployments, it’s baked into your compute bill. For on-premise data centers, it’s a direct line-item expense. Energy-efficient models and hardware don’t just reduce environmental impact; they directly lower operational expenditure, especially for high-throughput, 24/7 inference workloads.
4. What is the hidden cost of “idle resources” in AI?
This is a massive hidden cost. It includes: GPUs sitting idle between training jobs or during low-traffic periods, storage for old model versions and datasets that are never used, and development environments that are provisioned but not active. Good platform governance and automated resource scheduling are key to minimizing this waste.
5. How can I justify the TCO of a platform like WhaleFlux to my finance team?
Frame it as a cost consolidation and optimization tool. Instead of presenting it as an extra expense, demonstrate how it reduces waste in the three most expensive areas: 1) Compute: By optimizing training jobs and inference serving. 2) Engineering Time: By automating MLOps tasks and reducing tool sprawl. 3) Risk: By preventing costly production outages and model degradation. The platform’s cost should be offset by its direct savings across these broader budget lines.
The Future of AI Development: AutoML, AI Coders, and Smarter Platforms
Remember the days when building an AI model required a small army of PhDs, months of work, and a bit of magic? That world is fading fast. Today, a new wave of tools is making artificial intelligence more accessible, turning what was once an exclusive art into something closer to a mainstream skill. This isn’t just a minor upgrade; it’s a fundamental shift in who can build AI and how it gets done.
At the heart of this change are three key trends: AutoML (Automated Machine Learning), AI-Assisted Programming, and the rise of AI Agents. Together, they are breaking down barriers and ushering in an era of “democratized AI.” For businesses, this means faster innovation and the ability to solve complex problems without needing a team of elite experts. To support this new way of working, integrated platforms like WhaleFlux are emerging, offering all-in-one solutions that bundle the necessary tools, while specialized custom AI services tackle the unique, deep challenges of specific industries.
1. From Manual Craft to Automated Factories: The Rise of AutoML
Think of the early stages of machine learning as handcrafting a watch. Every tiny gear (data feature) had to be perfectly shaped, and the mechanism (model) painstakingly tuned by a master craftsperson (the data scientist). This process was slow, expensive, and limited to only the most valuable problems.
AutoML changes this dynamic entirely. It automates the most tedious and expertise-heavy parts of the process:
- Feature Engineering: Automatically identifying and creating the most relevant data inputs.
- Model Selection: Testing dozens of algorithms to find the best one for your specific task.
- Hyperparameter Tuning: Fine-tuning the model’s internal settings for optimal performance—a task once compared to “searching for a needle in a haystack while blindfolded.”
What This Means for You
The impact is profound. A marketing analyst can now build a customer churn prediction model by simply pointing the AutoML tool at their CRM data. A manufacturing engineer can create a quality control model for their production line without writing a single line of complex code. The barrier shifts from “Do I have the technical skills?” to “Do I understand my business problem?”
2. Your New Teammate: AI-Assisted Programming
If AutoML automates the data science side, AI-assisted programming is revolutionizing the software development that brings AI to life. Tools like GitHub Copilot, powered by large language models (LLMs), act as a supercharged pair programmer.
This is more than just fancy autocomplete. It’s a shift in the very paradigm of development:
- From Code to Conversation: Developers can describe a function in plain English—”create a function that fetches user data and calculates the average session length”—and the AI suggests the complete code block.
- Context-Aware Assistance: These tools understand the context of your entire project, helping you navigate different files, adhere to your code style, and even write documentation or tests.
- Democratizing Development: It lowers the barrier for entry, helping junior developers code with more confidence and enabling subject-matter experts (like a biologist or a financial analyst) to script their own data processing tasks.
The result? Faster development cycles, fewer repetitive tasks, and developers freed to focus on high-level architecture and creative problem-solving.
3. Beyond Code: AI Agents Take Action
The next evolutionary step is AI Agents. While a traditional AI model might recognize an image or generate text, an AI Agent can take action. It perceives its environment (like a dashboard or a database), makes decisions, and uses tools (APIs, software, other models) to accomplish a multi-step goal.
Imagine an AI Agent that could:
- Monitor your e-commerce website, identify a sudden drop in checkout conversions, diagnose the cause (e.g., a broken payment gateway), and execute a fix by triggering an alert or even rolling back a recent code change.
- Act as a 24/7 customer service agent that doesn’t just answer FAQs but can actually process returns, schedule appointments, and update customer records by navigating multiple internal systems.
This moves AI from being a passive tool to an active, autonomous teammate. The developer’s role evolves from writing every line of logic to defining the agent’s goals, providing it with the right tools, and setting up safeguards for its actions.
4. The Need for a Unified Home: All-in-One Platforms
As powerful as these trends are, they can also create complexity. Juggling separate tools for data, training, coding, and deployment leads to “tool sprawl.” This is where integrated platforms become essential.
A platform like WhaleFlux is designed to be the cohesive hub for this new era of AI development. It addresses the fragmentation by integrating five critical pillars into a single, streamlined environment:
- Unified Compute Power: It intelligently manages the underlying computing resources (CPUs, GPUs), so you don’t have to worry about infrastructure. You can train a model with the power you need, when you need it.
- Centralized Model Hub: Instead of models scattered across laptops and servers, WhaleFlux provides a central registry to manage, version, and deploy your AutoML-generated models, open-source LLMs, or custom creations.
- Managed Data Workflows: It offers tools to connect, clean, and prepare your data—the crucial fuel for any AI project—in a way that feeds seamlessly into the training pipelines.
- AI Agent Orchestration: Crucially, it provides the environment to build, test, and deploy those intelligent AI Agents. You can visually design their workflows, equip them with tools, and manage their interactions.
- AI Observability: This is the critical guardrail. It’s not enough to deploy an Agent; you need to monitor its performance, decisions, and costs in real-time. Observability tools help you understand why your model or Agent made a decision, ensuring trust, compliance, and continuous improvement.
By bringing these elements together, a platform like WhaleFlux turns a fragmented, high-friction process into a smooth, end-to-end workflow. It empowers smaller teams to execute projects that once required large, specialized departments.
5. The Human Touch: Custom AI Services for Deep Challenges
While platforms democratize access, some challenges require a surgeon’s scalpel, not a Swiss Army knife. Highly specialized industries like healthcare, advanced manufacturing, or quantitative finance face problems that are deeply unique. Their data is sensitive, their regulations strict, and their success metrics highly specific.
This is where custom AI services play an irreplaceable role. These services operate independently of any single platform like WhaleFlux. They involve expert consultants and engineers who:
- Dive deep into the client’s proprietary business logic and constraints.
- Design custom architectures and train bespoke models on domain-specific data (e.g., medical images, semiconductor sensor data).
- Integrate the solution directly into legacy, on-premise, or highly secure environments where off-the-shelf platforms can’t go.
These services are about deep partnership and tailored craftsmanship. They solve the “last mile” problems that generalized tools cannot, ensuring that AI doesn’t just work in theory but delivers tangible, strategic value in the most complex scenarios.
6. Looking Ahead: A More Accessible and Powerful Future
The trajectory is clear. The future of AI development is democratized, automated, and action-oriented.
- Democratized: More people—analysts, engineers, designers—will have the power to leverage AI in their daily work.
- Automated: Repetitive tasks in coding and model building will increasingly be handled by AI itself, boosting productivity.
- Action-Oriented: AI will graduate from generating insights to taking safe, supervised actions that drive real business outcomes.
For organizations, the winning strategy is a two-pronged approach: Leverage integrated platforms like WhaleFlux to empower your teams, accelerate experimentation, and build a wide range of intelligent applications efficiently. For your most critical, complex, and proprietary challenges, partner with experts who provide custom AI services to build a durable competitive advantage.
The age of AI exclusivity is over. The future belongs to those who can best harness these new tools and paradigms to solve real-world problems.
From Pixels to Predictions: Optimizing Image Inference for Business AI
I. Introduction: The Power of Image Inference in Today’s AI
Look around. Artificial intelligence is learning to see. It’s the technology that allows a self-driving car to identify a pedestrian, a factory camera to spot a microscopic defect on a production line, and a medical system to flag a potential tumor in an X-ray. This capability—where AI analyzes and extracts meaning from visual data—is called image inference, and it’s fundamentally changing how industries operate.
Image inference moves AI from the laboratory into the real world, transforming pixels into actionable predictions. However, this power comes with a significant computational demand. Processing high-resolution images or analyzing thousands of video streams in real-time requires immense, reliably managed computing power. For businesses, the challenge isn’t just building a accurate model; it’s deploying it in a way that is fast, stable, and doesn’t consume the entire budget. This is where the journey from a promising algorithm to a profitable application begins.
II. What is Image Inference and How Does it Work?
A. The Lifecycle of an Image for Inference
The journey of an image through an AI system is a fascinating, multi-stage process. It begins the moment a picture is captured, whether by a smartphone, a security camera, or a medical scanner. This raw image is then preprocessed—resized, normalized, and formatted into a structure the AI model can understand. Think of this as preparing a specimen for a microscope.
Next comes the core act of inference image analysis. The preprocessed image is fed into a pre-trained deep learning model, such as a Convolutional Neural Network (CNN). The model’s layers of artificial neurons work in concert to detect patterns, features, and objects, ultimately producing an output. This could be a simple label (“cat”), a bounding box around an object of interest, a segmented image highlighting specific areas, or even a new, generated image. This entire pipeline—from upload to insight—must be optimized for speed and efficiency to be useful.
B. Key Requirements for Effective Image Inference
For an image inference system to be successful in a business environment, it must excel in three critical areas:
Speed (Low Latency):
In applications like autonomous driving or interactive video filters, delays are unacceptable. Low latency—the time between receiving an image and delivering a prediction—is non-negotiable for real-time decision-making.
Accuracy:
The entire system is pointless if the predictions are wrong. The deployed model must maintain the high accuracy it achieved during training, which requires stable, consistent computational performance without errors or interruptions.
Cost-Efficiency at Scale:
A model that works perfectly for a hundred images becomes a financial nightmare at a million images. The infrastructure must be designed to process vast quantities of visual data at a sustainable cost-per-image, enabling the business to scale without going bankrupt.
III. The GPU: The Engine of Modern Image Inference
A. Why GPUs are Ideal for Image Workloads
At the heart of every modern image inference system is the Graphics Processing Unit (GPU). Originally designed for rendering complex video game graphics, GPUs have a particular talent that makes them perfect for AI: parallel processing. Unlike a standard CPU that excels at doing one thing at a time very quickly, a GPU is designed to perform thousands of simpler calculations simultaneously.
An image is essentially a massive grid of pixels, and analyzing it requires performing similar mathematical operations on each of these data points. A GPU can handle this enormous workload in parallel, dramatically speeding up the image inference process. Trying to run a complex vision model on CPUs alone would be like having a single cashier in a busy supermarket; the line would move impossibly slowly. A GPU, in contrast, opens all the checkouts at once.
B. Matching NVIDIA GPUs to Your Image Inference Needs
Not all visual AI tasks are the same, and fortunately, not all GPUs are either. Selecting the right hardware is crucial for balancing performance and budget:
NVIDIA A100/H100/H200:
These are the data center powerhouses. They are designed for large-scale, complex inference image tasks that require processing huge batches of high-resolution images simultaneously. Think of a medical imaging company analyzing thousands of high-resolution MRI scans overnight. The massive memory and computational throughput of these GPUs make such workloads feasible.
NVIDIA RTX 4090:
This GPU serves as an excellent, cost-effective solution for real-time video streams, prototyping, and deploying smaller models. For a startup building a real-time content moderation system for live video, the RTX 4090 offers a compelling balance of performance and affordability.
IV. Overcoming Bottlenecks in Image Inference Deployment
A. Common Challenges with Image Workloads
Despite having powerful GPUs, companies often hit significant roadblocks when deploying image inference at scale:
Unpredictable Latency Spikes:
When multiple inference requests hit a poorly managed system at once, they can create a traffic jam. A single request for a complex analysis can block others, causing delays that ruin the user experience in real-time applications.
Inefficient GPU Usage and High Costs:
GPUs are expensive, and many companies fail to use them to their full potential. It’s common to see GPUs sitting idle for periods or not processing images at their maximum capacity, leading to a high cost-per-inference without delivering corresponding value.
The Batch vs. Real-Time Dilemma:
Managing the infrastructure for different types of workloads—such as scheduled batch processing of millions of product images versus live analysis of security camera feeds—adds another layer of operational complexity.
B. The WhaleFlux Solution: Smart Management for Visual AI
These bottlenecks aren’t just hardware problems; they are resource management problems. This is precisely the challenge WhaleFlux is built to solve. WhaleFlux is an intelligent GPU resource management platform that acts as a high-efficiency orchestrator for your visual AI workloads, ensuring your computational power is used effectively, not just expensively.
V. How WhaleFlux Optimizes Image Inference Pipelines
A. Intelligent Scheduling for Consistent Performance
WhaleFlux’s core intelligence lies in its smart scheduling technology. Instead of allowing inference requests to collide and create bottlenecks, the platform dynamically allocates them across the entire available GPU cluster. This ensures that no single GPU becomes overwhelmed, maintaining consistently low latency even during traffic spikes. For a real-time application like autonomous vehicle perception, this consistent performance is not just convenient—it’s critical for safety.
B. A Tailored GPU Fleet for Every Visual Task
We provide access to a curated fleet of industry-leading NVIDIA GPUs, including the H100, H200, A100, and RTX 4090. This allows you to precisely match your hardware to your specific images for inference needs. You can deploy powerful A100s for your most demanding batch analysis jobs while using a cluster of cost-effective RTX 4090s for high-volume, real-time video streams.
To provide the stability required for 24/7 image processing services, we offer flexible purchase or rental options with a minimum one-month term. This approach eliminates the cost volatility of per-second cloud billing and provides a predictable infrastructure cost, making financial planning straightforward.
C. Maximizing Throughput and Minimizing Cost
The ultimate financial benefit of WhaleFlux comes from maximizing GPU utilization. By ensuring that every GPU in your cluster is working efficiently and minimizing idle time, WhaleFlux directly drives down your cost-per-image. This “images-per-dollar” metric is crucial for profitability. When you can process more images with the same hardware investment, you unlock new opportunities for scale and growth, making large-scale visual AI projects economically viable.
VI. Conclusion: Building Scalable and Reliable Visual AI with WhaleFlux
The ability to reliably understand and interpret visual data is a transformative competitive advantage. Robust and efficient image inference is the key that unlocks this value, turning passive pixels into proactive insights.
The path to deploying scalable visual AI doesn’t have to be fraught with performance nightmares and budget overruns. WhaleFlux provides the managed GPU infrastructure and intelligent orchestration needed to deploy your image-based models with confidence. We provide the tools to ensure your AI is not only accurate but also fast, stable, and cost-effective.
Ready to power your visual AI applications and build a more intelligent business? Explore how WhaleFlux can optimize your image inference pipeline and help you see the world more clearly.
FAQs
1. What makes image inference a critical but resource-intensive task for business AI applications?
Image inference, the process of using trained models to analyze and extract information from new images, is fundamental to countless business applications—from automated visual quality inspection in manufacturing to real-time product recognition in retail and medical image analysis. However, these tasks are computationally demanding. Models must process high-dimensional pixel data in real-time or near real-time to deliver business value, placing significant strain on infrastructure. Choosing the right optimization strategy and hardware is therefore not just a technical concern, but a direct driver of operational efficiency, scalability, and cost-effectiveness . The goal for Business AI is to transform raw pixels into reliable predictions as fast and as affordably as possible.
2. What are some key pre-processing and architectural techniques to optimize image inference performance before scaling?
Performance optimization begins long before deployment. Key techniques include:
- Intelligent Pre-processing: Instead of feeding entire images into a model, a common and effective strategy is to first use an object detection network to crop the image around the region of interest . This focuses the model’s computational power on relevant pixels, reduces input size (e.g., cropping can remove over 50% of irrelevant pixels in some medical images), and can significantly improve accuracy by normalizing the scale of the subject .
- Task-Specific Architecture Design: For tasks combining images with other data (like text or sensor readings), feeding raw pixels directly into a standard neural network is inefficient. A better approach is to design specialized model architectures that process image features and other high-level data through separate pathways before combining them, leading to more meaningful learning and better inference .
- Method Selection (Prompt vs. Fine-Tuning): For many business use cases, you may not need to train a model from scratch. For simpler, well-defined tasks, prompt engineering on a powerful pre-trained vision model can be a low-cost, rapid solution. For complex, high-precision, or long-term deployment needs, Supervised Fine-Tuning (SFT) on domain-specific data is necessary to achieve the required accuracy and output stability .
3. What are the main GPU resource management challenges when deploying image inference at scale?
Scaling image inference efficiently is hindered by several key challenges in GPU cluster management:
- Resource Fragmentation and Low Utilization: Static allocation of GPUs often leads to severe inefficiency. While some GPUs are overloaded with inference requests (creating “hot spots”), others sit idle (“cold spots”), dragging down the cluster’s average utilization—a common problem where rates can fall below 50% .
- Diverse and Dynamic Workloads: An inference cluster must handle a mix of tasks with different requirements: high-throughput batch processing, low-latency real-time requests, and varying model sizes. Managing these priorities without intelligent scheduling leads to long job queues, missed latency targets, and wasted resources .
- Complex Orchestration Overhead: Manually managing the lifecycle of hundreds of inference jobs across a multi-GPU cluster, ensuring health checks, load balancing, and recovery from failures, becomes a major operational burden that distracts teams from core AI development .
4. How do advanced scheduling and load balancing strategies address these GPU challenges?
Modern resource management systems employ sophisticated strategies to “tame” the cluster:
- Dynamic, Graph-Based Scheduling: Advanced schedulers treat the cluster’s resources (CPUs, GPUs, memory, network) as a interconnected graph. This allows for fine-grained, topology-aware scheduling, placing tasks on GPUs that are physically or network-optimally close to their data, minimizing communication delays and maximizing throughput .
- Priority and Preemptive Scheduling: Systems can implement weighted fair queueing or priority-based scheduling to ensure critical business inference jobs (e.g., real-time customer-facing apps) are served before less urgent batch jobs . In some cases, low-priority tasks can be preempted to free up resources for high-priority ones, with checkpoints enabling seamless resumption later .
- Intelligent Load Balancing: Beyond simple round-robin, schedulers perform least-load-first allocation, directing new inference requests to the GPU with the most available memory and lowest compute utilization. For distributed inference jobs, they also handle model or data parallelism to split work efficiently across multiple GPUs .
5. How does a specialized platform like WhaleFlux provide an integrated solution for efficient, large-scale image inference?
WhaleFlux is an intelligent GPU resource management tool designed specifically to solve the end-to-end challenges of deploying AI models like image inference systems. It moves beyond mere hardware provision to deliver optimized efficiency.
- Unified Optimization Layer: WhaleFlux integrates the advanced scheduling and load balancing strategies mentioned above into a seamless platform. It actively monitors the cluster, packing inference jobs intelligently to eliminate idle time and resource fragmentation, thereby dramatically increasing the utilization of valuable NVIDIA GPUs (such as the H100, A100, or RTX 4090) .
- Stability and Cost Efficiency for Business AI: By ensuring stable, high-throughput execution of inference workloads, WhaleFlux allows businesses to serve more predictions with fewer hardware resources. This directly translates to lower cloud computing costs and a more predictable total cost of ownership. Companies can access these optimized NVIDIA GPUresources through flexible purchase or rental plans tailored to their sustained workload needs.
- Focus on Core Innovation: By abstracting away the immense complexity of cluster orchestration, WhaleFlux allows AI and data science teams to focus entirely on developing and refining their image models and business logic, accelerating the path from prototype to production-scale deployment.