Step-by-Step: Build Your First AI-Powered Knowledge Base
Have you ever wished your company’s wealth of documents—manuals, reports, emails—could instantly answer any question? An AI-powered knowledge base makes this possible. It transforms static files into an interactive, intelligent resource that understands natural language queries and delivers precise, sourced answers.
This guide will walk you through creating your first AI knowledge base, a project that can drastically improve efficiency and decision-making. We will also explore how integrated platforms like WhaleFlux can streamline this entire process, offering a cohesive suite for AI computing, model management, agent creation, and observability.
Why Build an AI Knowledge Base?
Traditional knowledge management often means sifting through folders or using keyword searches that miss the context. An AI-powered knowledge base, often built with Retrieval-Augmented Generation (RAG) technology, solves this. It doesn’t just store information; it comprehends it. When an employee asks, “What’s the process for handling a client escalation?” the system finds the relevant sections from your policy documents and service manuals and generates a clear, consolidated answer. This capability is key to enhancing efficiency and supporting better decision-making.
Planning Your Knowledge Base: Key Considerations
Before diving in, a little planning ensures success.
Define the Scope and Goal:
Start small. Will this first version serve a specific team (e.g., IT support)? A particular project? A clear scope makes the project manageable.
Audit and Prepare Your Content:
Identify the core documents. These could be PDF manuals, Word docs, wiki pages, or even curated Q&A sheets. Clean, well-structured source material yields the best results.
Choose Your Approach:
You have two main paths
No-Code/Low-Code Platforms:
Tools like Dify or WhaleFlux allow you to build a knowledge base through a visual interface, often with drag-and-drop simplicity and no programming required. This is the fastest way to get started.
Hands-On Technical Build:
For maximum customization, you can assemble open-source tools like Ollama (to run models locally), a vector database, and a framework like LangChain. This offers great control but requires more technical expertise.
A Step-by-Step Implementation Guide
Here is a practical, step-by-step framework you can follow, adaptable to either a platform-based or a custom-built approach.
Step 1: Ingest and Process Your Documents
The first step is to get your content into the system. A good platform will support various formats like PDF, Word, Excel, and PowerPoint.
Action:
Upload your initial set of documents. For larger projects, organize files into logical folders or categories from the start.
Behind the Scenes:
The system will “chunk” the text—breaking down long documents into smaller, semantically meaningful pieces (e.g., by paragraph or section). This is crucial for accurate information retrieval later.
Step 2: Create Vector Embeddings and an Index
This is where the “AI magic” begins. The system converts each text chunk into a vector embedding—a numerical representation of its meaning.
Key Concept:
Think of embeddings as placing text on a map. Sentences with similar meanings are located close together. This allows the system to find content based on conceptual similarity, not just matching keywords.
Action:
The platform or your chosen embedding model (like BGE-M3) automatically handles this. The resulting vectors are stored in a specialized vector index for lightning-fast searches.
Step 3: Configure the RAG (Retrieval-Augmented Generation) Pipeline
Now, configure how queries are handled. This is the core of your AI knowledge base.
1.Retrieval:
When a user asks a question, the system converts it into a vector and searches the index for the most semantically relevant text chunks.
2.Augmentation:
These relevant chunks are pulled together as context.
3.Generation:
The system sends both the user’s question and this grounded context to a large language model (like GPT-4 or an open-source model). The instruction is: “Answer the question based only on the following context.” This forces the AI to base its answer on your provided knowledge, minimizing “hallucinations”.
Action:
In a platform like WhaleFlux, this pipeline is configured through intuitive settings, such as adjusting how many text chunks to retrieve or setting similarity score thresholds.
Step 4: Build a User Interface and Test
Your knowledge base needs a way for users to interact with it.
Action:
Most platforms offer a pre-built chat widget or a web application you can embed or share via a link. For a custom build, you would create a simple web interface.
Rigorous Testing:
Test with diverse queries. Start with simple factual questions, then move to complex, multi-part ones. Crucially, verify every answer against the source documents. Testing helps you fine-tune retrieval settings and prompt instructions.
Step 5: Deploy, Monitor, and Iterate
After testing, deploy the knowledge base to your pilot team.
Monitor Usage:
Pay attention to what users are asking and which answers are rated as helpful or unhelpful. As highlighted by industry leaders, the future of AI relies on learning from real-time interaction and feedback.
Iterate and Expand:
Use insights from monitoring to refine answers, add missing documentation, and gradually expand the scope of your knowledge base.
How WhaleFlux Simplifies the Entire Journey
Building an AI knowledge base involves coordinating multiple components: data processing, model selection, pipeline logic, and monitoring. WhaleFlux, as an all-in-one AI platform, is designed to integrate these capabilities seamlessly.
AI Computing & Model Management:
It provides the underlying compute power and a model hub, allowing you to select and switch between different state-of-the-art language models without managing complex infrastructure. This aligns with the “model factory” concept seen in advanced platforms, which helps in training, inference, and governance of models.
AI Agent Orchestration:
Beyond a simple Q&A bot, WhaleFlux likely enables the creation of sophisticated AI agents. Imagine an agent that doesn’t just answer a policy question but can also execute a related workflow, like generating a report based on that policy. This moves from simple retrieval to actionable intelligence.
AI Observability:
This is a critical differentiator. WhaleFlux probably offers tools to trace every user query—showing which documents were retrieved and how the final answer was generated. This transparency is essential for debugging, ensuring compliance, and continuously improving accuracy.
Conclusion
Building your first AI-powered knowledge base is an achievable and transformative project. By following a structured plan—starting with a clear goal, processing your documents, and implementing a RAG pipeline—you can unlock the latent value in your organization’s information. Platforms like WhaleFlux significantly lower the barrier to entry by consolidating the necessary tools into a unified, manageable environment. Start small, learn from use, and iterate. You’ll soon have a dynamic, intelligent system that enhances productivity and empowers everyone in your organization with instant access to collective knowledge.
FAQs: AI-Powered Knowledge Bases
1. What’s the difference between a traditional search and an AI knowledge base with RAG?
Traditional search relies on keyword matching. An AI knowledge base with RAG understands the semantic meaning of a question. It finds relevant information based on concepts and context, then uses a language model to synthesize a clear, natural language answer directly from your trusted sources.
2. Do I need technical expertise to build one?
Not necessarily. The rise of no-code/low-code AI platforms means business analysts or project managers can build powerful knowledge bases using visual interfaces. Technical expertise is required for highly customized, open-source implementations.
3. How do I ensure the AI gives accurate answers and doesn’t “hallucinate”?
The RAG architecture is the primary guardrail. By forcing the AI to base its answer only on retrieved documents from your knowledge base, you minimize fabrication. Additionally, features like answer sourcing (showing which document provided the information) and observability tools (to trace the AI’s decision path) are crucial for verification and trust.
4. Can I use my own company’s data securely?
Yes, data security is a top priority. Many enterprise-grade platforms offer private cloud or on-premises deployment options, ensuring your data never leaves your control. When evaluating platforms, inquire about their data encryption, access controls, and compliance certifications.
5. What are common use cases for an AI knowledge base in a business?
- 24/7 Intelligent Customer Support: Provide instant, accurate answers from product manuals and support guides.
- Onboarding & Employee Training: New hires can ask questions about company policies, software, and procedures.
- Expertise Preservation & Sharing: Capture the knowledge of subject matter experts and make it accessible to all teams.
- R&D and Competitive Intelligence: Quickly analyze large volumes of research papers, patents, and market reports.
3 AI Model Implementation Cases for SMEs: Empower Business Efficiently with Limited Budget
For small and medium-sized enterprises (SMEs), the world of artificial intelligence can often seem like an exclusive club reserved for tech giants with billion-dollar budgets. Headlines are dominated by massive, multi-million parameter models trained on sprawling data centers, creating the impression that AI is inherently complex, expensive, and out of reach.
This is a profound misconception. The true power of AI for business lies not in its scale, but in its precision and applicability. For SMEs, AI is not about building the next ChatGPT; it’s about solving a specific, high-impact business problem with a focused, efficient model. It’s about working smarter, automating tedious processes, and gaining insights from your existing data—all without needing a dedicated team of PhDs.
This guide presents three practical, budget-conscious AI implementation cases that SMEs can adopt. Each case follows a clear blueprint: identifying a common pain point, implementing a focused AI solution, and achieving tangible ROI. We’ll demystify the technical path and show how modern tools make this journey accessible.
Core Principles for SME AI Success
Before diving into the cases, two principles are fundamental:
Start with the Problem, Not the Technology:
Never ask “How can we use AI?” Instead, ask “What is our most costly, repetitive, or data-rich problem?” AI is the tool, not the goal.
Embrace the “Good Enough” Model:
SMEs win with efficiency. A simpler model that solves 80% of the problem today is infinitely more valuable than a perfect, complex model stuck in a year-long development cycle. Leverage pre-trained models and fine-tune them for your needs.
Case Study 1: The Intelligent Customer Service Automator
The Business Pain Point: A growing e-commerce SME is overwhelmed by customer service emails. Common queries about order status, return policies, and business hours consume hours of staff time daily, leading to slower response times, agent burnout, and potential customer dissatisfaction.
The AI Solution: A Hybrid Customer Service Triage & Drafting System
This isn’t about replacing humans with a brittle chatbot. It’s about augmenting your team with AI to handle the routine, so they can focus on the complex and empathetic conversations.
Step 1 – Automated Triage & Categorization:
An AI model (a fine-tuned lightweight text classifier like DistilBERT) automatically reads incoming emails and categorizes them: Order Status, Return Request, Product Question, Urgent Complaint. It can also extract key entities (order number, product name) and tag sentiment.
Step 2 – Smart Response Drafting:
For straightforward categories (Business Hours, Return Policy), the system can automatically generate a first-draft response by retrieving the correct information from a knowledge base and formatting it into a polite email. For Order Status, it can call a secure API to fetch the real-time tracking info and populate a response template.
Step 3 – Human-in-the-Loop:
Every AI-generated draft is presented to a human agent for a quick review, edit, and final approval before sending. This ensures quality, safety, and allows the agent to handle 3-4x more queries in the same time.
Why It Works for SMEs:
- Technology: Uses efficient, open-source models. No need to build complex chatbots from scratch.
- Data: Trained on your own historical email data, which you already have.
- ROI: Clear and fast. Measures: Reduction in average email handling time, increase in agent throughput, improvement in customer satisfaction (CSAT) scores due to faster replies.
Case Study 2: The Data-Driven Sales Lead Prioritizer
The Business Pain Point: A B2B service provider has a small sales team. Their CRM is full of hundreds of leads from websites, events, and campaigns, but they lack the bandwidth to contact everyone effectively. They waste time chasing cold leads while hot opportunities languish, resulting in inefficient sales cycles and missed revenue.
The AI Solution: A Lead Scoring & Prioritization Model
This system acts as a force multiplier for your sales team, directing their energy to the prospects most likely to convert.
Step 1 – Unify Data:
Consolidate lead data from your website forms, CRM (like HubSpot or Salesforce), marketing platform, and even LinkedIn Sales Navigator.
Step 2 – Build a Prediction Model:
Using historical data on which past leads became customers, train a simple machine learning classification model (e.g., XGBoost or Random Forest). The model learns patterns from features like:
- Firmographic: Company size, industry.
- Behavioral: Pages visited on your website, content downloaded, email engagement.
- Interaction: Number of touchpoints, recency of contact.
Step 3 – Generate Actionable Scores:
The model assigns each new lead a score from 1-100 predicting their likelihood to convert. It can also provide reasons (“scored highly due to repeated visits to pricing page and being in our target industry”).
Step 4 – Integrate & Act:
These scores and insights are pushed directly into your CRM. Your sales team now has a prioritized “hot list.” They can tailor their outreach—sending highly personalized, timely messages to high-score leads while automating nurturing sequences for lower-score ones.
Why It Works for SMEs:
- Technology: Uses robust, well-understood classical ML models that are less data-hungry than LLMs and highly interpretable.
- Data: Leverages the digital footprint you’re already collecting.
- ROI: Directly ties to revenue. Measures: Increase in lead-to-customer conversion rate, decrease in sales cycle length, higher win rates.
Case Study 3: The Automated Visual Quality Inspector
The Business Pain Point: A small manufacturer or artisan food producer relies on manual visual inspection for quality control. This process is slow, subjective, prone to fatigue, and inconsistent between shifts. Defects slip through, leading to product returns, waste, and brand damage.
The AI Solution: A Computer Vision (CV) Defect Detection System
This brings consistent, 24/7 “eyes” to your production line using a simple camera and a compact AI model.
Step 1 – Data Collection with a Twist:
You don’t need millions of images. Use a smartphone or a simple USB camera to capture a few hundred images of both “good” products and products with common defects (scratches, dents, discolorations, mislabeling). This small, curated dataset is your gold.
Step 2 – Train a Focused Model:
Use a user-friendly, cloud-based AutoML Vision tool (like Google’s or Roboflow). These platforms allow you to upload your images, label the defects with simple boxes, and automatically train a compact, efficient object detection model (like a small YOLO or MobileNet variant) within hours—no coding required.
Step 3 – Deploy at the Edge:
The trained model is tiny enough to run on an inexpensive edge device (like a NVIDIA Jetson Nano or even a Raspberry Pi with an accelerator) connected to the camera on your production line. It analyzes each product in real-time.
Step 4 – Automate Action:
The system is connected to a simple reject mechanism (a pneumatic arm, a diverter gate) or triggers an alert for a human operator when a defect is detected with high confidence.
Why It Works for SMEs:
- Technology: Leverages no-code/low-code AutoML platforms, eliminating the need for deep ML expertise.
- Data: Requires only a small, specific dataset you can create yourself.
- ROI: Highly tangible. Measures: Reduction in defect escape rate, decrease in product waste and returns, lower cost of quality inspection labor.
The Orchestration Challenge: From Idea to Integrated Solution
While each case uses accessible technology, the journey from a prototype script on a laptop to a reliable, integrated business system presents the real hurdle for an SME. This is the “last-mile” problem of AI: managing the data pipelines, versioning models, ensuring they run reliably, and connecting them to business applications.
This is precisely the gap that a unified AI platform like WhaleFlux is designed to fill for resource-constrained teams. WhaleFlux acts as the central nervous system for these AI implementations:
For the Customer Service Automator:
WhaleFlux can orchestrate the entire pipeline—ingesting emails, running the classification model, calling the knowledge base, and logging the draft and final response for continuous learning and monitoring, all within a governed workflow.
For the Lead Prioritizer:
It provides the tools to build, version, and deploy the scoring model as a live API that seamlessly integrates with the SME’s CRM, while monitoring its prediction drift as market conditions change.
For the Quality Inspector:
WhaleFlux can manage the lifecycle of the computer vision model, from receiving images from the edge device for periodic retraining to deploying updated models back to the production line, ensuring the system adapts to new defect types.
For an SME, WhaleFlux isn’t just a technical tool; it’s a force multiplier that reduces operational risk and complexity. It provides the infrastructure, monitoring, and integration glue that allows a small team to manage multiple AI solutions with the confidence of a much larger tech department, ensuring their AI investments are robust, scalable, and maintainable.
Conclusion: Your AI Journey Starts Now
The barrier to entry for practical, valuable AI has never been lower. SMEs have unique advantages: agility, focused data, and clear, impactful problems. By starting small with a well-defined use case—whether it’s automating service, prioritizing sales, or ensuring quality—you can build expertise, demonstrate ROI, and create a foundation for increasingly sophisticated AI adoption.
The question is no longer “Can we afford AI?” but “Can we afford to keep doing this manually?”Identify your pain point, follow the blueprint, leverage modern platforms to manage the complexity, and start empowering your business efficiently.
FAQs: AI Implementation for SMEs
Q1: We have very little data. Can we still implement AI?
Yes, absolutely. The key is to start with a focused problem. For many tasks, you need far less data than you think, especially if you use pre-trained models and fine-tune them. A few hundred well-labeled examples are often sufficient for a significant performance boost. Case Study 3 (Quality Inspection) is a perfect example of a small-data start.
Q2: What does the initial investment look like? Do we need to hire AI experts?
The initial investment is primarily time, not capital. You need dedicated personnel (often a technically-minded manager or an existing IT staffer) to own the project. You do not need to hire a dedicated AI scientist. Instead, leverage:
- Cloud-based AutoML services (for vision, tabular data).
- Fine-tuning of open-source models using guided platforms.
- Consultants or agencies for the initial setup, with a plan for internal knowledge transfer. The software and compute costs for a pilot are typically in the hundreds, not tens of thousands, of dollars.
Q3: How do we measure the ROI of an AI project?
Tie ROI directly to the business metric you are trying to improve, and measure it before and afterimplementation. Examples:
- Customer Service: Cost per resolved ticket, average handle time, customer satisfaction score.
- Sales: Lead-to-opportunity conversion rate, sales cycle length, average deal size from scored leads.
- Quality Control: Defect escape rate, cost of waste/returns, inspection throughput.
Start with a pilot on a subset of your operations to gather this comparison data.
Q4: Aren’t these AI systems “black boxes”? How do we trust them?
This is a valid concern. The solutions recommended prioritize interpretability.
- Lead Scoring: Models like XGBoost can show which factors contributed to a score.
- Classifiers: Can show which keywords influenced a decision.
- Human-in-the-Loop: Always keep a human reviewing critical AI outputs (like email drafts). Trust is built through transparency and control, not magic. Start with low-risk applications to build confidence.
Q5: What’s the biggest risk, and how do we mitigate it?
The biggest risk is project stagnation—an endless pilot that never integrates into daily operations. Mitigate this by:
- Setting a strict 3-month timeline for a pilot with clear success/failure criteria.
- Involving the end-users (agents, sales reps, line workers) from day one.
- Choosing a first project that solves a pain point they feel intensely. Adoption by the team is the ultimate measure of success, not just technical accuracy.
A Complete Guide to AI Model Fine-Tuning: LoRA, QLoRA, and Full-Parameter Fine-Tuning
Imagine you’ve just hired a brilliant polymath who has read nearly every book ever written. They can discuss history, science, and art with astonishing depth. However, on their first day at your specialized law firm, you ask them to draft a precise legal clause. They might struggle. Their vast general knowledge needs to be focused and adapted to the specific language, patterns, and rules of your domain.
This is the exact challenge with powerful, pre-trained Large Language Models (LLMs) like Llama 2 or GPT-3. They are incredible generalists, but to become reliable, high-performing specialists for your unique tasks—be it legal analysis, medical note generation, or brand-specific customer service—they require fine-tuning.
Fine-tuning is the process of continuing the training of a pre-trained model on a smaller, domain-specific dataset. But how you fine-tune has evolved dramatically, leading to critical choices. This guide will demystify the three primary paradigms: Full-Parameter Fine-Tuning, LoRA, and QLoRA, helping you understand their trade-offs and select the right tool for your project.
The Core Goal of Fine-Tuning: From Generalist to Specialist
At its heart, fine-tuning aims to achieve one or more of the following:
- Domain Mastery: Teaching the model the jargon, style, and knowledge of a specific field (e.g., biomedicine, legal code, internal company documentation).
- ️Task Specialization: Optimizing the model for a particular format or function (e.g., following complex instructions, outputting strict JSON, engaging in a specific chat persona).
- Performance Alignment: Improving the model’s reliability, accuracy, and safety on a narrow set of critical tasks.
The evolution of fine-tuning methods is a story of the relentless pursuit of efficiency—achieving these goals while minimizing computational cost, time, and hardware barriers.
Method 1: Full-Parameter Fine-Tuning – The Traditional Powerhouse
This is the original and most straightforward approach. You take the pre-trained model, load it onto powerful GPUs, and run additional training passes on your custom dataset, updating every single parameter (weight) in the neural network.
How it Works:
It’s a continuation of the initial training process, but on a much smaller, targeted dataset. The optimizer adjusts all billions of parameters to minimize loss on your new data.
Use Cases:
- When you have a very large, high-quality domain-specific dataset (millions of examples).
- When the target task differs significantly from the model’s pre-training, requiring fundamental rewiring.
- For creating a definitive, standalone model variant meant for widespread distribution and heavy use (e.g., a code-specific version of a base model).
Trade-offs:
- Pros: Maximum potential performance and flexibility; the model can deeply internalize new patterns.
- Cons: Extremely expensive in terms of GPU memory and time; high risk of catastrophic forgetting (losing general knowledge); requires multiple high-end GPUs (often 4-8 A100s).
Analogy: Sending the polymath back to a full, multi-year university program focused solely on law. Effective but immensely resource-intensive.
Method 2: LoRA (Low-Rank Adaptation) – The Efficiency Revolution
Introduced by Microsoft in 2021, LoRA is a Parameter-Efficient Fine-Tuning (PEFT) method that has become the de facto standard for most practical applications. Its core insight is brilliant: the weight updates a model needs for a new task have a low “intrinsic rank” and can be represented by much smaller matrices.
How It Works
Instead of updating the massive pre-trained weight matrices (e.g., of size 4096×4096), LoRA injects trainable “adapter” layers alongside them. During training, only these tiny adapter matrices (e.g., of size 4096×8 and 8×4096) are updated. The original weights are frozen. For inference, the adapter weights are merged with the frozen base weights.
Use Cases:
- The vast majority of business applications where you need to adapt a model to a specific style, task, or knowledge base.
- Situations with limited data (hundreds to thousands of examples).
- When you need to create multiple specialized versions of a model (e.g., one for summarization, one for Q&A) efficiently, as adapters are small (~1-10% of original model size) and easily swapped.
Trade-offs:
- Pros: Dramatically lower GPU memory usage (enabling fine-tuning of large models on a single GPU), faster training, reduced overfitting risk, and no catastrophic forgetting. Adapters are portable and shareable.
- Cons: Can, in some edge cases, theoretically underperform full fine-tuning given unlimited data and compute. Requires selecting target modules (often attention layers) and rank parameters.
Analogy:
Giving the polymath a concise, targeted legal handbook and a set of specialized quick-reference guides. They keep all their general knowledge but learn to apply it within a new, structured framework.
Method 3: QLoRA (Quantized LoRA) – Democratizing Access
QLoRA, introduced in 2023, pushes the efficiency frontier further. It asks: “What if we could fine-tune a massive model on a single, consumer-grade GPU?” The answer combines LoRA with another key technique: 4-bit Quantization.
How it Works:
First, the pre-trained model is loaded into GPU memory in a 4-bit quantized state (compared to standard 16-bit). This drastically reduces its memory footprint. Then, LoRA adapters are applied and trained in 16-bit precision. A novel “Double Quantization” technique is used to minimize the memory overhead of the quantization constants themselves. Remarkably, the model’s performance is maintained through backpropagation via the 4-bit weights.
Use Cases:
- Research, prototyping, and personal projects with severe hardware constraints.
- Fine-tuning the largest available models (e.g., 70B parameter models) on a single 24GB or 48GB GPU.
- When cost and accessibility are the primary limiting factors.
Trade-offs:
- Pros: Makes previously impossible fine-tuning tasks possible on affordable hardware. Retains the core benefits of LoRA.
- Cons: The quantization process adds slight complexity. There can be a marginal, though often negligible, performance trade-off compared to 16-bit LoRA. Requires libraries that support 4-bit quantization (like
bitsandbytes).
Analogy:
The polymath’s entire library is now stored on a highly efficient, compressed e-reader. They still get the complete legal handbook and quick guides, allowing them to specialize using minimal physical desk space.
Navigating the Trade-offs: A Decision Framework
How do you choose? Follow this decision tree based on your primary constraints:
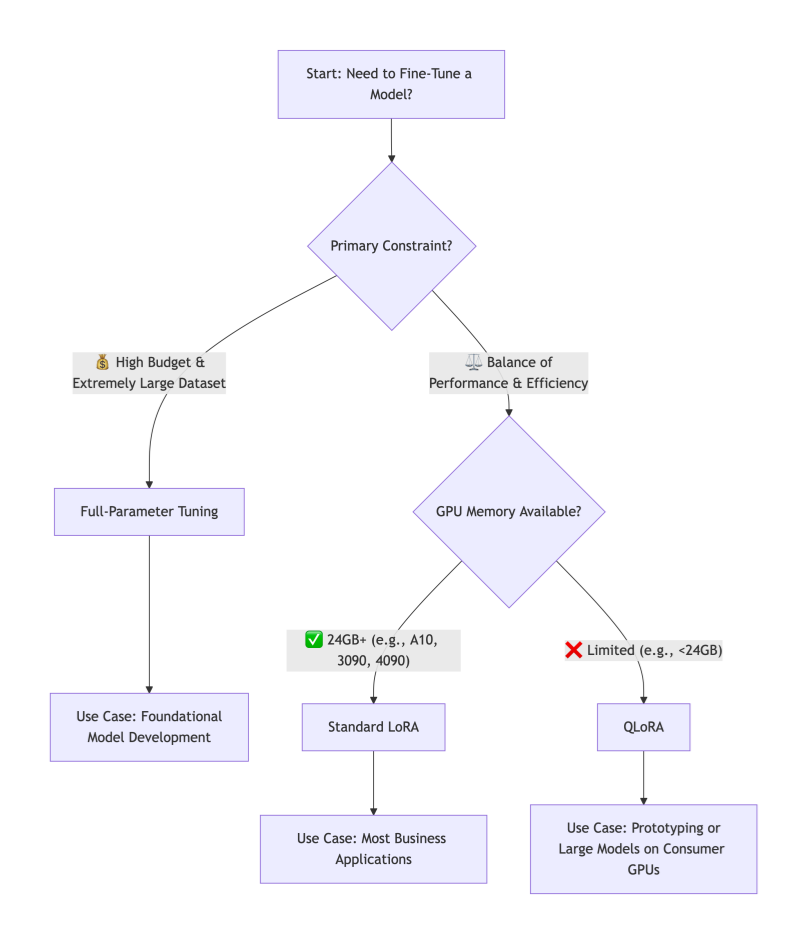
The Verdict:
For over 90% of business, research, and personal applications, LoRA is the recommended starting point. It offers the best balance of performance, efficiency, and practicality. QLoRA is the key when hardware is the absolute bottleneck. Reserve Full-Parameter Fine-Tuning for major initiatives where you are essentially creating a new foundational model and have the corresponding resources.
Taming Complexity: The Need for an Orchestration Platform
While LoRA and QLoRA lower hardware barriers, they introduce new operational complexities: managing different base models, dozens of adapter files, experiment tracking across various ranks and learning rates, and deploying these composite models.
This is where an integrated AI platform like WhaleFlux becomes a strategic force multiplier. WhaleFlux is designed to tame the fine-tuning lifecycle:
Streamlined Experimentation:
It provides a centralized environment to launch, track, and compare hundreds of fine-tuning jobs—whether full-parameter, LoRA, or QLoRA—logging all hyperparameters, metrics, and resulting artifacts.
Adopter & Model Registry:
Instead of a folder full of cryptic .bin files, WhaleFlux acts as a versioned registry for both your base models and your trained adapters. You can easily browse, compare, and promote the best-performing adapters.
Simplified Deployment:
Deploying a LoRA-tuned model is as simple as selecting a base model and an adapter from the registry. WhaleFlux handles the seamless merging and deployment of the optimized model to a scalable inference endpoint, abstracting away the underlying infrastructure complexity.
With WhaleFlux, teams can focus on the art of crafting the perfect dataset and experiment strategy, while the science of orchestration, reproducibility, and scaling is handled reliably.
Conclusion
The fine-tuning landscape has been transformed by LoRA and QLoRA, shifting the question from “Can we afford to fine-tune?” to “How should we fine-tune most effectively?” By understanding the trade-offs between full-parameter tuning, LoRA, and QLoRA, you can align your technical approach with your project’s goals, data, and constraints.
Start with a clear objective, embrace the efficiency of modern PEFT methods, and leverage platforms that operationalize these advanced techniques. This allows you to turn a powerful general-purpose AI into a dedicated, domain-specific expert that delivers tangible value.
FAQs: AI Model Fine-Tuning
1. When should I not use fine-tuning?
Fine-tuning is most valuable when you have a repetitive, well-defined task and a curated dataset. For tasks requiring real-time, external knowledge (e.g., answering questions about recent events), Retrieval-Augmented Generation (RAG) is often better. For simple task guidance, prompt engineering may suffice. The best solutions often combine RAG (for knowledge) with a lightly fine-tuned model (for style and task structure).
2. How much data do I need for LoRA/QLoRA to be effective?
You need significantly less data than for full-parameter tuning. For many style or instruction-following tasks, a few hundred high-quality examples can yield remarkable improvements. For complex domain adaptation, 1,000-10,000 examples are common. The key is data quality and diversity—they must be representative of the task you want the model to master.
3. What are the “rank” and “alpha” parameters in LoRA, and how do I set them?
- Rank (
r): This is the critical dimension of the low-rank adapter matrices. A higher rank means a larger, more expressive adapter (but more parameters to train). Start with a low rank (e.g., 8, 16, 32) and increase only if performance is lacking. - Alpha (
α): This is a scaling parameter for the adapter weights. Think of it as the learning rate for the adapter’s influence. A common and often effective rule of thumb is to setalpha = 2 * rank. Empirical testing on a validation set is the best way to tune these.
4. Can I combine multiple LoRA adapters on one base model?
Yes, this is a powerful advanced technique sometimes called “Adapter Fusion” or “Mixture of Adapters.” You can train separate adapters for different skills (e.g., one for coding syntax, one for medical terminology) and, with the right framework, dynamically combine or select them at inference time. This pushes the model towards being a modular, multi-skilled expert.
5. Does QLoRA sacrifice model quality compared to standard LoRA?
The research (Dettmers et al., 2023) showed that QLoRA, when properly configured, recovers the full 16-bit performance of standard fine-tuning. In practice, any performance difference is often negligible and far outweighed by the accessibility gains. For mission-critical deployments, you can train with QLoRA and then merge the high-quality adapters back into a 16-bit base model for inference if desired.
Guide to AI Model End-to-End Lifecycle Cost Optimization
For many businesses, the initial excitement of building a powerful AI model is quickly tempered by a daunting reality: the astronomical and often unpredictable costs that accrue across its entire lifecycle. It’s not just the headline-grabbing expense of training a large model; it’s the cumulative burden of data preparation, experimentation, deployment infrastructure, and ongoing inference that can cripple an AI initiative’s ROI.
The good news is that strategic cost optimization is not about indiscriminate cutting. It’s about making intelligent, informed decisions at every stage—from initial idea to production scaling. By adopting a holistic, end-to-end perspective, it is entirely feasible to reduce your total cost of ownership (TCO) by 50% or more, while maintaining or even improving model performance and reliability.
This guide provides a practical, stage-by-stage blueprint to achieve this goal, transforming your AI projects from budget black holes into efficient, value-generating assets.
Stage 1: The Foundation – Cost-Aware Design and Data Strategy (15-30% Savings)
Long before a single line of training code runs, you make decisions that lock in most of your future costs.
Optimization 1: Right-Scope the Problem.
The most expensive model is the one you didn’t need to build. Rigorously ask: Can a simpler rule-based system, a heuristic, or a fine-tuned small model solve 80% of the problem at 20% of the cost? Starting with the smallest viable model (e.g., a logistic regression or a lightweight BERT variant) establishes a cost-effective baseline.
Optimization 2: Invest in Data Quality, Not Just Quantity.
Garbage in, gospel out—and training on “garbage” is incredibly wasteful. Data cleaning, deduplication, and smart labeling directly reduce the number of training epochs needed for convergence. Implementing active learning, where the model selects the most informative data points for labeling, can cut data acquisition and preparation costs by up to 70%.
Optimization 3: Architect for Efficiency.
Choose model architectures known for efficiency from the start (e.g., EfficientNet for vision, DistilBERT for NLP). Design feature engineering pipelines that are lightweight and reusable. This upfront thinking prevents costly refactoring later.
Stage 2: The Experimental Phase – Efficient Model Development (20-40% Savings)
This is where compute costs can spiral due to unmanaged experimentation.
Optimization 4: Master the Art of Experiment Tracking.
Undisciplined experimentation is a primary cost driver. By systematically logging every training run—hyperparameters, code version, data version, and results—you avoid repeating failed experiments. This alone can cut wasted compute by 30%. Identifying underperforming runs early and stopping them (early stopping) is a direct cost saver.
Optimization 5: Leverage Transfer Learning and Efficient Fine-Tuning.
Never train a large model from scratch if you can avoid it. Start with a high-quality pre-trained model and use Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA. These techniques fine-tune only a tiny fraction (often <1%) of the model’s parameters, slashing training time, GPU memory needs, and cost by over 90% compared to full fine-tuning.
Optimization 6: Optimize Hyperparameter Tuning.
Grid searches over large parameter spaces are prohibitively expensive. Use Bayesian Optimization or Hyperband to intelligently explore the hyperparameter space, finding optimal configurations in a fraction of the time and compute.
Stage 3: The Deployment Leap – Optimizing for Production Scale (25-50% Savings)
This is where ongoing operational costs are determined. Inefficiency here compounds daily.
Optimization 7: Apply Model Compression.
Before deployment, subject your model to a compression pipeline: Prune it to remove unnecessary weights, Quantize it from 32-bit to 8-bit precision (giving a 4x size reduction and 2-4x speedup), and consider Knowledge Distillation to create a compact “student” model. A compressed model directly translates to lower memory requirements, faster inference (lower latency), and significantly cheaper compute instances.
Optimization 8: Implement Intelligent Serving and Autoscaling.
Do not over-provision static resources. Use Kubernetes-based serving with horizontal pod autoscaling to match resources precisely to incoming traffic. For batch inference, use spot/preemptible instances at a fraction of the on-demand cost. Choose the right hardware: an efficient CPU for simple models, a GPU for heavy parallel workloads, or an AI accelerator (like AWS Inferentia) for optimal cost-per-inference.
Optimization 9: Design a Cost-Effective Inference Pipeline.
Cache frequent prediction results. Use model cascades, where a cheap, fast model handles easy cases, and only the difficult ones are passed to a larger, more expensive model. This dramatically reduces calls to your most costly resource.
Stage 4: The Long Run – Proactive Monitoring and Maintenance (10-25% Savings)
Post-deployment complacency erodes savings through silent waste.
Optimization 10: Proactively Monitor for Drift and Decay.
A model degrading in performance is a cost center—it delivers less value while consuming the same resources. Implement automated monitoring for data drift and concept drift. Detecting decay early allows for targeted retraining, preventing a full-blown performance crisis and the frantic, expensive firefight that follows.
Optimization 11: Establish a Retraining ROI Framework.
Not all drift warrants an immediate, full retrain. Establish metrics to calculate the Return on Investment (ROI) of retraining. Has performance decayed enough to impact business KPIs? Is there enough new, high-quality data? Automating this decision prevents unnecessary retraining cycles and their associated costs.
The Orchestration Imperative: How WhaleFlux Unlocks Holistic Optimization
Attempting to implement these 11 optimizations with a patchwork of disjointed tools creates its own management overhead and cost. True end-to-end optimization requires a unified platform that orchestrates the entire lifecycle with cost as a first-class metric.
WhaleFlux is engineered to be this orchestration layer, explicitly designed to turn the strategies above into executable, automated workflows:
Unified Cost Visibility:
It provides a single pane of glass for tracking compute spend across experimentation, training, and inference, attributing costs to specific projects and models—solving the “cost black box.”
Automated Efficiency:
WhaleFlux automates experiment tracking (Optimization 4), can orchestrate PEFT training jobs (5), and manages model serving with autoscaling on cost-optimal hardware (8).
Governed Lifecycle:
Its model registry and pipelines ensure that compressed, optimized models (7) are promoted to production, and its integrated monitoring (10) can trigger cost-aware retraining pipelines (11).
By centralizing control and providing the tools for efficiency at every stage, WhaleFlux doesn’t just run models—it systematically reduces the cost of owning them, turning the 50% savings goal from an aspiration into a measurable outcome.
Conclusion
Slashing AI costs by 50% is not a fantasy; it’s a predictable result of applying disciplined engineering and financial principles across the model lifecycle. It requires shifting from a narrow focus on training accuracy to a broad mandate of operational excellence. From the data you collect to the hardware you deploy on, every decision is a cost decision.
By adopting this end-to-end optimization mindset and leveraging platforms that embed these principles, you transform AI from a capital-intensive research project into a scalable, sustainable, and financially predictable engine of business growth. The savings you unlock aren’t just cut costs—they are capital freed to invest in the next great innovation.
FAQs: AI Model Lifecycle Cost Optimization
Q1: Where is the single biggest source of waste in the AI lifecycle?
Unmanaged and untracked experimentation. Teams often spend thousands of dollars on GPU compute running redundant or poorly documented training jobs. Implementing rigorous experiment tracking with early stopping capabilities typically offers the fastest and largest return on investment for cost reduction.
Q2: Is cloud or on-premise infrastructure cheaper for AI?
There’s no universal answer; it depends on scale and predictability. Cloud offers flexibility and lower upfront cost, ideal for variable workloads and experimentation. On-premise (or dedicated co-location) can become cheaper at very large, predictable scales where the capital expenditure is amortized over time. The hybrid approach—using cloud for bursty experimentation and on-premise for steady-state inference—is often optimal.
Q3: How do I calculate the ROI of model compression (pruning/quantization)?
The ROI is a combination of hard and soft savings: (Reduced_Instance_Cost * Time) + (Performance_Improvement_Value). Hard savings come from downsizing your serving instance (e.g., from a $4/hr GPU to a $1/hr CPU). Soft savings come from reduced latency (improving user experience) and lower energy consumption. The compression process itself has a one-time cost, but the savings recur for the lifetime of the deployed model.
Q4: We have a small team. Can we realistically implement all this?
Yes, by leveraging the right platform. The complexity of managing separate tools for experiments, training, deployment, and monitoring is what overwhelms small teams. An integrated platform like WhaleFlux consolidates these capabilities, allowing a small team to execute like a large one by automating best practices and providing a single workflow from idea to production.
Q5: How often should we review and optimize costs?
Cost review should be continuous and automated. Set up monthly budget alerts and dashboard reviews. More importantly, key optimization decisions (like selecting an instance type or triggering a retrain) should be informed by cost metrics in real-time. Make cost a first-class KPI alongside accuracy and latency in every phase of your ML operations.
10 Common Pitfalls Beginners Face with AI Models: A Guide to Avoiding Ineffective Training and Deployment Lag
Pitfall 1: Starting Without a Well-Defined Problem & Success Metric
The Trap:
Jumping straight into data collection or model selection because “AI is cool for this.” Vague goals like “improve customer experience” or “predict something useful” set the project up for failure, as there’s no clear finish line.
The Solution:
Begin by rigorously framing your problem. Is it a classification, regression, or clustering task? Crucially, define a quantifiable, business-aligned success metric before you start. Instead of “predict sales,” aim for “build a model that predicts next-month sales for each store within a mean absolute error (MAE) of $5,000.” This metric will guide every subsequent decision.
Pitfall 2: Underestimating the Paramount Importance of Data Quality
The Trap:
Assuming that more data automatically means a better model, and spending all effort on complex algorithms while feeding them noisy, inconsistent, or biased data. Garbage in, gospel out.
The Solution:
Allocate the majority of your initial time (often 60-80%) to data understanding, cleaning, and preprocessing. This involves:
- Handling missing values and outliers.
- Ensuring consistent formatting and labeling.
- Conducting exploratory data analysis (EDA) to uncover biases or spurious correlations.
- Documenting your data’s origins and limitations. A simple model trained on impeccable data will consistently outperform a brilliant model trained on a mess.
Pitfall 3: Data Leakage – The Silent Model Killer
The Trap:
Accidentally allowing information from the training process to “leak” into the training data. This creates a model that performs spectacularly well in testing but fails catastrophically in the real world. Common causes include: preprocessing (e.g., normalization) on the entire dataset before splitting, or using future data to predict past events.
The Solution:
Implement a strict, chronologically-aware data pipeline. Always split your data into training, validation, and test sets first (respecting time order if relevant). Then, fit any preprocessing steps (scalers, encoders) only on the training set, and apply the fitted transformer to the validation/test sets. This mimics the real-world flow of seeing new, unseen data.
Pitfall 4: Overfitting to the Training Set
The Trap:
Creating a model that memorizes the noise and specific examples in the training data rather than learning the generalizable pattern. It achieves near-perfect training accuracy but performs poorly on new data.
The Solution:
Employ a combination of techniques:
- Use a validation set: Hold out a portion of your training data to evaluate performance during development.
- Apply regularization: Techniques like L1/L2 regularization (which penalizes overly complex models) or Dropout (for neural networks) explicitly discourage overfitting.
- Practice simplicity: Start with a simpler model (linear regression before a deep neural network). You can only justify complexity if simplicity fails on your validation set.
- Get more data: This is often the most effective regularizer.
Pitfall 5: Misinterpreting Model Performance
The Trap:
Relying solely on overall accuracy, especially for imbalanced datasets. For example, a model that simply predicts “no fraud” for every transaction will have 99.9% accuracy in a dataset where fraud is 0.1% prevalent, yet it’s utterly useless.
The Solution:
Choose metrics that reflect your business reality. For imbalanced classification, use precision, recall, F1-score, or the area under the ROC curve (AUC-ROC). Always examine a confusion matrix to see where errors are actually occurring. The right metric is determined by the cost of false positives vs. false negatives in your specific application.
Pitfall 6: The “Set-and-Forget” Training Mindset
The Trap:
Running one training job, hitting a decent metric, and calling the model “done.” Machine learning is inherently experimental.
The Solution:
Adopt a methodical experimentation mindset. Systematically vary hyperparameters (learning rate, model architecture, feature sets) and track every experiment. Use tools—or a platform—to log the hyperparameters, code version, data version, and resulting metrics for every run. This turns model development from a black art into a reproducible, optimizable process.
Pitfall 7: Ignoring the Engineering Path to Production
The Trap:
Building a model in a Jupyter notebook and only then asking, “How do we put this online?” This leads to deployment lag, as the code, dependencies, and environment are not built for scalable, reliable serving.
The Solution:
Think about deployment from day one. Write modular, production-ready code even during exploration. Containerize your model and its environment using Docker. Plan for how the model will receive inputs and deliver outputs (a REST API is common). This “production-first” thinking smooths the transition from prototype to product.
Pitfall 8: Assuming the Model Will Stay Accurate Forever
The Trap:
Deploying a model and considering the project complete. In a dynamic world, model performance decays over time due to data drift (changes in input data distribution) and concept drift (changes in the relationship between inputs and outputs).
The Solution:
Implement a model monitoring plan before launch. Define key performance indicators (KPIs) and set up automated tracking of prediction accuracy, input data distributions, and business outcomes. Establish alerts to trigger when these metrics deviate from expected baselines, signaling the need for model retraining or investigation.
Pitfall 9: Neglecting Computational and Cost Realities
The Trap:
Designing a massive neural network without considering the GPU hours required to train it or the latency and cost of serving thousands of predictions per second.
The Solution:
Profile your model’s needs early. Start small and scale up only if necessary. Explore model optimization techniques like quantization and pruning to reduce size and speed up inference. Always calculate the rough total cost of ownership (TCO), factoring in training compute, inference compute, and engineering maintenance.
Pitfall 10: Working in Isolation Without Version Control
The Trap:
Keeping code, data, and model weights in ad-hoc folders with names like final_model_v3_best_try2.pkl. This guarantees irreproducibility and collaboration nightmares.
The Solution:
Use Git religiously for code. Extend that discipline to data and models. Use data versioning tools (like DVC) and a model registry to track exactly which version of the code trained which version of the model on which version of the data. This is non-negotiable for professional, collaborative ML work.
How an Integrated Platform Bridges the Gap
For beginners, managing these ten areas—experiment tracking, data pipelines, deployment engineering, and monitoring—can feel overwhelming. This is where an integrated MLOps platform like WhaleFlux transforms the learning curve.
WhaleFlux is designed to institutionalize best practices and help beginners avoid these exact pitfalls:
- It structures experimentation (solving Pitfall 6), automatically logging every run to eliminate confusion.
- Its model registry provides governance and version control (solving Pitfall 10), creating a single source of truth.
- It streamlines the packaging and deployment of models as APIs (solving Pitfall 7), turning weeks of DevOps work into a few clicks.
- Its built-in monitoring dashboards track model health and data drift in production (solving Pitfall 8), giving you peace of mind.
In essence, WhaleFlux provides the guardrails and automation that allow beginners to focus on the core science and application of ML, rather than the sprawling peripheral engineering challenges that so often cause projects to stall or fail.
Conclusion
Mastering AI is as much about avoiding fundamental mistakes as it is about implementing advanced techniques. By being aware of these ten common pitfalls—from problem definition to production monitoring—you position your project for success from the outset. Remember, effective AI is built on a foundation of meticulous data management, rigorous experimentation, and a steadfast focus on the end goal of creating a reliable, maintainable asset that delivers real-world value. Start with these principles, leverage modern platforms to automate the complexity, and you’ll not only build better models, but deploy them faster and with greater confidence.
FAQs: Common Beginner Pitfalls with AI Models
1. What is the single most important step for a beginner to get right?
Without a doubt, it’s Pitfall #2: Data Quality and Understanding. Investing disproportionate time in cleaning, exploring, and truly understanding your data pays greater dividends than any model choice or hyperparameter tune. A clean, well-understood dataset makes all subsequent steps smoother and more likely to succeed.
2. How can I practically check for data leakage (Pitfall #3)?
A strong, practical red flag is a massive discrepancy between performance on your validation set and performance on a truly held-out test set. If your model’s accuracy drops dramatically (e.g., from 95% to 70%) when evaluated on the final test data you locked away at the very start, you almost certainly have data leakage. Review your preprocessing pipeline step-by-step to ensure the test set was never used to calculate statistics like means, medians, or vocabulary lists.
3. I have a highly imbalanced dataset. What metric should I use instead of accuracy?
Stop using accuracy. Instead, focus on Recall (Sensitivity) if missing the positive class is very costly (e.g., failing to detect a serious disease). Focus on Precision if false alarms are very costly (e.g., incorrectly flagging a legitimate transaction as fraud). To balance both, use the F1-Score. Always examine the Confusion Matrix to see the exact breakdown of your errors.
4. As a beginner, how do I know when to stop trying to improve my model?
Establish a performance benchmark early. This could be a simple heuristic or a basic model (like logistic regression). Your goal is to outperform this benchmark meaningfully. Stop when: 1) You consistently meet your pre-defined business metric on the validation set, 2) Further hyperparameter tuning or feature engineering yields diminishing returns (very small improvements for large effort), or 3) You hit the constraints of your data quality or volume. Don’t optimize indefinitely.
5. Do I really need to worry about monitoring and retraining (Pitfall #8) for a simple model?
Yes, absolutely. Even simple models are subject to the changing world. The frequency may be lower, but the need is the same. At a minimum, schedule a quarterly review where you check the model’s predictions against recent outcomes. Setting up a simple automated alert for a significant drop in an online metric (like conversion rate) that your model influences is a highly recommended best practice for any model in production.
Beyond ChatGPT: 6 Niche but Practical Industry Use Cases of AI Models
The meteoric rise of ChatGPT brought Large Language Models (LLMs) into the public spotlight, showcasing their remarkable ability to converse, create, and reason with text. However, this public-facing “chatbot” persona is just the tip of the AI iceberg. Beneath the surface, a quiet revolution is underway: specialized AI models are being deployed to solve deep, complex, and highly valuable problems in specific industries.
These niche applications often don’t make headlines, but they are transforming operations, driving innovation, and creating significant competitive advantages. They move beyond general conversation to perform precision tasks—analyzing molecular structures, interpreting sensor vibrations, or forecasting microscopic crop diseases. This article explores six such practical use cases where AI models are doing the heavy lifting far beyond the chat window.
1. AI in Healthcare: Accelerating Drug Discovery and Development
The traditional drug discovery pipeline is notoriously slow and expensive, often taking over a decade and billions of dollars to bring a new therapy to market. AI models are compressing this timeline by orders of magnitude.
The Application:
Researchers use specialized AI for virtual screening of compound libraries. Models trained on vast datasets of molecular structures and biological interactions can predict how a new molecule will behave in the body, identifying the most promising candidates for treating a specific disease. Another critical application is in optimizing clinical trial design. AI can analyze historical trial data to identify suitable patient cohorts, predict potential side effects, and even suggest optimal dosing regimens.
Why It’s Niche & Powerful:
This isn’t about answering patient questions; it’s about leveraging graph neural networks (GNNs) and generative models to navigate a complex, multi-dimensional scientific space. It reduces the initial “needle-in-a-haystack” search from millions of compounds to a manageable shortlist, saving years of lab work and immense resources.
2. AI in Precision Manufacturing: Predictive Maintenance and Quality Control
In a high-stakes factory environment, an unplanned machine failure can cost millions. Similarly, a single defective component can ruin an entire production batch.
The Application:
Predictive maintenance models analyze real-time sensor data (vibration, temperature, acoustic signals) from industrial equipment. By learning the “normal” operating signature, these models can detect subtle anomalies that precede a failure, allowing maintenance to be scheduled proactively. For automated visual inspection, high-resolution computer vision models surpass human ability to spot microscopic cracks, coating defects, or assembly errors on fast-moving production lines, 24/7.
Why It’s Niche & Powerful:
These models operate on the edge, processing high-frequency time-series or image data. They require robustness to noisy industrial environments and must deliver predictions with extreme reliability. The value is direct: preventing catastrophic downtime, reducing waste, and ensuring flawless product quality.
3. AI in Agriculture: From Precision Farming to Yield Optimization
Modern agriculture faces the immense challenge of feeding a growing population with limited resources. AI is becoming a key tool for sustainable intensification.
The Application:
By analyzing multispectral satellite or drone imagery, AI models can assess crop health at the individual plant level. They detect early signs of disease, nutrient deficiency, or water stress long before the human eye can see them. This enables variable-rate application: AI-guided machinery delivers the precise amount of water, fertilizer, or pesticide only where it’s needed. Furthermore, models integrate weather data, soil conditions, and historical yield maps to predict crop yields with remarkable accuracy, aiding harvest planning and supply chain logistics.
Why It’s Niche & Powerful:
This application combines computer vision with geospatial and environmental data analysis. The models must be tailored to specific crops, regions, and climates. The impact is profound: increasing yields while minimizing environmental footprint and input costs.
4. AI in Supply Chain & Logistics: Dynamic Optimization and Demand Forecasting
Global supply chains are complex, dynamic networks vulnerable to disruption. AI provides the intelligence to navigate this complexity.
The Application:
AI models power dynamic routing and logistics optimization. They process real-time data on traffic, weather, fuel costs, and delivery windows to continuously re-optimize delivery routes for fleets of vehicles. In warehouses, computer vision and robotics AI enable fully automated picking and packing. For demand forecasting, advanced models synthesize historical sales data, market trends, promotional calendars, and even social media sentiment to predict future product demand with much higher accuracy than traditional methods.
Why It’s Niche & Powerful:
These are optimization problems at a massive scale, often requiring a combination of reinforcement learning and combinatorial optimization. The AI doesn’t just predict; it prescribes the most efficient action in a constantly changing environment, directly translating to lower costs and higher service levels.
5. AI in Legal Tech & Compliance: Contract Analysis and Legal Research
The legal profession is built on documents—contracts, case law, regulations. AI is becoming an indispensable assistant for navigating this textual universe.
The Application:
Natural Language Processing (NLP) models specialized in legal language can review and analyze contracts in seconds, flagging non-standard clauses, potential liabilities, or obligations. For e-discovery in litigation, AI sifts through millions of emails and documents to find relevant evidence. Furthermore, AI-powered research tools can quickly surface pertinent case law or regulatory precedents, saving lawyers countless hours of manual review.
Why It’s Niche & Powerful:
This requires models fine-tuned on massive corpora of legal text to understand intricate jargon and context. The value isn’t in creativity but in precision, recall, and speed, drastically reducing risk and human labor in document-intensive processes.
6. AI in Meteorology & Climate Science: High-Resolution Weather and Climate Modeling
Predicting the weather and modeling climate change are among the most computationally challenging scientific problems.
The Application:
AI is now being used to create “digital twins” of the atmosphere. Machine learning models, particularly physics-informed neural networks, can analyze data from satellites, radar, and ground stations to make highly accurate, localized, short-term weather forecasts faster than traditional numerical weather prediction (NWP) models. For climate science, AI helps analyze complex climate model outputs, identify patterns of change, and even improve the parameterization of smaller-scale processes in larger global models.
Why It’s Niche & Powerful:
This sits at the intersection of AI and fundamental physics. The models must respect physical laws (conservation of energy, mass) while learning from data. The potential is vast: from giving farmers hyper-local rain forecasts to improving our long-term understanding of planetary systems.
The Common Challenge: Operationalizing Specialized AI
While the applications are diverse, they share a common hurdle: moving from a promising pilot to a reliable, scalable production system. These niche models require:
- Integration with proprietary industry data sources (lab systems, factory SCADA, satellite feeds).
- Specialized deployment environments (on-premise servers, edge devices in factories, secure cloud vaults).
- Continuous monitoring for performance decay as real-world data evolves.
This is where an integrated AI platform like WhaleFlux proves critical. WhaleFlux provides the unified foundation to build, deploy, and manage these specialized industry models. It can handle the diverse data pipelines, provide the tools for domain-specific fine-tuning, and ensure robust monitoring for model health and data drift—whether the model is predicting a bearing failure on a factory floor or analyzing a clause in a ten-thousand-page merger agreement. By abstracting away the infrastructure complexity, WhaleFlux allows domain experts and data scientists to focus on solving the unique problems of their field.
Conclusion
The future of AI’s economic impact lies not only in general-purpose conversational agents but profoundly in these deep, vertical applications. By moving “Beyond ChatGPT,” businesses are leveraging AI as a core tool for scientific discovery, operational excellence, and strategic decision-making in fields where specialized knowledge is paramount. The next wave of AI value will be generated by those who can successfully harness these powerful niche models and integrate them seamlessly into the heart of their industry’s workflows.
FAQs: Niche Industry Use Cases of AI Models
Q1: What’s the main difference between a general model like ChatGPT and these niche industry models?
General-purpose LLMs are trained on broad internet text to be conversational jack-of-all-trades. Niche industry models are typically specialized from the ground up or heavily fine-tuned on proprietary, domain-specific data (molecular structures, sensor logs, legal documents). They excel at a precise, high-stakes task but lack broad conversational ability. It’s the difference between a polymath and a world-leading specialist.
Q2: What are the biggest challenges in implementing such niche AI solutions?
The top challenges are: 1) Data Access & Quality: Acquiring enough high-quality, labeled domain-specific data. 2) Talent: Finding or developing teams that combine AI expertise with deep domain knowledge (e.g., a biochemist who understands ML). 3) Integration: Embedding the AI into existing, often legacy, industry software and hardware systems. 4) Trust & Regulation: Meeting stringent industry standards for validation, explainability, and compliance (especially in healthcare, finance, and law).
Q3: How does a platform like WhaleFlux help with these niche applications?
WhaleFlux addresses operational friction. It provides a unified environment to manage proprietary data for training, orchestrate the training/fine-tuning of specialized models on appropriate hardware, and deploy and monitor these models in their required environments (cloud, on-premise, edge). This allows cross-functional teams (domain experts + data scientists) to collaborate effectively and move from experiment to productionized asset faster.
Q4: Can small and medium-sized enterprises (SMEs) in these industries afford to develop such AI?
Yes, the barrier is lowering. Instead of building massive models from scratch, SMEs can often start with pre-trained, domain-adapted foundation models (e.g., a model pre-trained on scientific literature) and fine-tune them on their own smaller datasets. Cloud-based AI platforms and “AI-as-a-Service” offerings for specific tasks (like document analysis or predictive maintenance) are also making this technology more accessible and cost-effective for smaller players.
Q5: What is a key trend in the future of these niche AI applications?
The move towards “AI Scientists” or “AI Co-pilots.” We will see less of AI as a standalone tool and more as an integrated assistant that works alongside the human expert. In drug discovery, this might be an AI suggesting novel molecular pathways. For a lawyer, it could be an AI proactively highlighting risks in a contract draft based on recent case law. The integration will become deeper, more interactive, and more focused on augmenting human expertise.
AI Model Training Tools Showdown: TensorFlow vs. PyTorch vs. JAX – How to Choose?
As artificial intelligence continues its rapid ascent, the selection of a model training framework has evolved from a mere technical detail to a strategic cornerstone for any AI project. For developers and enterprises navigating this critical decision in 2025, the landscape is dominated by three powerful contenders: TensorFlow, PyTorch, and JAX. Each embodies a distinct philosophy, balancing flexibility, scalability, and performance. This guide cuts through the noise to provide a clear, actionable comparison, helping you match the right tool to your project’s unique blueprint.
The Contenders: Design Philosophies at a Glance
Understanding the core principles behind each framework is the first step to making an informed choice.
TensorFlow
TensorFlow, developed by Google, has long been synonymous with industrial-scale production. Its greatest strength lies in a robust, mature ecosystem built for stability and deployment. Tools like TensorFlow Extended (TFX) offer an L5 (autonomous driving level) maturity for production pipelines. While its initial static graph approach was seen as complex, the integration of Keras and eager execution mode have made it significantly more user-friendly. For teams that prioritize moving models reliably from research to a global serving environment, TensorFlow remains a powerhouse.
PyTorch
PyTorch, championed by Meta, won the hearts of researchers and developers with its intuitive, Pythonic design. Its use of dynamic computation graphs means the system builds the execution graph on the fly, allowing for unparalleled flexibility and easier debugging using standard Python tools. This “define-by-run” principle makes experimentation and prototyping exceptionally fast. The framework’s torch.compile feature and its seamless support for distributed data parallelism (DDP) have solidified its position as a top choice for everything from large language model (LLM) training to rapid innovation. Its vibrant community and extensive library of pre-built models further lower the barrier to entry.
JAX
JAX, also emerging from Google Research, represents a different paradigm. It is not a full-fledged neural network library but a scientific computing accelerator. Its genius lies in composable function transformations: you can write plain NumPy-like Python code, and then transform it for performance using Just-In-Time (JIT) compilation, automatic differentiation (grad), and vectorization (vmap). This makes JAX exceptionally fast and efficient, particularly on Google’s TPU hardware. However, it operates at a lower level; developers typically use it with high-level libraries like Flax (flexible, research-oriented) or Elegy (Keras-inspired). It is the preferred tool for algorithmic innovation and cutting-edge research where maximum computational efficiency is non-negotiable.
Head-to-Head Comparison: Finding Your Fit
The best framework depends heavily on your project’s stage, scale, and team expertise. The following table synthesizes key decision factors:
| Comparison Dimension | TensorFlow | PyTorch | JAX |
| Core Philosophy | Production & Deployment Stability | Research & Developer Flexibility | Scientific Computing & Max Performance |
| Learning Curve | Moderate (simplified by Keras) | Gentle, very Pythonic | Steep (requires understanding functional programming) |
| Execution Model | Static graph by default, dynamic available | Dynamic graph (eager execution) by default | Functional, transformations on pure functions |
| Distributed Training | Mature, via MirroredStrategy & parameter servers | Excellent, intuitive via DDP & FSDP | Powerful but manual, via pmap & pjit |
| Deployment | Exceptional (TFLite, TF Serving, TFX) | Good (TorchScript, TorchServe, ONNX) | Limited, often via other backends |
| Community & Ecosystem | Vast enterprise & production ecosystem | Largest research & academic community | Growing rapidly in advanced research circles |
| Ideal For | Enterprise ML pipelines, mobile/edge deployment, large-scale production systems | Academic research, prototyping, LLM training, computer vision | Novel algorithm development, physics/biology simulations, performance-critical research |
Beyond the Code: The Infrastructure Imperative
Choosing your framework is only half the battle. Deploying and managing the necessary computational resources presents its own set of challenges. Training modern AI models, especially LLMs, demands significant GPU power—from the versatile NVIDIA RTX 4090 for experimentation to the unparalleled scale of NVIDIA H100, H200, or A100 tensors for full-scale training. Managing a cluster of these expensive resources efficiently is critical to controlling costs and timelines.
Here, an integrated AI platform can be transformative. This is where a solution like WhaleFlux directly addresses a key pain point. WhaleFlux is an intelligent GPU resource management platform designed specifically for AI enterprises. It optimizes utilization across multi-GPU clusters, helping to significantly reduce cloud computing costs while accelerating the deployment speed and stability of large models. By providing a unified suite for GPU orchestration, AI service management, and observability, it allows teams to focus on model development rather than infrastructure wrangling. For organizations looking to leverage top-tier NVIDIA hardware (including the H100, H200, A100, and RTX 4090 series) without the complexity of managing discrete cloud instances, such platforms offer a compelling, streamlined path from training to deployment.
Making the Strategic Choice
Your final decision should align with your primary objective:
- Choose TensorFlow if: Your journey is a straight line from a stable model to a high-availability, global production system. You value a mature, integrated toolchain (TFX, TFLite) and require robust deployment options on servers, mobile, or the web.
- Choose PyTorch if: Your path is iterative, exploratory, and driven by rapid experimentation. You are in research, developing new architectures, or working extensively with transformers and LLMs. The joy of coding and a vast community of shared models and solutions are top priorities.
- Choose JAX (with Flax/Elegy) if: You are pushing the boundaries of what’s computationally possible. Your work involves creating new training algorithms, maximizing hardware efficiency (especially on TPUs), or working in scientific domains where gradients and optimizations are central to the research itself
Ultimately, there is no universal “best” framework. The most powerful choice is the one that best fits your team’s mindset, your project’s requirements, and your operational goals. By aligning the tool’s philosophy with your own, you set the stage for a more efficient and successful AI development journey.
FAQs
1. Q: As a beginner in deep learning, which framework should I start with?
A: PyTorch is generally the most recommended starting point for beginners. Its syntax is intuitive and Pythonic, its error messages are clearer, and its dynamic nature makes debugging easier. The massive community also means you’ll find an abundance of tutorials, courses, and help online.
2. Q: We need to train a very large model across hundreds of GPUs. Which framework is best?
A: Both PyTorch and TensorFlow offer excellent distributed training capabilities. PyTorch’s Fully Sharded Data Parallel (FSDP) is a popular choice for extremely large models. TensorFlow’s distributed strategies are incredibly robust for large-scale production training. The choice may then depend on your team’s expertise and the other factors in your pipeline.
3. Q: How does infrastructure management relate to framework choice?
A: While the framework handles the computation logic, platforms like WhaleFlix manage the underlying hardware (like NVIDIA H100/A100 clusters) that the framework runs on. They ensure efficient GPU utilization, handle scheduling, and provide observability tools. This separation allows developers to work with their preferred framework (TensorFlow, PyTorch, or JAX) while the platform optimizes cost and performance at the infrastructure layer.
4. Q: Can I use models trained in one framework with another?
A: Yes, interoperability is possible through open standards. The ONNX (Open Neural Network Exchange) format is the most common bridge, allowing you to train a model in PyTorch, for example, and potentially run inference in an environment optimized for TensorFlow or other runtimes.
5. Q: Is JAX going to replace TensorFlow or PyTorch?
A: It’s unlikely in the foreseeable future. JAX serves a different, more specialized niche focused on high-performance research and novel algorithms. TensorFlow and PyTorch provide fuller, more accessible ecosystems for the broad spectrum of development and production. They are complementary tools in the AI toolkit rather than direct replacements.
AI Model Trends: Lightweight, Multimodal, or Industry-Customized
The Great Fork in the Road
Imagine you’re a tech lead at a mid-sized company. Your CEO has greenlit a major AI initiative, convinced it’s the key to staying competitive. The directive is clear: “Build something intelligent and impactful.” But as you sit down to plan, you’re immediately faced with a foundational and perplexing choice. Should you:
- Adopt a state-of-the-art, massive multimodal model (MMM) that can chat, see, and reason, hoping its breathtaking generality sparks unexpected innovation?
- Develop a streamlined, lightweight model laser-focused on one specific task, promising speed, low cost, and easy deployment on your existing servers?
- Invest in creating or deeply fine-tuning a model exclusively for your industry’s jargon, regulations, and workflows, aiming to solve your most expensive problems that generic AI glosses over?
This isn’t just a technical selection; it’s a strategic bet on the future of your business. The AI landscape is no longer a one-way street toward bigger and bigger models. It has forked into three distinct, powerful pathways: the pursuit of Lightweight Efficiency, the ambition of Multimodal Mastery, and the depth of Industry-Customized Specialization. Each promises leadership, but in very different races. Which trend holds the key to real-world dominance?
Contender 1: The Agile Champion – Lightweight & Efficient Models
The “bigger is better” mantra in AI is facing a pragmatic challenger: the lightweight model. This trend isn’t about beating GPT-4 at a general knowledge test. It’s about winning where it matters most—in production.
The “Why” Behind the Shift: The drive for efficiency comes from the harsh economics of deployment. Running a 100-billion-parameter model in real-time requires immense computational power, typically from clusters of expensive GPUs like the NVIDIA H100, leading to high latency and unsustainable costs for high-volume applications. Lightweight models, often with parameters in the single-digit billions or even millions, flip this script.
The Engine of Efficiency: This is achieved through a sophisticated toolbox:
- Architectural Innovation: New model architectures like Microsoft’s Phi-2 or Google’s Gemmaare designed from the ground up to do more with less, using smarter attention mechanisms and denser parameter utilization.
- Model Compression: Techniques like quantization (reducing numerical precision from 32-bit to 8-bit or 4-bit), pruning (removing non-essential neurons), and knowledge distillation (training a small model to mimic a large one) can shrink model size by 4x or more with minimal accuracy loss.
- Hardware Synergy: These compact models are perfect partners for cost-effective inference on less powerful, widely available hardware, such as a single NVIDIA RTX 4090 for on-premises deployment or even on mobile and edge devices.
Leadership Claim: Lightweight models lead the race to ubiquity and practicality. They are the trend that brings AI from the cloud to the daily workflows—powering real-time translation on phones, instant product recommendations on websites, and fast, private data analysis on company servers without exorbitant cloud bills.
Contender 2: The Universal Genius – Multimodal Models
If lightweight models are specialists, multimodal models are the polymaths. They aim to break down the walls between data types, creating a single AI that can seamlessly understand and generate text, images, audio, and video.
Beyond Simple Combination:
Early “multimodal” systems were often pipelines—an image classifier feeding text to a language model. Modern MMMs like GPT-4V or Google’s Gemini are fundamentally unified. They are trained on massive, interleaved datasets of text, images, and code, allowing them to develop a deeply interconnected understanding. An image isn’t just labeled; its elements, style, and implied meaning are woven into the model’s reasoning fabric.
The Power of a Unified World View:
This creates astonishing, human-like capabilities. You can ask it to write a marketing slogan based on a product sketch, analyze a scientific chart and summarize the findings, or find an emotional moment in a video based on a voice description. The potential for creative assistants, revolutionary search interfaces, and complex problem-solving is immense.
The Cost of Genius:
However, this capability comes at a staggering cost. Training these unified models requires unprecedented computational scale—think tens of thousands of NVIDIA H100 or H200 GPUs running for months. Furthermore, their very generality can be a weakness for businesses. A model that knows a little about everything might not know enough about your specific industry’s nuances, leading to plausible but incorrect or generic outputs for specialized tasks.
Leadership Claim:
Multimodal models lead the race for raw capability and user experience innovation. They are contenders for the ultimate human-machine interface, potentially becoming the primary way we interact with all digital systems.
Contender 3: The Deep Expert – Industry-Customized Models
This trend asks a simple, powerful question: What good is a genius if it doesn’t understand your business? Industry-customized models are the domain experts, trained or meticulously fine-tuned on proprietary data—legal contracts, medical journals, engineering schematics, financial reports.
From General Knowledge to Operational Intelligence: These models move beyond answering general questions to performing high-stakes, domain-specific tasks. Think of a model that reads thousands of clinical trial reports to suggest potential drug interactions, or one that analyzes decades of supply chain and geopolitical data to predict procurement risks for a manufacturer.
The Path to Specialization: Customization happens in several ways:
- Continued Pre-training: Further training a base model (like Llama 2) on a vast corpus of domain-specific text.
- Supervised Fine-Tuning (SFT): Training the model on labeled examples of specific tasks (e.g., “label this radiograph”).
- Retrieval-Augmented Generation (RAG): Connecting a model to a live, vectorized database of company knowledge, ensuring its answers are grounded in internal docs and latest data.
The infrastructure for such specialization is critical. Developing and iterating on these custom models requires flexible, high-performance computing that doesn’t break the bank. This is where platforms architected for efficiency show their value. For instance, WhaleFlux provides an integrated AI service platform that supports this entire customization journey. Beyond offering optimized access to the full spectrum of NVIDIA GPUs (from H100 for heavy training to RTX 4090s for cost-effective development), its unified environment for GPU management, model serving, and AI observability allows enterprise teams to focus on fine-tuning their proprietary data and workflows. By maximizing cluster utilization and providing stable deployment, it turns the high-compute task of building a domain expert into a manageable and predictable operational process.
Leadership Claim: Industry-customized models lead the race for tangible ROI and competitive advantage. They don’t just automate tasks; they encapsulate and scale a company’s unique intellectual property, directly impacting the bottom line by solving problems no off-the-shelf model can.
The Verdict: A Trifecta, Not a Winner-Takes-All
So, who will lead? The answer is not one, but all three—in different arenas.
The future belongs to strategic layering. The winning enterprise architecture will likely integrate elements from each trend:
- A lightweight, efficient model deployed at the edge to handle high-frequency, low-latency tasks (e.g., customer service chat filtering).
- A powerful multimodal model in the cloud as a creative and research co-pilot for employees, analyzing presentations and brainstorming.
- A deeply customized, domain-specific model serving as the core operational brain, powering critical applications like risk assessment, diagnostic support, or legal discovery.
Lightweight models will lead in pervasiveness and accessibility. Multimodal models will lead in consumer-facing and creative applications. Industry-customized models will lead in transforming core business operations and building unassailable moats.
The true leaders won’t be the models themselves, but the organizations that most skillfully navigate this trifecta. They will be the ones who ask not “Which trend should we follow?” but “How can we orchestrate these powerful forces to solve our most meaningful problems?” The race is on, and the most intelligent strategy may be to build a team that can run in all three directions at once.
FAQs: AI Model Trends
1. Is the trend toward lightweight models just because companies can’t afford larger ones?
Not at all. While cost is a major driver (making AI viable for more use cases), the shift is fundamentally about right-sizing. Lightweight models offer superior speed, lower latency, the ability to run on-device for privacy, and dramatically reduced energy consumption. It’s about applying the appropriate amount of intelligence for the task, not settling for less.
2. Can a multimodal model replace the need for specialized, industry-customized models?
Unlikely in the near term. While multimodal models are incredibly versatile, they are generalists. An industry-customized model trained on proprietary data develops a depth of understanding and reliability on niche tasks that a generalist cannot match. Think of it as the difference between a brilliant medical student (multimodal) and a seasoned specialist with 20 years of experience (customized). For high-stakes business applications, depth and precision are non-negotiable.
3. What’s the biggest infrastructure challenge in pursuing industry-customized AI?
The challenge is two-fold: computational cost and operational complexity. Fine-tuning and continuously improving custom models require significant, repeated GPU compute cycles (on hardware like NVIDIA A100 or H100 clusters). Managing this infrastructure, ensuring high utilization to control costs, and maintaining stable deployment pipelines is a massive undertaking. This is precisely why integrated platforms that handle this complexity are becoming essential for enterprise AI teams.
4. How does a platform like WhaleFlux support a company exploring multiple AI trends?
WhaleFlux acts as a flexible, unified foundation for AI development and deployment. For lightweight models, its efficient GPU management allows for cost-effective inference scaling. For developing customized models, it provides the high-performance NVIDIA GPU resources (like H100s for training) and the observability tools needed for iterative fine-tuning. Its integrated environment for models and agents helps teams manage this entire portfolio from experimentation to production, optimizing resource use across different types of AI workloads and preventing infrastructure from becoming a bottleneck to innovation.
5. As a business leader, how should I prioritize investment among these three trends?
Start with the problem, not the technology. Map your key business challenges to the trend’s strength:
- Invest in Lightweight AI for customer-facing apps needing speed/scale (e.g., recommendation engines).
- Invest in Multimodal AI for enhancing creativity, internal research, or building next-gen user interfaces.
- Invest in Industry-Customized AI for automating core, proprietary processes (e.g., contract analysis, predictive maintenance, diagnostic support). Most companies will find the highest initial ROI in a focused, customized model project that tackles a known, expensive problem.
AI Model Deployment Demystified: A Practical Guide from Cloud to Edge
Deploying an AI model from a promising prototype to a robust, real-world application is a critical yet complex journey. The landscape of deployment options has expanded dramatically, leaving many teams facing a crucial question: where and how should our models live in production? The choice isn’t just technical; it directly impacts your application’s performance, cost, reliability, and ability to scale.
This guide cuts through the complexity by comparing the three mainstream deployment paradigms: Public Cloud Services, On-Premises/Private Cloud, and Edge Computing. We’ll explore the core logic, ideal use cases, and practical trade-offs of each to help you build a deployment strategy that aligns with your business goals.
The Core Deployment Trinity: Understanding Your Options
The modern AI deployment ecosystem is broadly divided into three domains, each governed by a different philosophy about where computation and data should reside.
1. Public Cloud AI Services: The Power of Elasticity
Cloud AI platforms, such as AWS SageMaker, Azure Machine Learning, and Google Cloud Vertex AI, offer a managed, service-centric approach. Their primary advantage is elastic scalability, allowing you to deploy a model on a single GPU instance and scale out to a multi-node cluster within minutes to handle increased load. This model eliminates massive upfront capital expenditure (CapEx) on hardware, converting it into a predictable operational expense (OpEx).
Cloud platforms are ideal for scenarios requiring rapid iteration, variable workloads, or global reach. They provide integrated MLOps toolchains that can significantly reduce operational overhead. However, organizations must be mindful of potential pitfalls like egress costs for large data transfers, “cold start” latency for infrequently used services, and the long-term cost implications of sustained, high-volume inference.
2. On-Premises & Private Cloud: The Command of Control
For many enterprises, especially in regulated industries like finance, healthcare, or government, maintaining direct control over data and infrastructure is non-negotiable. On-premises deployment involves hosting models on company-owned hardware, typically within a private data center or cloud (like an NVIDIA DGX pod). This approach offers the highest degree of data sovereignty, security, and network control.
The primary challenge shifts from operational agility to infrastructure management. Teams must procure, maintain, and optimize expensive GPU resources (such as clusters of NVIDIA H100 or A100 GPUs) and handle the full software stack. The initial investment is high, and maximizing the utilization of this fixed, finite resource pool becomes a critical engineering task to ensure a positive return on investment. This is precisely where intelligent orchestration platforms add immense value.
For enterprises navigating the complexity of private GPU clusters, a platform like WhaleFlux provides a critical advantage. WhaleFlux is an intelligent GPU resource management and AI service platform designed to tackle the core challenges of on-premises and private cloud AI. It goes beyond simple provisioning to optimize the utilization efficiency of multi-GPU clusters, directly helping businesses lower cloud computing costs while enhancing the deployment speed and stability of large models. By integrating GPU management, AI model serving, Agent frameworks, and full-stack observability into one platform, WhaleFlux allows teams to focus on innovation rather than infrastructure mechanics. It provides access to a full spectrum of NVIDIA GPUs, from the powerful H100 and H200 for massive training to the versatile A100 and RTX 4090 for inference and development, available through purchase or monthly rental to ensure cost predictability.
3. Edge AI: Intelligence at the Source
Edge AI represents a paradigm shift by running models directly on devices at the “edge” of the network—such as smartphones, IoT sensors, industrial PCs, or dedicated appliances like the NVIDIA Jetson. This architecture processes data locally, where it is generated, rather than sending it to a central cloud.
The benefits are transformative for specific applications: ultra-low latency for real-time decision-making (e.g., autonomous vehicle navigation), enhanced data privacy as sensitive information never leaves the device, operational resilience in connectivity-challenged environments, and bandwidth cost reduction. The trade-off is working within the strict computational, power, and thermal constraints of the edge device, often requiring specialized model optimization techniques like quantization and pruning.
Choosing Your Path: A Strategic Decision Framework
Selecting the right deployment target is not about finding the “best” option in a vacuum, but the most fit-for-purpose solution for your specific scenario. Consider these key dimensions:
- Latency & Responsiveness: Does your application require real-time feedback (e.g., fraud detection, interactive voice)? Edge or cloud-edge hybrid models are strong candidates. Batch processing or asynchronous tasks are well-suited for cloud or on-premises.
- Data Gravity & Compliance: Is your data highly sensitive, bound by strict regulations (GDPR, HIPAA), or simply too massive to move economically? This strongly favors on-premises or edge solutions.
- Cost Structure & Scale: Do you have predictable, steady-state workloads or spiky, unpredictable traffic? The former can justify on-premises investment for better long-term value, while the latter benefits from cloud elasticity.
- Operational Expertise: Do you have a team to manage servers, GPUs, and orchestration software? If not, the managed experience of cloud services or an integrated platform like WhaleFlux is crucial.
The Future: Hybrid Architectures and Optimized Inference
The most sophisticated production systems rarely rely on a single paradigm. The future lies in hybrid architectures that intelligently distribute workloads. A common pattern uses the public cloud for large-scale model training and retraining, a private cluster for hosting core, latency-sensitive inference services, and edge devices for ultra-responsive, localized tasks.
Furthermore, the industry’s focus is intensifying on inference optimization—the art of serving models faster, cheaper, and more efficiently. Advanced techniques like Prefill-Decode (PD) separation—which splits the compute-intensive and memory-intensive phases of LLM inference across optimized hardware—are delivering dramatic throughput improvements. Innovations in continuous batching, attention mechanism optimization (like MLA), and efficient scheduling are pushing the boundaries of what’s possible, making powerful AI applications more viable and sustainable.
Conclusion
There is no universal answer to AI model deployment. Cloud services offer speed and scalability, on-premises provides control and security, and edge computing enables real-time, private intelligence. The winning strategy involves a clear-eyed assessment of your technical requirements, business constraints, and strategic goals.
By understanding the core principles and trade-offs of these three mainstream solutions, you can design a deployment architecture that not only serves your models but also empowers your business to innovate reliably and efficiently. Start by mapping your key application requirements against the strengths of each paradigm, and don’t be afraid to embrace a hybrid future that leverages the best of all worlds.
FAQs: AI Model Deployment
1. What are the most critical factors to consider when deciding between cloud and on-premises deployment for an LLM?
Focus on four pillars: Data & Compliance (sensitivity and regulatory constraints), Performance Needs (latency SLA and throughput), Total Cost of Ownership (comparing cloud OpEx with on-premises CapEx and operational overhead), and Operational Model (in-house DevOps expertise). For example, a high-traffic, public-facing chatbot might suit the cloud, while a proprietary financial model trained on confidential data would mandate a private, on-premises cluster.
2. Our edge AI application needs to work offline. What are the key technical challenges?
Offline edge AI must overcome: Limited Resources (fitting the model into constrained device memory and compute power, often requiring heavy quantization), Energy Efficiency (maximizing operations per watt for battery-powered devices), and Independent Operation (handling all pre/post-processing and decision logic locally without cloud fallback). Success depends on meticulous model compression and choosing hardware with dedicated AI accelerators.
3. What is “inference optimization,” and why has it become so important for business viability?
Inference optimization is the suite of techniques (like model quantization, speculative decoding, and advanced serving architectures) aimed at making running trained models faster, cheaper, and more efficient. It’s critical because for most businesses, the ongoing cost and performance of serving a model (inference) far outweigh the one-time cost of training it. Effective optimization can reduce server costs by multiples and improve user experience through lower latency, directly impacting ROI and application feasibility.
4. How does a platform like WhaleFlux specifically help with the challenges of on-premises AI deployment?
WhaleFlux addresses the core pain points of private AI infrastructure: Cost Control by maximizing the utilization of expensive NVIDIA GPU clusters (like H100/A100), turning idle time into productive work; Operational Complexity by providing an integrated platform for GPU management, model serving, and observability, reducing the need for disparate tools; and Performance Stabilitythrough intelligent scheduling and monitoring that ensures reliable model performance. Its monthly rental option also provides a predictable cost alternative to large upfront hardware purchases.
5. We have variable traffic. Is a hybrid cloud/on-premises deployment possible?
Absolutely, and it’s often the most robust strategy. A common hybrid pattern is to use your on-premises or private cloud cluster (managed by a platform like WhaleFlux for efficiency) to handle baseline, predictable traffic, ensuring data sovereignty and low latency. Then, configure an auto-scaling cloud deployment to act as a “overflow” capacity during unexpected traffic spikes. This approach balances control, cost, and elasticity, though it requires careful design for load balancing and data synchronization between environments.
Double Your AI Model Inference Speed! 5 Low-Cost Optimization Hacks
You’ve deployed your AI model. It’s accurate, it’s live, but it’s… slow. User complaints trickle in about latency. Your cloud bill is creeping up because your instances are struggling to keep up with demand. You’re caught in the classic trap: the model that was a champion in training is a laggard in production.
The good news? You likely don’t need a bigger GPU or a complete rewrite. Significant performance gains—often 2x or more—are hiding in plain sight, achievable through software optimizations and smarter configurations. These are the “low-hanging fruit” of inference optimization. Let’s dive into five practical, cost-effective hacks to dramatically speed up your model.
Why Speed Matters (Beyond Impatience)
Before we start optimizing, let’s frame the why. Inference speed directly impacts:
- User Experience: A 100ms delay can feel instant; a 2-second delay feels broken.
- Cost: Faster inference = more requests processed per server = fewer servers needed.
- Scalability: Your system can handle traffic spikes without collapsing.
- Feasibility: Real-time applications (voice assistants, live video analysis) are impossible without low-latency inference.
Optimization is the art of removing computational waste. Here’s where to find it.
Hack #1: Model Quantization (The Biggest Bang for Your Buck)
The Concept: Do you need 32 decimal points of precision for every single calculation? Probably not. Quantization reduces the numerical precision of your model’s weights and activations. The most common jump is from 32-bit floating point (FP32) to 16-bit (FP16) or even 8-bit integers (INT8).
The Speed-Up: This is a triple win:
- Smaller Model Size: An INT8 model is ~75% smaller than its FP32 version. This speeds up model loading and reduces memory bandwidth pressure.
- Faster Computation: Modern CPUs and GPUs have specialized instructions (like NVIDIA Tensor Cores for INT8/FP16) that can perform many more low-precision operations per second.
- Reduced Memory Footprint: You can fit larger batch sizes or run on cheaper, memory-constrained hardware (like edge devices).
How to Implement:
- FP16: Often a safe, first-step “free lunch.” In PyTorch, it’s as simple as
model.half(). TensorFlow has similar automatic mixed-precision tools. Expect a 1.5x to 3x speedup on compatible GPUs with negligible accuracy loss. - INT8: Requires “calibration”—running a small representative dataset through the model to determine the optimal scaling factors for conversion. Use frameworks like TensorRT (NVIDIA) or ONNX Runtime which handle this process. This can yield a 2x to 4x speedup but requires careful validation to ensure accuracy stays within acceptable bounds.
Pitfall: Don’t quantize blindly. Always validate accuracy on your test set after quantization.
Hack #2: Graph Optimization & Kernel Fusion
The Concept: High-level frameworks like PyTorch and TensorFlow are great for flexibility, but they execute operations (“kernels”) one by one. Each kernel call has overhead. Graph optimizersanalyze the entire model’s computational graph and perform surgery: they fuse small, sequential operations into single, larger kernels, and eliminate redundant calculations.
The Speed-Up: By minimizing kernel launch overhead and maximizing hardware utilization, these optimizations can yield a 20-50% improvement with zero change to your model’s accuracy or architecture.
How to Implement:
Use an Optimized Runtime:
Don’t serve with pure PyTorch or TensorFlow. Convert your model and run it through:
- ONNX Runtime: Pass your model through its graph optimizations (
GraphOptimizationLevel.ORT_ENABLE_ALL). - TensorRT: NVIDIA’s powerhouse. It fuses layers, selects optimal kernels for your specific GPU, and is a key part of the quantization pipeline.
- OpenVINO: Excellent for Intel CPUs and integrated graphics.
The Process:
Train Model (PyTorch/TF) -> Export to Intermediate Format (e.g., ONNX) -> Optimize with Runtime -> Deploy Optimized Engine. This extra step in your pipeline is non-negotiable for performance.
Hack #3: Dynamic Batching (The Secret Weapon of Servers)
The Problem:
Processing requests one-by-one (online inference) is terribly inefficient for parallel hardware like GPUs. The GPU sits mostly idle, waiting for data transfers.
The Solution: Batching.
Group multiple incoming requests together and process them in a single forward pass. This amortizes the fixed overhead across many inputs, dramatically improving GPU utilization and throughput.
The Hack: Dynamic Batching.
Instead of waiting for a fixed batch size (which harms latency), a smart inference server implements dynamic batching. It collects incoming requests in a queue for a predefined, very short time window (e.g., 10ms). When the window ends or the queue hits a limit, it sends the entire batch to the model.
The Speed-Up:
For a moderately sized model, going from batch size 1 to 8 or 16 can improve throughput by 5-10x with only a minor latency penalty for the first request in the batch.
How to Implement:
Use a serving solution with built-in dynamic batching:
- NVIDIA Triton Inference Server: A industry-standard with excellent dynamic batching, auto-scaling, and multi-framework support.
- TensorFlow Serving / TorchServe: Have basic batching capabilities.
- Managed Platforms: Many cloud AI platforms implement this automatically under the hood.
Hack #4: Choose the Right Hardware (It’s Not Always a GPU)
The Misconception:
“GPUs are always faster for AI.” Not necessarily for inference.
The Hack:
Profile and match your workload.
- High-Throughput, Batched, Large Models (NLP/Vision): A GPU (especially with Tensor Cores) is king. Look for inference-optimized cards like the NVIDIA T4 or A10G.
- Low/Medium Throughput, Latency-Sensitive, Small Models: A modern CPU (with AVX-512 instructions) can be surprisingly competitive and much cheaper per instance. Often good for classic ML models (scikit-learn, XGBoost).
- Predictable, High-Volume, Fixed Models: Consider specialized AI accelerators like AWS Inferentia or Google TPU. They can offer the best price/performance for their specific use case.
- The Edge (Phones, Cameras): Use dedicated edge NPUs or frameworks like TensorFlow Lite that perform model quantization and optimization for mobile CPUs.
Action Step:
Run a benchmark! Deploy your optimized (quantized) model on 2-3 different instance types (CPU, mid-tier GPU, inferentia) and compare cost per 1000 inferences. The winner might surprise you.
Hack #5: Implement Prediction Caching
The Concept: Are you making the same prediction over and over? Many applications have repetitive requests. A user might reload a page, or a sensor might send near-identical data frequently.
The Hack: Cache the result. Implement a fast, in-memory cache (like Redis or Memcached) in front of your inference service. Before calling the model, compute a hash of the input features. If the hash exists in the cache, return the cached prediction instantly.
The Speed-Up: This can reduce latency to sub-millisecond levels for repeated requests and slash your model’s computational load, directly reducing cost.
When to Use: Ideal for:
- Recommendation systems with stable user profiles.
- APIs where input parameters change slowly.
- Any application with significant request redundancy.
Managing these optimizations—quantization scripts, Triton configurations, caching layers, and performance benchmarks—can quickly become a complex choreography of tools. This operational overhead is where an integrated platform shines. A platform like Whaleflux can automate much of this optimization pipeline. It can manage the conversion and quantization of models, deploy them with automatically configured dynamic batching on the right hardware, and provide built-in monitoring and caching patterns. This allows engineering teams to focus on applying these hacks rather than building and maintaining the plumbing that connects them.
Putting It All Together: Your Optimization Checklist
- Profile First: Use tools like PyTorch Profiler or NVIDIA Nsight Systems to find your bottleneck (is it data loading, CPU pre-processing, or the GPU model execution?).
- Quantize: Start with FP16, experiment with INT8 after validation.
- Optimize the Graph: Run your model through ONNX Runtime or TensorRT.
- Batch Dynamically: Deploy with a server that supports it (e.g., Triton).
- Right-Size Hardware: Benchmark on CPU vs. GPU vs. accelerator based on your cost-per-inference target.
- Cache When Possible: Add a Redis layer for repetitive queries.
Start with one hack, measure the improvement, then move to the next. A 1.5x gain from quantization, plus a 2x gain from batching, and a 1.3x gain from graph optimizations can easily combine to a 4x total speedup—doubling your speed twice over. No new algorithms, no loss in accuracy, just smarter engineering. Go make your model fly.
FAQs
1. Won’t quantization (especially INT8) ruin my model’s accuracy?
It can, which is why validation is critical. The accuracy drop is often minimal (<1%) for many vision and NLP models, as neural networks are inherently robust to noise. The key is “calibration” using a representative dataset. Always measure accuracy on your test set post-quantization. FP16 quantization rarely hurts accuracy.
2. Is dynamic batching suitable for real-time, interactive applications?
Yes, if configured correctly. The trick is in the dynamic timeout. Set a very short maximum wait time (e.g., 2-10ms). This means the first request in a batch might wait a few milliseconds for companions, but the dramatic increase in throughput keeps the overall system responsive even under load, preventing queue backlogs that cause much worse latency spikes.
3. How do I know if my model is “CPU-friendly” or needs a GPU?
As a rule of thumb: small models (under ~50MB parameter size, simple architectures), models with low operational intensity (like many classic ML models), and workloads with low batch size requirements are often CPU-competitive. Large transformers (BERT, GPT), big CNNs (ResNet50+), and high-throughput batch processing almost always require a GPU or accelerator. The definitive answer comes from benchmarking.
4. What’s the first optimization I should try?
Model Quantization to FP16 is almost always the safest and easiest first step. It’s often a single line of code change, requires no new infrastructure, and provides an immediate, significant speedup on modern GPUs with virtually no downside.
5. Do these optimizations work for any model framework?
The principles are universal, but the tools vary. Quantization and graph optimization are supported for all major frameworks (PyTorch, TensorFlow, JAX) via intermediary formats like ONNX or framework-specific runtimes (TensorRT, OpenVINO). Dynamic batching is a feature of the serving system (like Triton), not the model itself, so it works regardless of how the model was trained.