Scalable AI Compute
for Enterprise Workloads
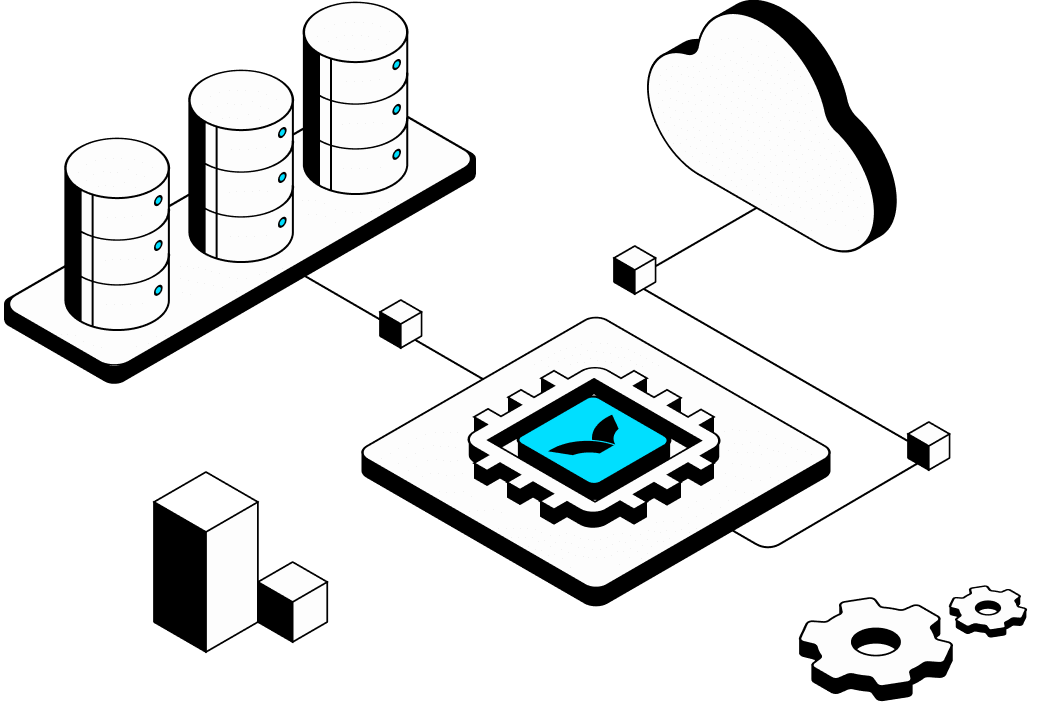
Provision the right GPUs for any workload in minutes, not weeks. WhaleFlux delivers high utilization, seamless scaling, and predictable pricing, giving you the efficiency and agility to outpace the competition.
Maximize GPU ROI
Cut infrastructure costs and maintain peak performance through automated scheduling, GPU partitioning, and elastic scaling.

Eliminate Idle Resource Costs
Maximize cluster utilization via intelligent scheduling and GPU partitioning, fundamentally eliminating waste from idle resources.

Elastic Auto-Scaling
Seamlessly scale from a single GPU to thousands with one click. Maintain capacity for traffic spikes while minimizing costs during off-peak hours, achieving true pay-as-you-go efficiency.
Unified Visibility & Control
Monitor GPU metrics, workload performance, and resource allocation in real-time. Quickly identify bottlenecks to ensure system stability.

Achieve Clear Cost Tracking
Accurately track GPU consumption and compute spend for every project and task. Transform fragmented cloud billing into actionable dashboards.
10x
Faster Deployment
80%
Higher Scheduling Efficiency
98%
Reduction in Cluster Failures
70%
Savings on Compute Costs
Compute Built for AI Scale
Maximize your GPU ROI with intelligent management that automatically optimizes for performance and cost. Deploy in seconds, scale on demand, and focus on what matters: building better AI, faster.


Simplified Cluster Management

Manage diverse GPUs and multi-cloud resources from a single dashboard.
Automatically analyze and assign workloads to the most efficient GPU instances.
Eliminate compatibility issues with native support for 20+ hardware types.

Cost-Efficient Auto-Scaling
Automatically pack workloads onto optimal nodes to minimize compute spend.
Instantly scale up resources when inference demand spikes.
Focus on engineering, not infrastructure, with fully automated resource management.

Peak Performance
Intelligently match tasks to optimal GPUs to eliminate idle time and reduce queuing.
Proactively monitor metrics to fix bottlenecks before they impact workloads.
Get maximum throughput and ROI from every provisioned GPU.

Enterprise-Grade Security
Ensure complete data privacy with strict multi-tenant isolation across teams and projects.
Automatically migrate workloads from faulty hardware to maintain high availability.
Meet compliance requirements with clear, traceable audit logs and role-based access control (RBAC).
AI Compute in Action
From accelerating fine-tuning pipelines to powering real-time inference, explore how our elastic GPU resources drive efficiency across diverse AI workloads.

Scenario 1: AI Research Teams
“With GPU partitioning and elastic scheduling, our team boosted GPU utilization from 30% to 85%—accelerating model iteration by 5x while maintaining full control over our environment.”

Scenario 2: Enterprise AI Deployment
“The flexible GPU rental model allows us to handle demand fluctuations while saving 40% on infrastructure costs. Deployment time for new AI services dropped from weeks to hours.”

Scenario 3: AI Startups
“WhaleFlux’s elastic GPU access enabled us to scale from 4 to 40 GPUs overnight for a sudden client project, without heavy upfront hardware investment. The pay-monthly model perfectly aligns with our cash flow.”
Scenario 1: AI Research Teams
“With GPU partitioning and elastic scheduling, our research team increased GPU utilization from 30% to 85%, accelerating model iteration speed by 5x while maintaining full control over our research environment.”
Scenario 2: Enterprise AI Deployment
“The monthly GPU rental model allows us to flexibly handle project demand fluctuations while saving 40% on infrastructure costs. Deployment time for new AI services has been reduced from weeks to hours.”
Scenario 3: Startup AI Development
“As a growing startup, WhaleFlux’s flexible GPU access enabled us to scale from 4 to 40 GPUs overnight to handle a sudden client project, without any upfront hardware investment. The pay-monthly model perfectly aligns with our cash flow needs.”
Enterprise-Grade Infrastructure
Behind the simplicity of our platform lies a deeply engineered foundation. We ensure your AI workloads are seamless, efficient, and secure by design.

Enterprise SLA
99.9% uptime guarantee

AI-Optimized Scheduling
Purpose-built algorithms for AI workloads

Unified Management
A single dashboard for all GPU resources

Flexible Rental Terms
On-demand scaling with no hidden fees
High-Performance GPUs
Access a wide range of top-tier GPUs tailored to your AI workloads — from NVIDIA H200, H100, A100, to RTX 4090 and beyond. Choose the right resources for your project.
View GPU Pricing
Frequently Asked Questions
Everything you need to know about WhaleFlux Compute.
We provide performance-optimized templates for different scenarios—H100/H200 for large-scale fine-tuning, A100 for general workloads, and RTX 4090 for development and inference. Our intelligent scheduling automatically provisions the most cost-effective GPU resources.
Purchasing provides dedicated hardware for long-term predictability, while flexible renting (minimum 1 month) offers agility for temporary needs. Both options include full management features and seamlessly integrate into your resource pool.
Scale compute instances in minutes via our web dashboard or API. Our elastic resource management automatically adapts to workload demands with zero downtime.
We employ multi-zone deployments with automated failover. If hardware fails, your workloads automatically migrate to healthy nodes, ensuring data integrity and uninterrupted service.
Yes. Use our image management to deploy custom Docker images with your specific frameworks. Once uploaded, these serve as reusable templates for consistent deployments across your team.
Our intelligent scheduler queues and packs jobs based on resource availability and priority. It automatically allocates optimal GPU resources and provides real-time progress tracking with detailed logs.
We offer high-speed NVMe SSDs for active fine-tuning datasets, object storage for model artifacts, and mountable file systems for shared access. All storage features automated backups and elastic scaling.
Each instance provides real-time metrics including GPU utilization, memory usage, and temperature. Access detailed logs and node status via the dashboard, and set up custom alerts for any performance anomalies.
Absolutely. Our instance templates capture the complete environment configuration—including GPU specs, storage, and container images. Deploy identical environments from development to production seamlessly.
Our monitoring system instantly detects node failures and automatically resubmits interrupted jobs to healthy instances. Combined with persistent storage and checkpoint management, your fine-tuning progress is fully protected.