WhaleFlux
使いやすく、オープンなフルスタック統合型インフラで、高性能な AI モデルの導入
と管理を支援します。
WhaleFlux は AI ワークロードに最適なパ
フォーマンスを提供します

WhaleFlux が AI モデル サービ
スをどのようにサポートするか
インテリジェントなコンピューティングリソース管理
WhaleFlux は、独自のテスト、きめ細かなリソース管理、柔軟な構成を備えた高性能 GPU を提供し、単一の GPU またはクラスター、短期的または長期的に安定した効率的な運用を実現します。
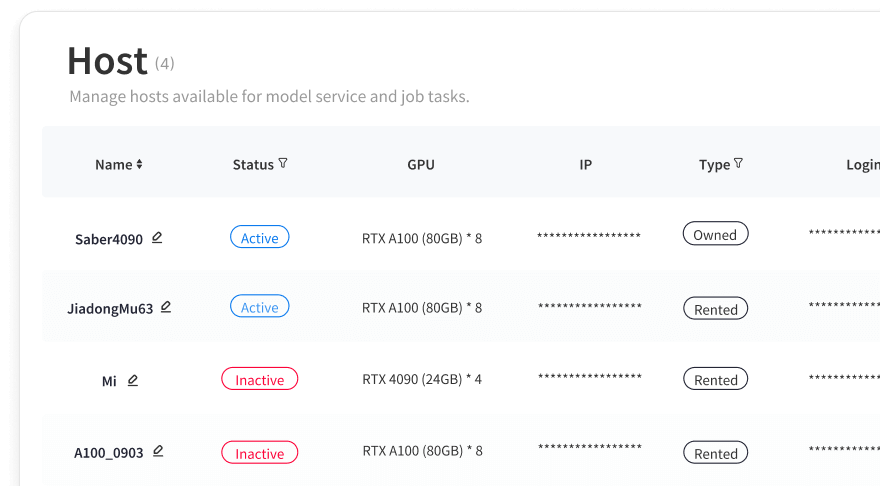
モデル開発センター
WhaleFlux のシームレスなワークフローで開発プロセスを簡素化します。ユーザーは複雑な構成なしでテンプレートベースの環境をすばやく作成し、イメージとファイルシステムを簡単に管理できます。
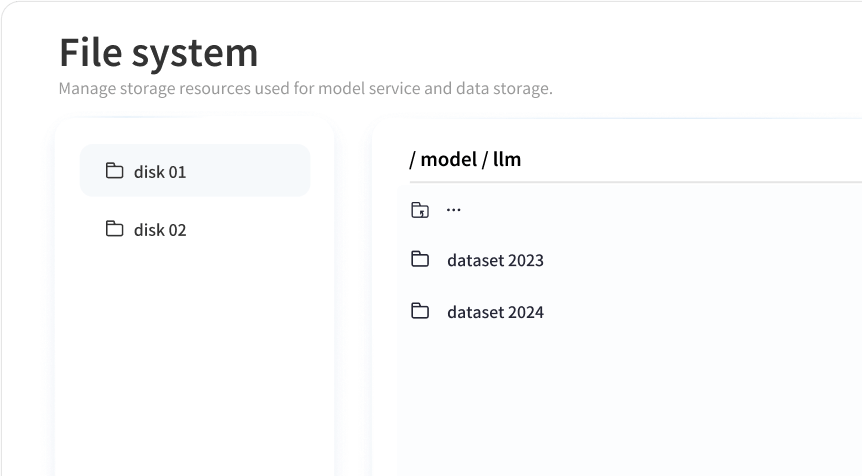
スマートな展開とスケジュール
WhaleFlux は、AI モデルの迅速な展開とスマートなスケジューリングを可能にし、シームレスな操作と微調整のための自動戦略調整によりパフォーマンスを最適化します。
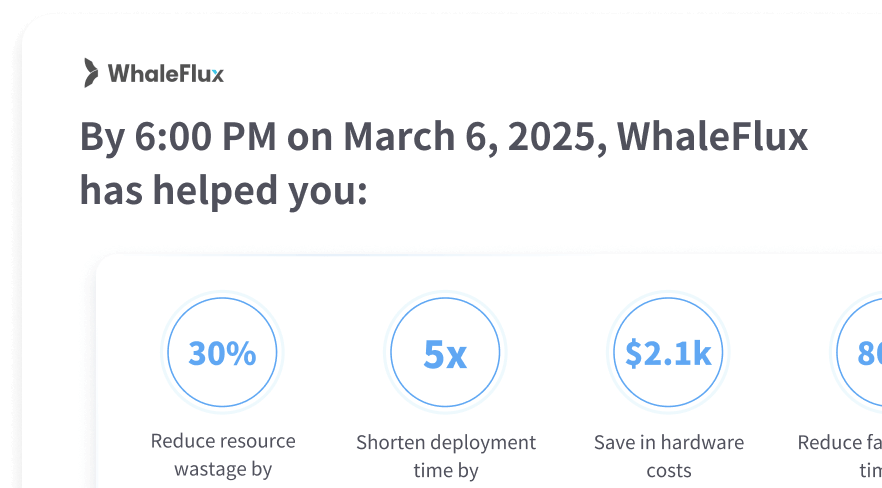
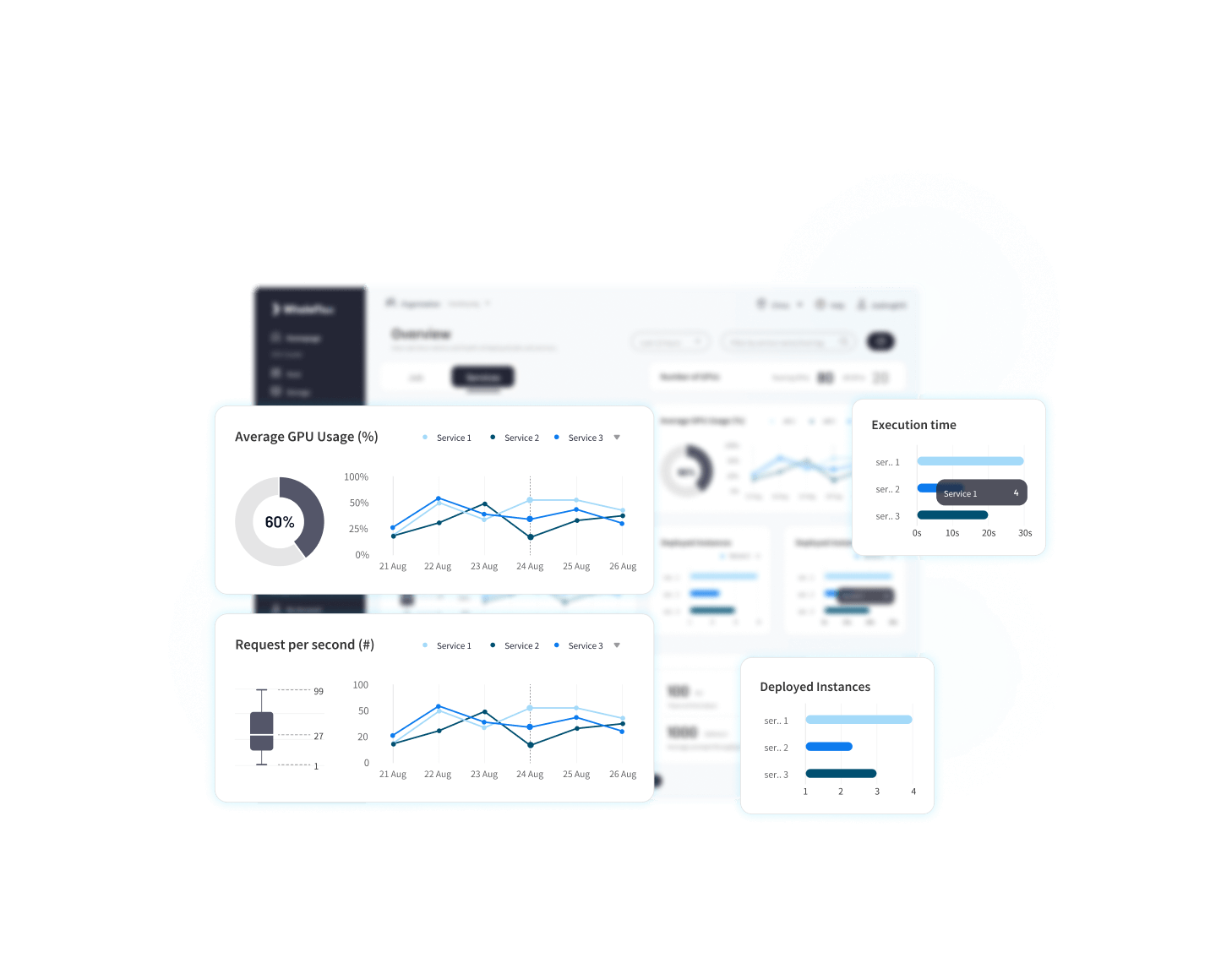
フルスタックパフォーマンスモニタリング
WhaleFlux のグローバル トポロジを使用して、リソースとサービス操作の包括的なビューを取得します。ハードウェア パフォーマンス、サービスの健全性、ゲートウェイの実行をカバーする 30 を超える多次元メトリックを監視し、すべてのレベルでリアルタイムの可視性を確保します。
WhaleFluxの最先端技術でAIモデ
ルサービスを強化
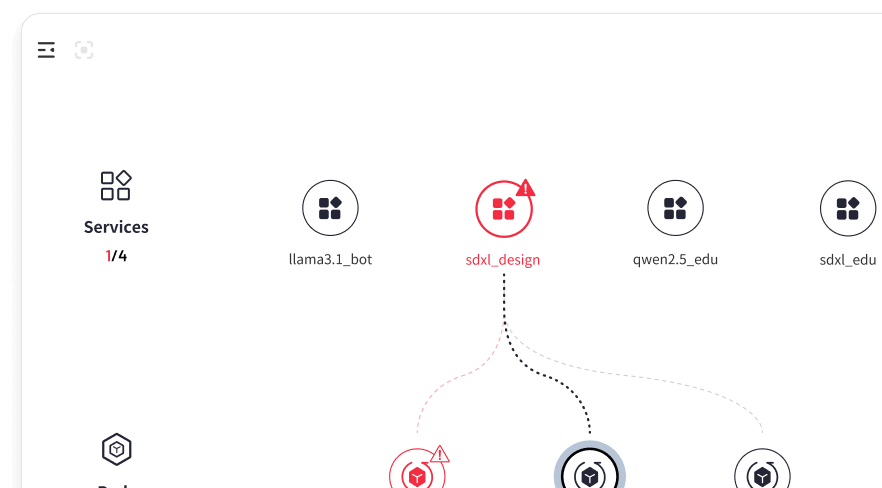
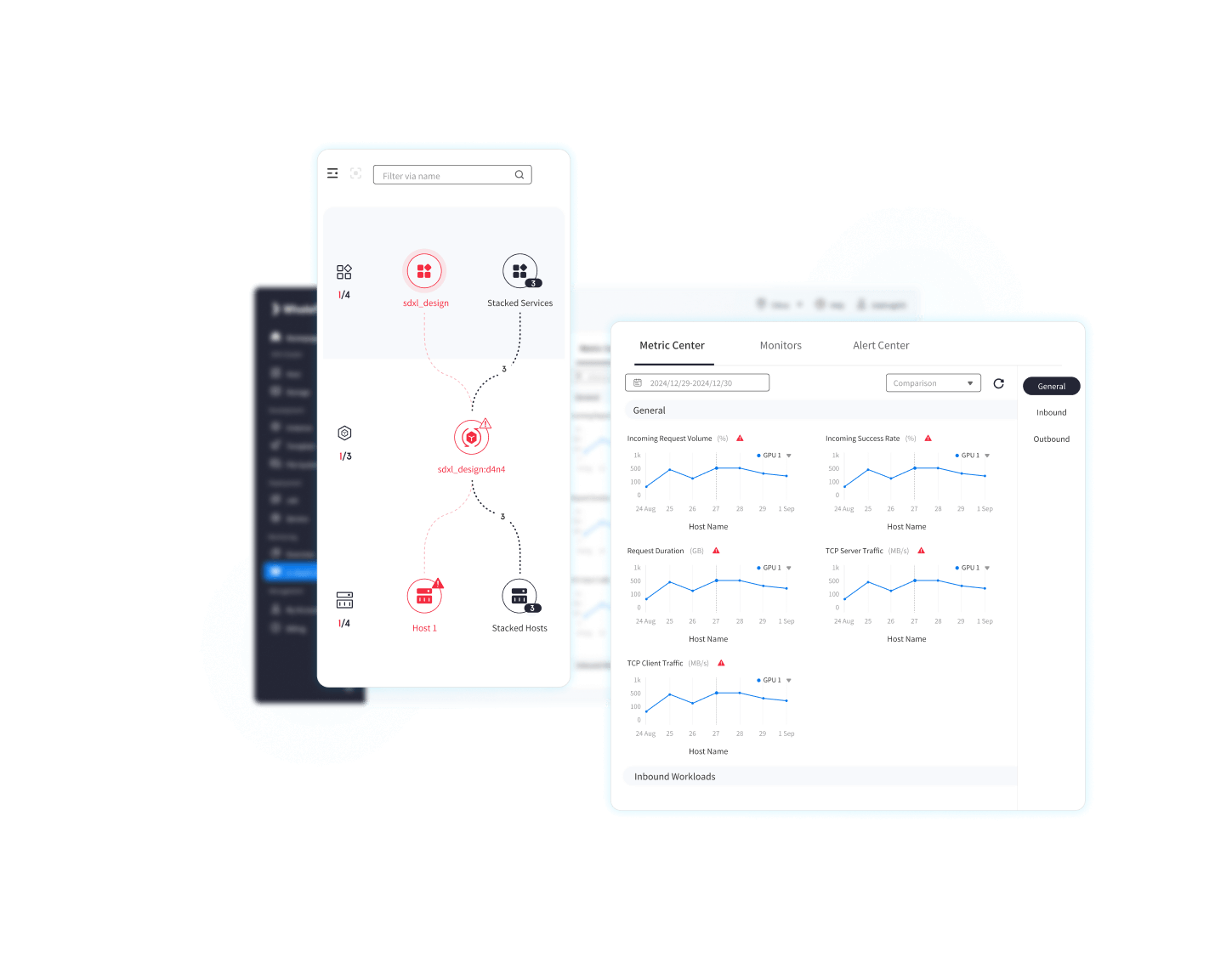
01 スレッドレベルの可観測性
AIモデルアプリケーションのフルスタックに関する深い洞察を提供することで、パフォーマンスのボトルネックを突き止めます。
GPU クラスター、LLM、アプリケーション全体にわたる包括的なスレッドレベルの可視性を提供します。
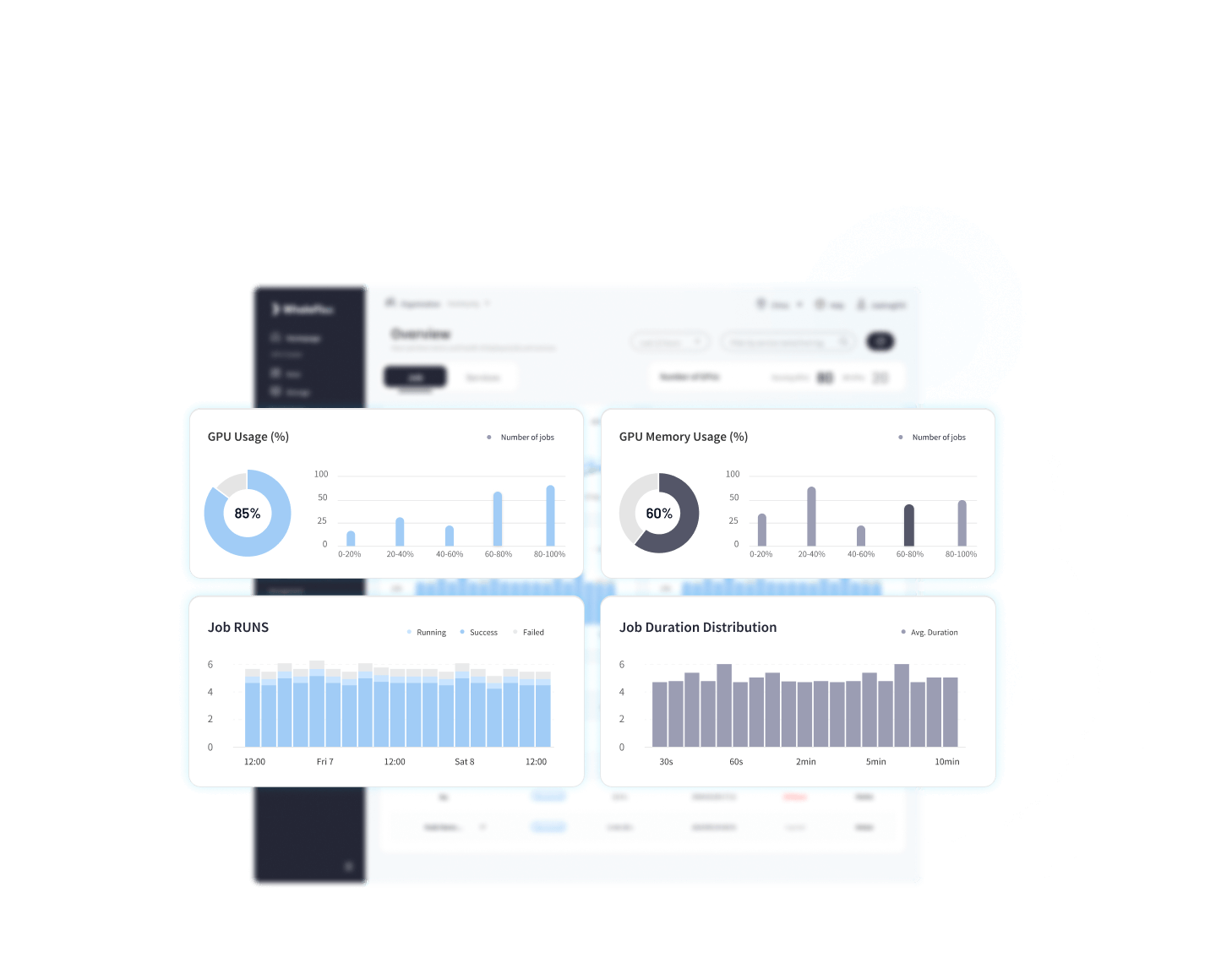
30以上の独自の観測性主要指標
潜在的なリスクを予測し、迅速に解決するための監視、警告、自己修復、最適化のための AI 搭載システム
02
ワークロード/GPU プロファイリング
およびアフィニティ分析
インテリジェントなリソース割り当てでAIパフォーマンスを最適化
ワークロードプロファイリング: コンピューティングの負荷、メモリ使用量、GPU 機能を分析します
ダイナミックマッチング: ワークロードを最適なGPUに調整して効率化を図る
タスクの最適化: GPU のパフォーマンスとメモリのニーズに基づいてタスクを割り当てます
データの局所性: データソースの近くにタスクを配置することで転送を削減
リソースの分離: 競合を回避し、重要なタスクにGPUを割り当てる
03 アトミックレベルのスケジューリング
最高のパフォーマンスを得るために計算リソースの利用を最適化する
コンピューティングリソースの綿密な管理
高同時リクエストシナリオ向けのリアルタイムリソーススケジューリング
電力コストを最小限に抑える最適なリソーススケジューリング