Full-Stack AI
Observability:From GPU
to Agent
Gain real-time insights across your entire AI stack—from GPU clusters to model fine-tuning and AI agents. Ensure optimal performance and reliability with proactive alerts.
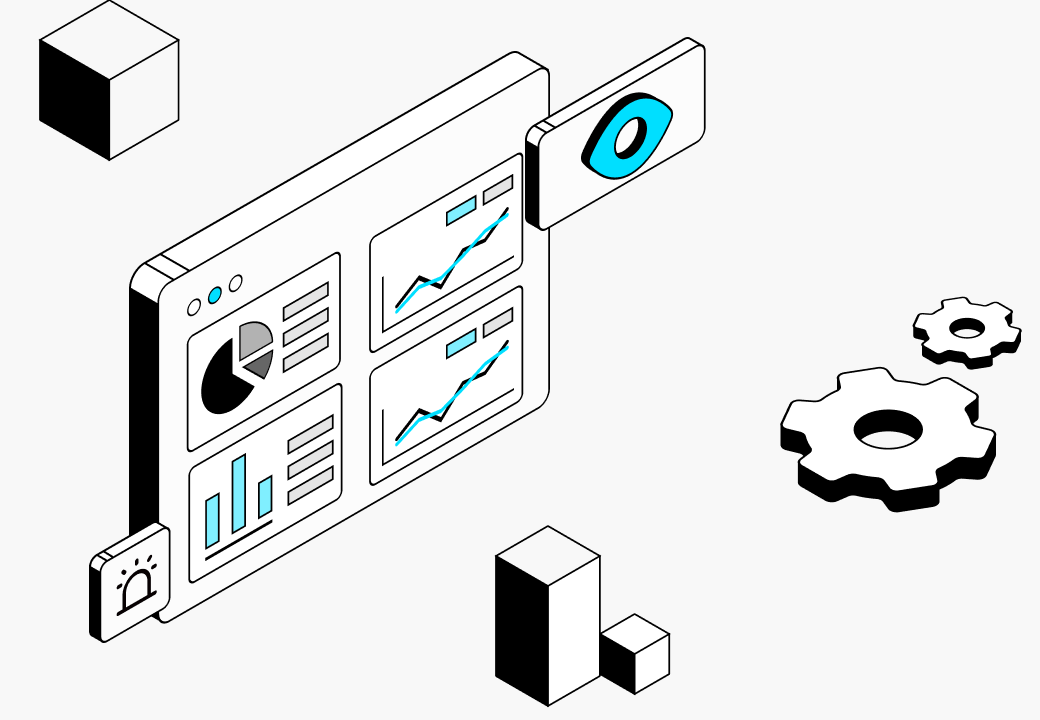
The Power of AI Observability
Gain end-to-end visibility and precise control over your AI stack. Transform complex data into reliable performance and faster innovation.
Optimize compute costs and model control

Identify failure modes instantly

Meet SLAs and compliance requirements

Trace end-to-end workflows

Ensure model quality

Accelerate AI innovation
How WhaleFlux Empowers Your AI Observability
Our unified platform provides a single source of truth for your entire AI stack. Move from reactive monitoring to closed-loop management with intelligent alerts and self-healing capabilities.
Proactive Infrastructure Monitoring
Challenge
Infrastructure issues often go unnoticed until services are disrupted.
WhaleFlux enables you to:

Monitor cluster health and GPU utilization in real-time.
Visualize service dependencies through dynamic topology mapping.
Configure intelligent alerts across 30+ performance metrics.
Prevent resource bottlenecks through predictive capacity planning.

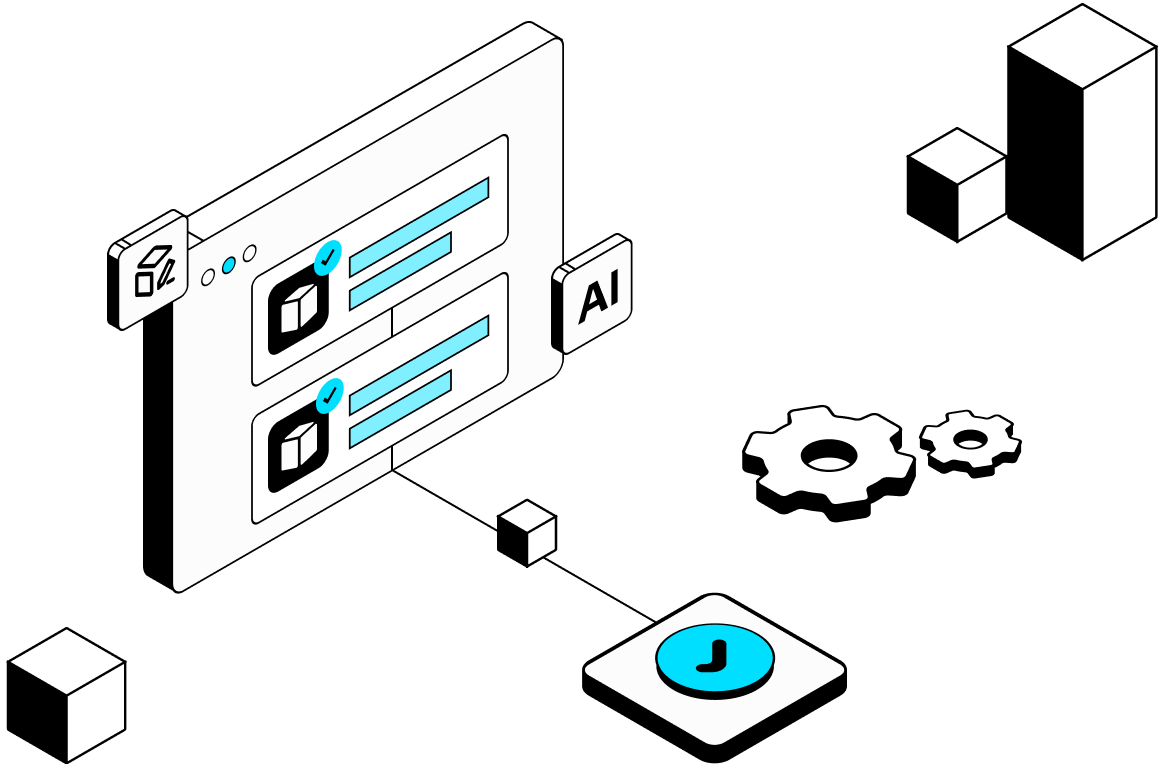
Reliable AI Workflow Tracking
Challenge
AI workflow failures are hard to diagnose without full visibility.
WhaleFlux enables you to:
Track fine-tuning tasks with real-time progress visibility.
Monitor model service health through key performance metrics.
Gain operational insights into AI agent execution and user interactions.
Ensure model quality through automated performance validation.
Intelligent Alert Management
Challenge
Alert fatigue leads to missed critical alerts.
WhaleFlux enables you to:
Receive notifications across your preferred channels.
Track incidents from detection to resolution in a closed loop.
Perform root cause analysis with centralized logging and diagnostics.
Eliminate alert noise and focus on actionable, critical incidents.

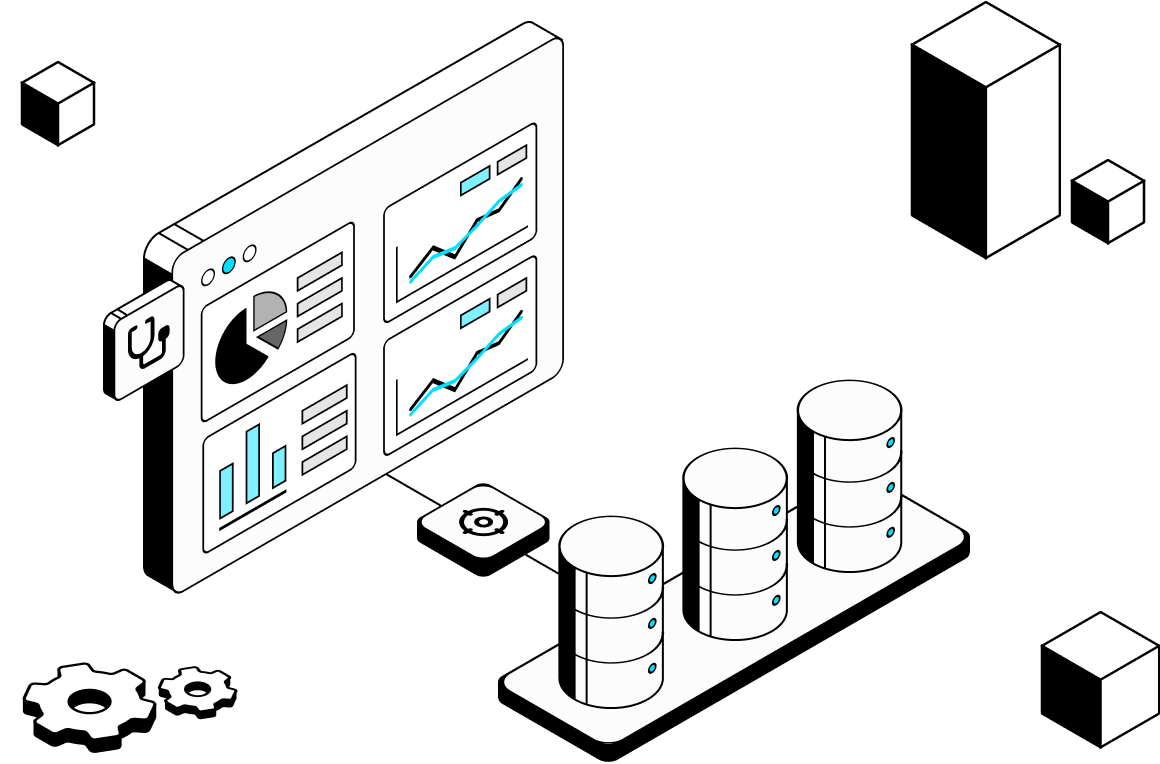
Unified Operations Dashboard
Challenge
Fragmented dashboards delay root cause analysis.
WhaleFlux enables you to:
Monitor your entire AI operation from a single, unified dashboard.
Identify root causes by correlating infrastructure and application data.
Create role-based dashboards tailored to different operational teams.
Accelerate troubleshooting with integrated metrics, logs, and traces.
Proactive Infrastructure Monitoring
Challenge
Discovering infrastructure issues only after your services go down?
With WhaleFlux, You Can:
Monitor cluster health and GPU utilization in real-time.
Visualize service relationships through dynamic topology mapping.
Set intelligent alerts based on 30+ performance metrics.
Prevent bottlenecks with predictive capacity planning.
Reliable AI Workflow Tracking
Challenge
When your AI workflow breaks, do you know which step failed?
With WhaleFlux, You Can:
Track fine-tuning tasks with real-time progress monitoring.
Monitor model service health through comprehensive performance metrics.
Gain insights into AI agent operations and user interactions.
Ensure model quality with automated performance validation.
Intelligent Alert Management
Challenge
Alert fatigue causing you to miss critical issues?
With WhaleFlux, You Can:
Receive smart notifications through your preferred channels.
Track issues from detection to resolution with a closed-loop system.
Analyze root causes with centralized logging and diagnostics.
Filter out noise and receive only actionable, critical alerts.
Unified Operations Dashboard
Challenge
Tired of juggling multiple screens and missing the root cause?
With WhaleFlux, You Can:
Monitor your entire AI operation from a single dashboard—no more switching tabs.
Pinpoint root causes quickly by correlating hardware and application data.
Build custom, role-based dashboards so every team can focus on what matters most.
Accelerate troubleshooting with integrated metrics, logs, and traces.
Core Technologies
Deep monitoring and comprehensive metrics form the intelligent core that delivers unmatched reliability and performance for your AI stack.

Real-time, thread-level observability for AI models and GPU clusters

30+ proprietary observability metrics

A closed-loop architecture for monitoring, alerting, and optimization
How Our Customers Use WhaleFlux
Key Results
90%
Reduction in MTTR
Automated Efficiency
Saving engineering teams hundreds of hours
99.9%
GPU utilization efficiency
The Challenge
AI Observability Across Industries
“Our AI-driven medical document pipeline occasionally stalled during peak hours, delaying critical report availability. WhaleFlux AI Observability provided real-time monitoring and alerts, enabling us to maintain continuous throughput and reduce report delays by 25%.”
“During peak shopping periods, our AI chat agents occasionally delayed responses or routed queries incorrectly due to high request volumes. WhaleFlux AI Observability provided real-time monitoring of agent performance and workflow health, enabling us to maintain fast, accurate support and reduce misrouted interactions by 28%.”
“Our AI-driven trading risk models were producing delayed alerts due to fragmented monitoring, which occasionally caused missed opportunities in high-frequency trading. WhaleFlux AI Observability centralized real-time performance metrics and provided proactive alerts, helping us reduce trading anomalies by 22% and ensure faster decision-making.”
GPU cluster workloads were frequently delayed or underutilized due to undetected performance bottlenecks, impacting SLAs. WhaleFlux AI Observability enabled thread-level monitoring, predictive alerts, and automated diagnostics, improving GPU utilization by 32% and maintaining near-zero downtime for critical services.”
“Our AI-driven supply chain agents were missing inventory and scheduling anomalies, causing delays in production planning. WhaleFlux AI Observability provided real-time alerts and diagnostics, helping us detect issues instantly, maintain smooth production flow, and reduce operational disruptions by 28%.”
Frequently Asked Questions
Everything you need to know about WhaleFlux AI Observability.
WhaleFlux is specifically designed for AI workloads. While traditional tools focus on infrastructure, we provide end-to-end visibility from GPU hardware to model fine-tuning and AI agent performance, all in one unified platform.
Yes! Our unified dashboard lets you track GPU utilization, node health, and model fine-tuning metrics side-by-side. You can see how infrastructure performance impacts your AI workflows in real-time.
Instantly. Our alert system triggers notifications within seconds of detecting anomalies. You can receive alerts via WeChat, email, SMS, or in-platform messages based on your preference.
No. WhaleFlux automatically detects and starts monitoring new fine-tuning jobs, quantization tasks, and deployed models. The system adapts to your workflow without manual configuration.
Absolutely. Customers typically achieve 90% faster problem identification thanks to our correlated monitoring that connects infrastructure issues to AI workflow impacts, plus instant multi-channel alerts.
We track agent-specific metrics including conversation volume, response latency, success rates, and resource consumption. This helps you optimize agent performance and scale resources proactively.
WhaleFlux integrates seamlessly with your existing Kubernetes environment while adding AI-specific monitoring capabilities. You get enhanced visibility without replacing your current tools.
We provide thread-level observability into GPU utilization, memory usage, temperature, and power consumption—plus how these metrics affect your model fine-tuning and inference performance.
Yes. Our system analyzes performance trends and can alert you to emerging patterns that typically lead to failures, allowing proactive intervention before problems impact your AI operations.
We offer scalable storage with customizable data retention periods to meet your compliance and analysis needs—from real-time monitoring to long-term trend analysis.