WhaleFlux
は AI ワーク ロードにおいて最適なパフォーマンスを実現します
AI モデルの微調整、タスク固有の適応、シームレスな展開、スケーラブルな推論を実現するオールインワン プラットフォームで、実際のアプリケーションに信頼性が高くコスト効率の高いソリューションを実現します。
WhaleFluxが提供するもの

手頃な価格で堅牢かつ効率的なAIインフラ
最小限のレイテンシと最大限の信頼性で高性能 AI モデルを強化するように設計された、シームレスにスケーラブルなインフラストラクチャ。

安定的、簡単、信頼性の高い AI モデル運用
AI モデルの導入、監視、最適化のためのエンドツーエンドの自動化により、簡単な操作と最高の安定性を実現します。

業界AIソリューション
AI の専門知識と業界知識を結び付けて変革をもたらします。
WhaleFluxは達成できる
99.9 %
GPU 使用率
5 x
処理されたリクエスト
99.9 %
GPU 稼働時間
60 %
推論の遅延が減少

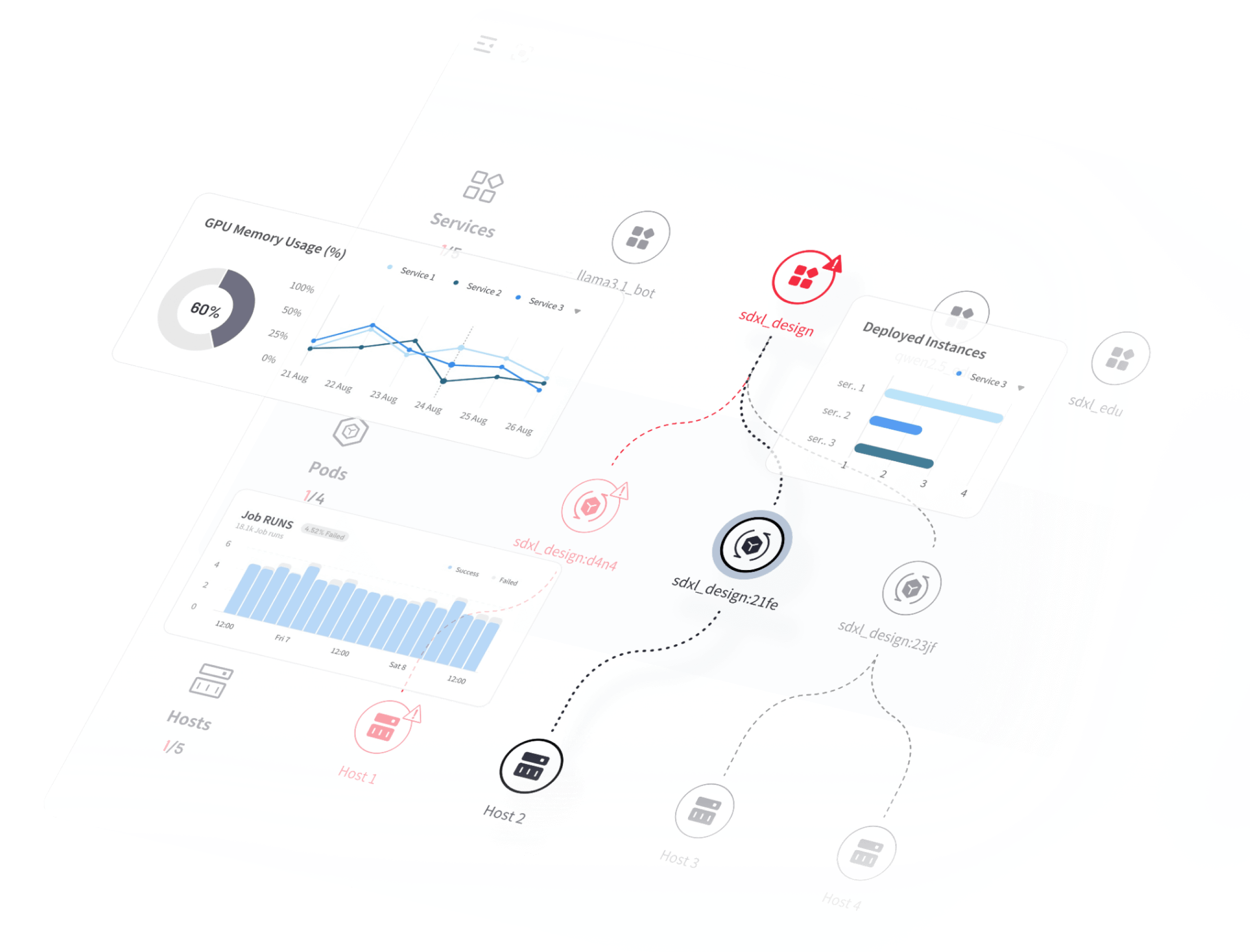
モデル運用とライフサイクル管理
- AIモデルを本番環境に導入するためのワンストップソリューション
- 高速かつ自動的なエンドポイント開発
- Docker をプリセットしてモデルをコンテナ化し、GPU で即座に実行します
- 複数のPythonフレームワークをサポート
より迅速な導入
10x遅延
減少
60%
コスト
節約
70%
GPU
稼働時間
99.9%

比類のないモデル推論
ライフサイクルにおけるパフォーマンス
- 最も効率的なAIジョブ実行のためのスマートなリソースマッチング
- GPUからモデル、アプリケーションまでAIモデルのフルスタックを詳細に観察
- 迅速な欠陥検出、アラート、自己修復
- 推論中の継続的かつ動的な最適化と自動スケーリング
処理済み
ジョブの増加
5x
遅延
減少
60%
自動スケーリング
応答
0.001s

アクセスしやすく、高品質で、手頃な
価格モデル提供リソース
- あなたのクラウドでもWhaleFluxの最高品質のクラスターでも
- 推論ジョブに一致する自動 AI モデル サービス リソース構成
- 価格は30%、パフォーマンスは5倍
- 99.9の稼働率、潜在能力を最大限に発揮
推論あたりのコスト
減少
80%
GPU価格
値下げ
70%
利用率
99.9%
コンピューティング パフォーマ
ンスとリソースの最適化
- 1 つのダッシュボードでインテリジェントかつ統合されたマルチクラスター リソース管理を実現
- 柔軟なコンピューティング スケジューリング
- リアルタイムの障害検出と自己修復メカニズム
- 自動化された分離とタスク移行による最高のジョブプロセスセキュリティ
利用率
99.9%MTTR
減少
90%
GPU
Uptime
99.9%
業界AIソリューション
- 業界固有のエンドツーエンドのソリューション提供
- 期待されるパラダイムによる結果の精度
- マルチモーダル適応
- RAGとナレッジグラフで業界の要件を満たす
- 企業向けデータコンプライアンス
結果
精度
99.9%
ROIタイムラ
イン 減少
90%

WhaleFlux の動作を確認する準備はできましたか?
シームレスな展開と優れた推論パフォーマンスを実現するように設計されたプラットフォームである WhaleFlux を使用して、AI モデルを簡単に最適化および管理します。
